Business Continuity (BC) e Disaster Recovery (DR): decisioni automatiche o decisioni umane?
Questo secondo articolo sui temi di Business Continuity (BC) e Disaster Recovery (DR) si concentra su quale procedura eseguire per spostare i servizi da un sito principale ad un sito secondario e, specificamente, se la decisione deve essere umana o automatica.
Normalmente si è portati a pensare che un sito di Business Continuity debba essere garantito da decisioni automatiche mentre, se si parla di Disaster Recovery, la decisione debba essere demandata ad una decisione umana spesso costituita da un comitato di disastro che decide il da farsi.
In realtà, non sono i termini BC o DR a determinare una decisione automatica o umana ma la tipologia di servizio che dobbiamo proteggere nell’operatività.
Nel precedente articolo su questo tema abbiamo parlato di quando utilizzare BC o DR e ci siamo soffermati sulla tipologia del servizio per capire se abbiamo bisogno di Business Continuity o Disaster Recovery.
L’esempio menzionato metteva a confronto un servizio di pronto soccorso, il quale ha bisogno di BC, rispetto ad un sevizio di logistica che ha bisogno sicuramente di una infrastruttura di DR ed eventualmente anche di una infrastruttura di BC sulla base di un’analisi costi e benefici (RTO/RPO).
Anche in questo caso è la tipologia del servizio che ci farà propendere verso l’adozione di un sistema decisionale autonomo oppure umano.
Prendiamo ad esempio un servizio di emergenza come potrebbe essere un 118. Questo servizio, per sua natura, prevede il coordinamento su un territorio specifico di diverse organizzazioni come ad esempio le ambulanze di più enti, Croce Rossa, Pompieri, Organi di Polizia etc. Quindi, per sua natura, un servizio 118 deve avere un sito di Disaster Recovery che in caso di non operatività o non raggiungibilità del sito principale possa continuare il coordinamento in tempi molto rapidi.
Con quali tempistiche è necessario il ritorno all’operatività?
Tipicamente un servizio di questo tipo deve essere operativo in un tempo massimo di 15 minuti. Un tempo quindi incompatibile con una decisione umana, che tra le altre cose potrebbe non essere disponibile al momento dell’evento. La decisione, anche se si tratta di infrastruttura di DR, dovrà essere presa necessariamente da un sistema decisionale autonomo per rientrare negli SLA (Service Level Agreement) in ottemperanza al parametro RTO (Recovery Time Objective) fissato per questo servizio.
Su servizi che non richiedono una decisione automatica quali sono i parametri che fanno decidere di attivare il DR da parte del comitato di disastro?
In dipendenza della complessità del servizio, le domande fondamentali che determinano una decisione di attivazione del sito di DR sono le seguenti:
- Il servizio principale è compromesso in maniera permanente?
- Quando è stata effettuata l’ultima prova di DR?
- Una volta che il sito di DR è stato attivato, quanto mi costa ritornare sul sito Principale?
Per danno permanente del sito principale si intende un danno che non gli permette di ritornare attivo se non con un costo superiore al costo di ripristino alla normalità una volta terminata l’emergenza (Fail-Back), unito alla consapevolezza della bontà delle procedure di attivazione del sito di DR e dall’ultimo test di DR effettuato con successo.
Infatti, una decisione di passaggio da sito principale a DR deve tener conto dei punti 2 e 3 ed è per questo che molte volte si preferisce, o si è obbligati, a non attivare i servizi di DR, magari mantenendo chiuse centinaia di filiali con migliaia di dipendenti ed attendere che il sito principale venga ripristinato piuttosto che attivare il sito di DR. Quindi, a meno che il sito principale non sia definitivamente fuori gioco – incendio distruttivo, allagamento o catastrofe naturale – il sito di DR difficilmente in ambienti complessi verrà attivato a cuor leggero e se non strettamente e assolutamente necessario.
Ma se i miei servizi sono critici ed ho necessità di decisioni repentine e quindi automatiche, quali sono i parametri che devono guidare la mia scelta?
-
Innanzitutto è necessario verificare se l’interlocutore che mi sta proponendo una soluzione conosce gli algoritmi basati su quorum per evitare semplificazioni che possono essere pericolose, specie su servizi critici.
-
Secondo, ma non ultimo, verificare con una “griglia degli eventi” le possibilità di avaria (failure) e stabilire quali azioni correttive eseguiranno i singoli elementi in tutte le situazioni. L’attenzione deve spaziare da una avaria totale ad una avaria parziale fino a tener in dovuta considerazione fenomeni di Split Brain logica, i più insidiosi, che possono compromettere i dati da un punto di vista logico e quindi con costi di ripristino o addirittura di perdita di dati non calcolabili a priori. Un esempio di griglia degli eventi può essere descritto come di seguito:
| Evento | Effetto sul sistema Primary | Effetto sul sistema Secondary | Risultato atteso |
|---|---|---|---|
| Failure rete heartbeat tra i due siti | Xxxx | Yyyy | Zzzz |
| Failure rete pubblica, irraggiungibilità dei servizi | Xxxx | Yyyy | Zzzz |
| Failure rete quorum del primario | Xxxx | Yyyy | Zzzz |
| Failure dello storage primario | Xxxx | Yyyy | Zzzz |
| Failure del sistema secondario | Xxxx | Yyyy | Zzzz |
| Failure del sistema secondario e non raggiungibilità del sistema quorum | Xxxx | Yyyy | Zzzz |
| Failure di parte dei servizi AAA | Xxxx | Yyyy | Zzzz |
| … | |||
| … |
Cos’è uno Split Brain?
Per Split Brain si identifica l’evento in cui entrambi i siti, principale e secondario, si considerano come unici superstiti e prendono la decisione di diventare entrambi Primari.
Questa eventualità è, come detto, la peggiore in quanto gli archivi e le basi dati non si corrompono fisicamente ma logicamente. La corruzione logica fa sì che, ad esempio, ad una chiave di valore progressivo 101 in un sito sia attribuito un valore al “Signor Bianchi” e all’altro sito sia attribuito un valore al “Signor Verdi”. Questo tipo di mescolamento dei dati rende praticamente impossibile, o troppo costoso, un riallineamento delle basi dati tra i due siti e quasi sempre si opta per la perdita di alcune informazioni.
Si può evitare lo Split Brain?
Si, si può evitare descrivendo gli scenari e mettendoli in una griglia al fine di verificare ogni evento possibile con le azioni previste. Poi si arriverà ad una conclusione che noi chiamiamo “Quorum Games” dove nessuno, come nel gioco Tic Tac Toe, esce vincitore e proprio per questo lo abbiamo voluto chiamare “Quorum Games” parafrasando il famoso film “Wargames” dove nessuno è vincitore ma il buon senso ti porta a trovare una soluzione. “Quorum Games” sarà l’argomento del prossimo articolo con l’approfondimento specifico sull’algoritmo e come si possono mitigare fenomeni di stallo decisionale.
Cosa può fare Olpon Networks per ottenere il massimo dell’affidabilità?
Basata su una lunga esperienza in campo mission-critical e business-critical, Oplon Networks progetta e costruisce prodotti che soddisfano i requisiti di affidabilità per grandi e piccole aziende che non possono permettersi perdite di dati o discontinuità di servizio.
A supporto delle infrastrutture critiche i prodotti Oplon Commander Decision Engine, Oplon Commander Workflow integrati al sistema Oplon Application Delivery Controller permettono un controllo completo delle operazioni in teatri operativi critici dove l’affidabilità deve essere al servizio del controllo.
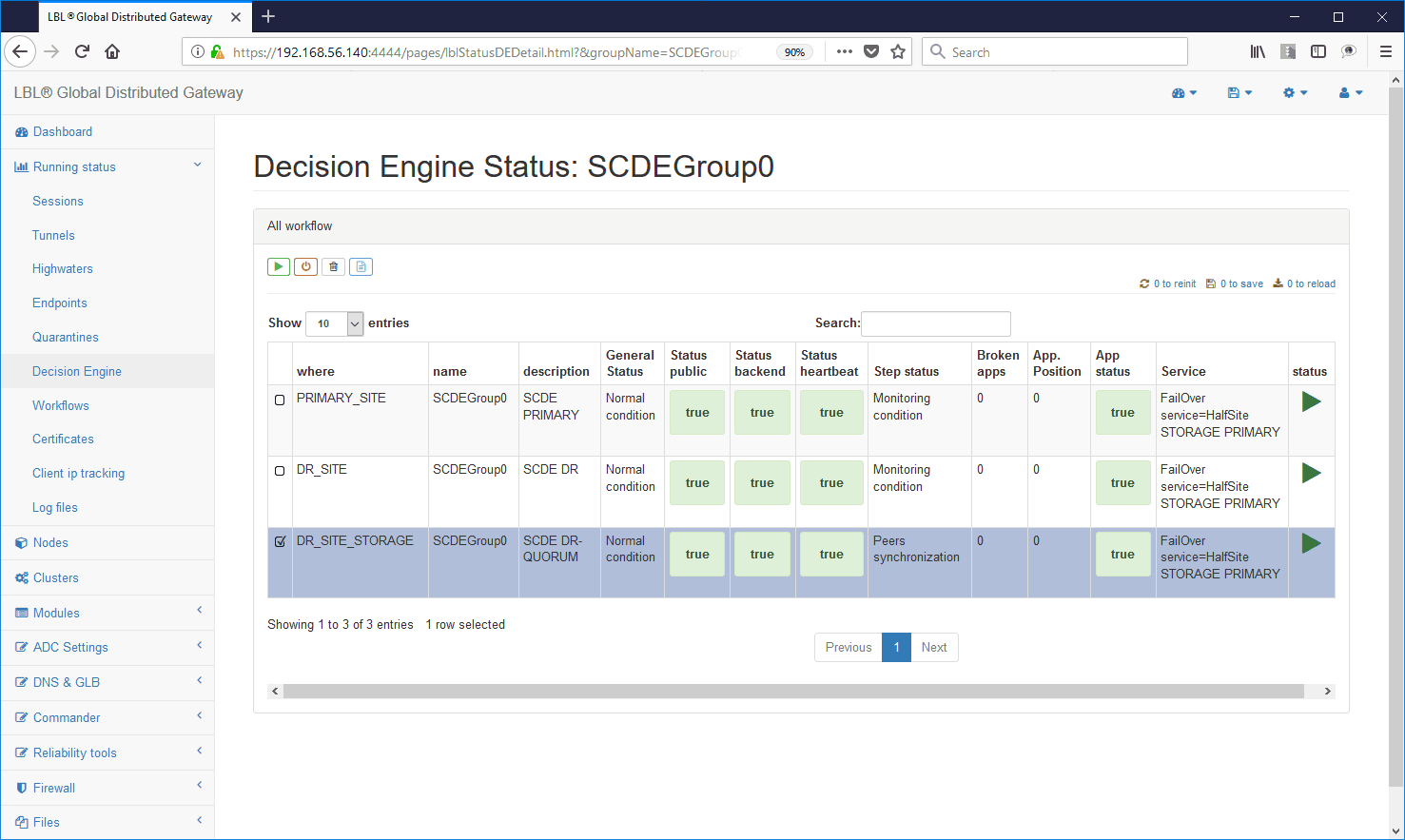
Esempio di Decision Engine di una evenienza critica in un servizio:
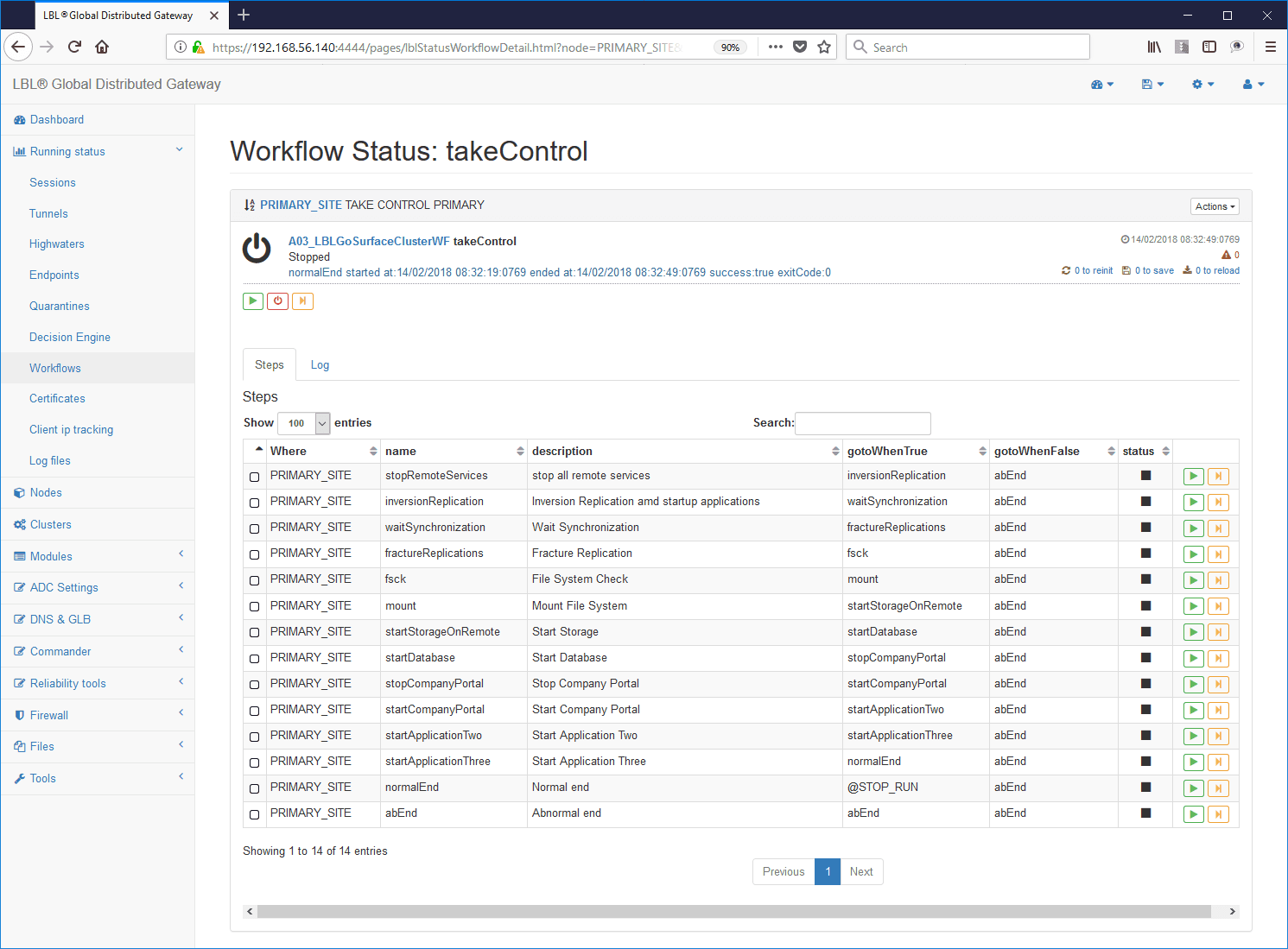
Esempio di WorkFlow con gli step procedurali autodocumentanti: