DoS & DDoS mitigation: guide to understand, when it works and when it doesn’t
This document describes what lies beneath the two simple acronyms DoS and DDoS, which instead incapsulate a moltitude of aspects to be taken into consideration in order to better understand dynamics and solutions.
The document is intended as a reference for those who have questions the day after they have purchased anti DoS/DdoS services and applications continue to be plagued by these problems.
DoS/DDoS typologies
Let us clarify immediately the two terminologies that seem apparently obvious, given the acronyms, but in reality even the acronyms can be misinterpreted.
DoS (Denial of Service) is the acronym for an attack originating from a single address; DDoS (Distributed Denial of Service) indicates an attack originating from multiple addresses.
Actually, even a DoS attack can originate from different addresses that, due to the effects of NAT networks or proxy systems, conceal the real origins. These attacks are easily recognizable.
DDoS (Distributed Denial of Service) attacks, on the other hand, are always carried out from different IP addresses and are characterized by their type and origin.
Types:
-
Volumetric or quantitative attacks
-
Qualitative attacks
Origin:
-
From completely different and lawful addresses
-
From specific subnets
Volumetric or quantitative DDoS attack
A volumetric or quantitative DDoS attack is an attack where the amount of data transferred is such that it can saturate the capacity of the network to the point of collapse. These attacks are usually very heavy and often come directly from service providers or even CDNs that, having been hacked, conduct massive attacks without their knowledge. Dedicated lines or CDNs are divided into categories and more precisely:
EUROPE
| Type | Capacity |
|---|---|
| E0 | 64Kbps |
| E1 | 32 lines E0 2Mbps |
| E2 | 128 lines E0 8Mbps |
| E3 | 16 lines E1 34Mbps |
| E4 | 64 lines E1 140Mbps |
United States
| Type | Capacity |
|---|---|
| T1 | 1.544 Mbps |
| T2 | 4 lines T1 6 Mbps |
| T3 | 28 lines T1 45 Mbps |
| T4 | 168 lines T1 275 Mbps |
Often and historically, these nodes are located in research centers and for this reason become unintentional attack vectors for breaches that may occur in laboratories that, typically by their nature, do not adopt high security systems or do not even adapt security systems at all.
Qualitative DDoS attack
Qualitative DDoS attacks are defined as attacks from multiple IP addresses that, although they do not move large masses of data, do affect the quality of service. Usually, these attacks aim to saturate the application and not the network, which is why network tools are unable to distinguish them. They are attacks aimed either at the application layer, i.e. the transport and application protocol (4-7 OSI), or at the application’s constructive weakness, i.e. the code written to execute the service.
Distinguishing a DDoS attack from legitimate traffic
Distinguishing a DDoS attack from legitimate traffic would at first glance appear simple! An increase in volume or an increase in requests compared to the norm would seem to be sufficient to determine an attack and to remedy it. Nothing could be more wrong: an increase in the amount of requests or volume or both is not sufficient.
By way of example we can mention a few cases. Imagine an e-commerce site where marketing has packaged a sales campaign through discounts on a certain group of articles. Marketing, once the campaign has been finalized, decides to e-mail the promotion to a very large number of e-mail addresses, e.g. 600,000 e-mail addresses. It is statistically proven that 25 per cent / 30 per cent of the emails sent are opened and the person receiving them goes to see the content of the promotion and requests it with one click. In this case we are pessimistically talking about 150,000 users!
From the point of view of detection, an unintelligent DDoS system could think of an attack considering that the average traffic in the last two weeks was 6000 simultaneous users with peaks of 25000 users.
Obviously, this is not an attack, it is a well-designed marketing campaign that has been successful in converting e-mails into contacts for which 4% turns into sales. If a DDoS system blocked this traffic, there would probably be a claim for damages for lost revenue. Bear this in mind because we will come back to it later.
Another example could be what in Italy is called a ‘click-day’ (note, this name does not exist anywhere else in the world!), i.e. a pre-established ‘moment’ in which a service is enabled in order to obtain a service/services that is, however, allocated on a ‘first come, first served’ basis. Obviously, at that pre-established moment, all those who want to compete will have to be ready to ‘click’ to access the performance/service, inexorably causing an increase both in volume, which is usually not significant, but above all in the number of simultaneous requests. The effects are known to all. Again, if an anti DDoS system tried to statistically determine an attack, it would be misled. Then, depending on the nature of the performance/service, legal action could be threatened due to lack of access to the performance/service.
Other reasons, among many, why anti-DoS/DDoS systems might not distinguish an attack are applications, not human beings, which, under certain circumstances or moments, perform a large number of transactions due to a contingent factor. Think for instance of online trading systems that react with automatic sales or purchases. The increase in requests for service could be caused by an event or by errors, network/application errors, which lead, in particular situations, to a compulsive repetition and reiteration of the unsuccessful transaction. If even in this case an anti DDoS system went into action blocking transactions, the problem would certainly lead to legal consequences and claims for compensation.
At this point we are ready to better understand why sometimes systems do not intervene!
Anti DDoS systems can be divided into 4 categories:
-
Volumetric
-
Statistic
-
Database of malicious addresses
-
Application stress level detection
In this category, we also distinguish two other categories:
a. with detection agents
b. without detection agents (Agentless)
Volumetric anti DDoS systems
Volumetric anti DDoS systems, or rather, volume-based DDoS mitigation, are those typically used by telco providers. These systems detect the volume of traffic and act on a finite parameter, the throughput capacity of the observed network. These systems are very reliable because they act on a finite parameter, too bad they do not guarantee effective coverage for applications.
In fact, the parameter on which they base their reaction is the volume of data transferred and by the time this is detected, it is already too late for applications. In fact, they are very effective in protecting the telco operator’s core-switches and only if the system detects possible compromises of these devices do they react by shifting the routing of the border routers to ‘black holes’ that safeguard the operation of the devices. It is indeed a protection of the telco operator’s apparatuses that are not able to guarantee the functioning of applications (services) because they are not able to understand application fatigue and a reaction to a change in volume could compromise the application’s business with the effects of legal action for loss of earnings or service.
Ultimately, this type of detection could be equated with a stress detection system, but one that is not application-related but rather telco-operator-related.
Statistic anti DDoS systems
Products based on state variation fall under this segment. The system learns and stores an experience of volume and/or requests and reacts to changes in these by blocking the source addresses.
Again, the algorithm blatantly fails in all those cases where traffic, in volume or per request, varies by crossing certain thresholds, but the systems are working perfectly.
This is the most deleterious system because it does not consider the application system!
This is why all systems based on this algorithm, in the best of cases, simply do not react and merely provide a ‘post-mortem’ platform of the service to detect which IP addresses caused the crash.
Most systems on the market today are based on this algorithm combined, to mitigate its negative effects, with other algorithms such as those based on databases of malicious addresses.
Anti DDoS systems with malicious address database
To compensate for the inefficiencies of statistical anti DDoS systems, malicious address databases have developed over time. Databases of malicious addresses are fed by the ‘post-mortem’ detections of statistical anti DDoS systems, thus always too late for the victim.
In addition, a major problem is that if the address detected is of a lawful service, it will be blocked for all those who use that database without the knowledge of the service provider, who will see its traffic volume and worse, if it is a business, its sales volume, cut.
These types of systems are also highly unreliable in the light of the latest attacks, which always originate from lawful addresses that are not yet in these databases, with the effect that, post-mortem, even these addresses will appear to be unlawful. In practice, this system is outdated and even harmful if one thinks of possible misuse, such as unfair competition by untrusted personnel who enter addresses in the database to be blocked for profit.
Moreover, and not least, since the databases are fed by the experiences of crashed services, they are a spontaneous exfiltration of sensitive data that are often not reported to the user who may be paying for them as a service. As a matter of fact, within this database there are not only the addresses that blocked the site but often also the site and the blocked service, exposing that specific service even more to possible targeted attacks because they are openly highlighted by the crash.
Anti-DDoS systems with application stress level detection
These systems are among the most effective in detecting DdoS attacks or rather, as we shall see, in detecting a possible problem that will lead to a stop of the service.
It is clear that the stress-detection system only comes into action when, regardless of the cause, the service slows down to the point of becoming unusable for users, thus in a true Denial of Service state.
This system is the only one that should be counted among DDoS systems as it actually detects the ‘Denial of Service’ and not the ‘Denial of Tool’ (core-swicth fault) or the increase in requests.
The algorithm is therefore quite good at mitigating the effects of a service overload, but here too it depends on who is doing the detecting and on what basis the overload is determined, and furthermore, whether they are able to signal and react to the overload in good time.
Let us begin by distinguishing two types of detectors, agent- and agentless.
Anti DDoS systems with application stress detection agents
Agent-based detectors are again distinguished with agents on board the application (plugin-agent) on the server (agent) or externally, monitoring systems or hybrid systems.
Typically these agents are for ‘post-mortem’ tracking or for raising alarms. In recent years, they have also evolved to detect stress and increase the number of resources to cope with the increased load (see EC2 autoscaling, Kubernetes Horizontal Pod Autoscaling etc.), which are difficult to integrate with systems that react by blocking unlawful overload.
Agent-driven systems also have an entropy problem. If the services are few and well-defined they are enforceable, if the managed services are several thousand the maintenance of the agents is very expensive in terms of installation and maintenance costs. As agent releases or updates change, maintenance becomes impossible to keep under control and a state of inconsistency is almost always reached.
Plugin-agent systems, i.e. integrated on the application middlware, web server or application server, also suffer from incompatibility problems between middlware releases and plugin-agents, often causing service problems even before they are resolved.
Moreover, agent systems can hardly detect the new ‘slow’ attacks that tend to create very little traffic but keep servers busy with connections that transmit very little data but keep all resources busy by exchanging only a few bytes so as not to time-out the connection but saturate the memory to the point of overflow, memory that I remember is shared on the same address space as the plug-in agent!
Anti DDoS agentless application stress detection systems
These systems are the best DoS/DDoS attack mitigation tool on the market today because, based on application stress detection, they do not need to install agents that in infrastructures with thousands of services do not need any kind of maintenance otherwise, even if thousands of nodes and applications are needed.
Furthermore, by being the conduit (pass-through) of traffic, they are also, spontaneously, the system where instantaneous decisions can be made and thus can be perfect mitigators of DoS/DDoS phenomena having detected the actual need for action. Detection is timely, at the moment when systems are slowing down, and they are able to take an initiative.
Obviously, detection cannot be detected at the level and with network equipment, one would have to take into account the logicality of the packets! So it cannot be carried out by a switch or even by a system that ‘inspects’ packet traffic, which is moreover now always encrypted in almost all data centers, even in the intranet, to avoid leaks of sensitive data.
Oplon DoS/DDoS attack mitigation
The Oplon DoS/DDoS attack mitigation system encapsulates the best of the technology available today.
It is a system of the qualitative anti DoS/DDoS category with application stress detection and instantaneous reaction (5 milliseconds) to slowdown detection without the use of agents (agentless) of any kind.
The system is based on software scalability studies that led to the construction of a finite-resource engine that, if properly configured, cannot suffer from out-of-memory or out-of-resource due to overloading and is therefore able to react to even a massive attack.
The system initialises the following basic elements at start-up:
-
Listeners
-
Tunnels
-
A queue of “incoming connections to resolve”
-
A queue of “incoming connections to clean”
-
A Washing Machine
-
A Quarantine addresses/subnet tables
-
DoS / DDoS attack detector
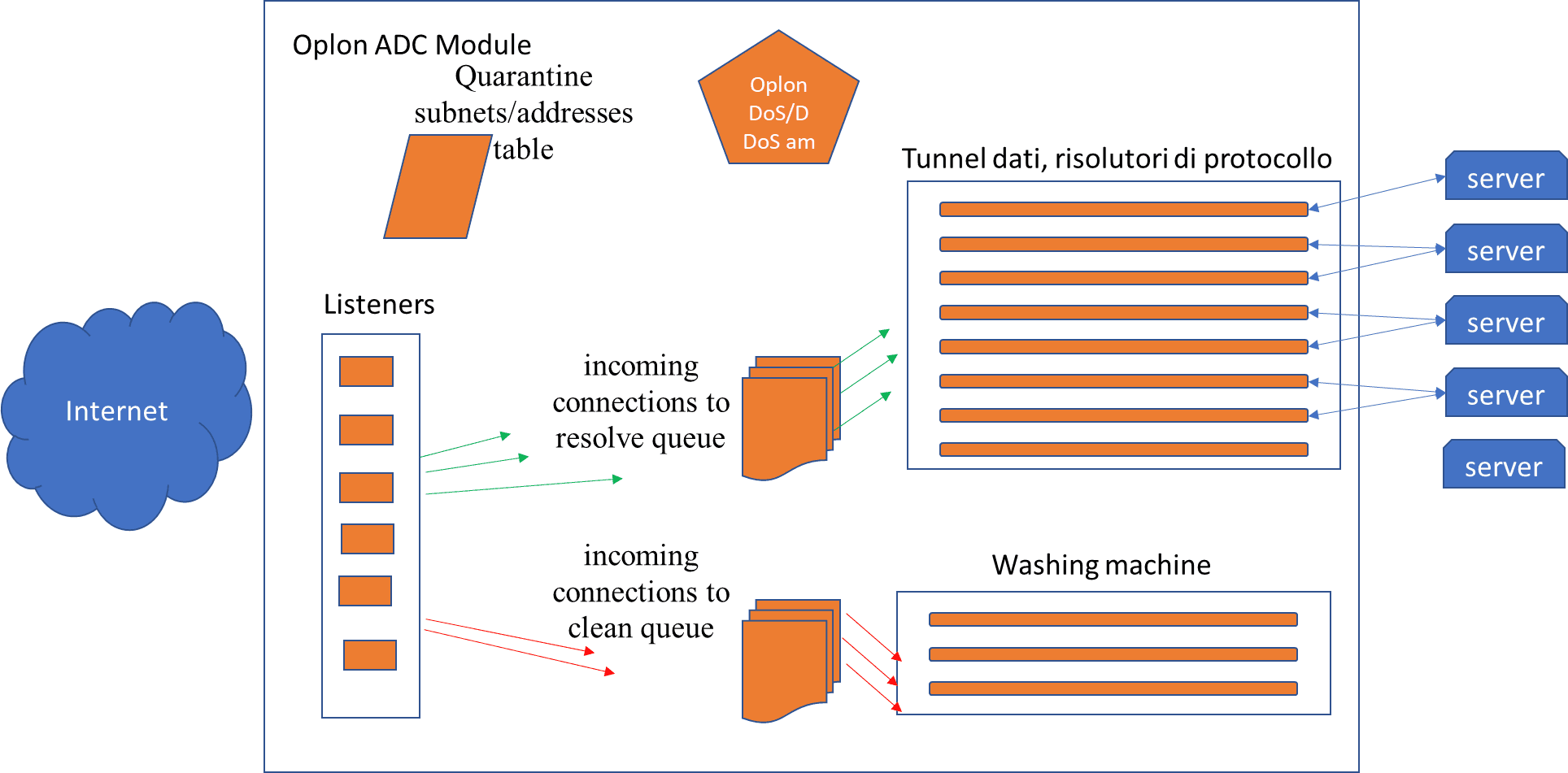
The system is therefore based on a finite number of tunnels that have typically been dimensioned for the traffic to be supported at a defined ‘normal’ time, also taking into account ‘peaks’ based on the experience and indications of the application system engineers and application sizing.
The relationship tunnel-client with consultative applications is typically 1/7, 1/10 that descends if applications maintain persistent connections.
The system that oversees event detection, Oplon DoS/DDoS attack mitigation, is an asynchronous system that scans all elements at 5 millisecond intervals and verifies:
-
Active tunnel threshold
-
Queuing threshold on incoming connections
-
Recursive IP occurrence thresholds
-
Cataloging of IP subnets occurrences
-
Cataloging of temporal occurrences of IP commitment and IP subnets
-
At layer 7 http cataloging of occurrences of X-FORWARDED-FOR chains
-
Threshold of survivor tunnel space reached
Conclusion and benefits
Below are the benefits of the Oplon DoS / DDoS attack mitigation solution and what it does not cover.
Benefits:
-
The system is completely agentless
-
The system is based on application stress
-
The system reacts within 5 milliseconds from the detection
-
The system also reacts to application slowdowns that are not caused externally
-
The system is capable of ‘washing’ (washing machine) IP addresses that are quarantined
-
The washing machine does not affect the resources allocated to resolving protocols (tunnel and incoming connections to resolve protocols)
-
The system allows fine tracking of the IP addresses that are causing the problem
-
The ‘quarantine’ system allows addresses that are temporarily causing a problem but are lawful to be placed in a state of being unable to harm
-
The system is capable of intercepting “slow” attacks
-
The system allows, even during an attack, a service to leave resources free for other services that are sharing resources (tunnel survivor space)
What it does not do:
Not volumetric, this system must be supported by volumetric anti ‘DDoS’ or rather ‘DDoT’ (Denial of Tool) systems made available by telco providers.
Author: Valerio Mezzalira