Business Continuity (BC) and Disaster Recovery (DR): automatic decisions or human decisions?
This second article on the topics of Business Continuity (BC) and Disaster Recovery (DR) focuses on what procedure to perform to move services from a main site to a secondary site and, specifically, if the decision must be human or automatic.
Normally we are led to think that a Business Continuity site must be guaranteed by automatic decisions while, if we talk about Disaster Recovery, the decision must be left to a human decision often made up of a disaster committee that decides what to do.
In reality, it is not the terms BC or DR that determine an automatic or human decision but the type of service that we must protect in operation.
In the previous article on this topic we talked about when to use BC or DR and we stopped on the type of service to understand if we need Business Continuity or Disaster Recovery.
The example mentioned compared a first aid service, which needs BC, compared to a logistics service that definitely needs a DR infrastructure and possibly also a BC infrastructure based on a cost analysis and benefits (RTO / RPO).
Also in this case it is the type of service that will make us lean towards the adoption of an autonomous or human decision-making system.
Take for example an emergency service like a 118 could be. This service, by its nature, provides for the coordination on a specific territory of different organizations such as the ambulances of several bodies, the Red Cross, Firefighters, Police Bodies etc. Therefore, by its nature, a 118 service must have a Disaster Recovery site which in the event of non-operation or unreachability of the main site can continue coordination in a very short time.
How long does it take to return to operation?
Typically a service of this type must be operational in a maximum time of 15 minutes. A time therefore incompatible with a human decision, which among other things may not be available at the time of the event. The decision, even if it is a DR infrastructure,must necessarily be taken by an autonomous decision-making system to be included in the SLA (Service Level Agreement) in compliance with the RTO parameter ( Recovery Time Objective) set for this service.
On services that do not require an automatic decision, what are the parameters that make the disaster committee decide to activate the DR?
Depending on the complexity of the service, the fundamental questions that determine a decision to activate the DR site are the following:
- Is the primary service permanently compromised?
- When was the last DR test performed?
- Once the DR site has been activated, how much does it cost me to return to the Main site?
By permanent damage to the main site we mean damage that does not allow it to return active except with a cost higher than the cost of restoration to normal once the emergency is over (Fail-Back), combined with the awareness of the goodness of the DR site activation procedures and the last successful DR test.
In fact, a decision to switch from main site to DR must take into account points 2 and 3 and this is why many times you prefer, or are obliged, not to activate DR services, perhaps keeping hundreds of branches closed with thousands of employees and wait for the main site to be restored rather than activating the DR site.So unless the main site is permanently out of action – destructive fire, flooding or natural disaster – the DR site will hardly be activated in complex environments lightly and if not strictly and absolutely necessary.
But if my services are critical and I need sudden and therefore automatic decisions, what are the parameters that must guide my choice?
-
First of all, it is necessary to verify if the interlocutor who is proposing a solution knows the algorithms based on quorum to avoid simplifications that can be dangerous, especially on critical services.
-
Second, but not least, check with**“event grid”** the possibility of failure and determine which corrective actions the individual elements will perform in all situations. The attention must range from a total failure to a partial failure up to taking into due consideration logical phenomena of Split Brain, the most insidious,that can compromise the data from a logical point of view and therefore with recovery costs or even loss of data that cannot be calculated a priori. An example of an event grid can be described as follows:
| Event | Effect on the Primary system | Effect on the Secondary system | Expected result |
|---|---|---|---|
| Event | Effect on the Primary system | Effect on the Secondary system | Expected result |
| Failure heartbeat network between the two sites | Xxxx | Yyyy | Zzzz |
| Public network failure, unreachable services | Xxxx | Yyyy | Zzzz |
| Primary quorum network failure | Xxxx | Yyyy | Zzzz |
| Primary storage failure | Xxxx | Yyyy | Zzzz |
| Failure of the secondary system | Xxxx | Yyyy | Zzzz |
| Failure of the secondary system and unreachability of the quorum system | Xxxx | Yyyy | Zzzz |
| Failure of part of the AAA services | Xxxx | Yyyy | Zzzz |
| … | |||
| … |
What is a Split Brain?
Split Brain identifies the event in which both the main and secondary sites consider themselves to be the only survivors and make the decision to become both Primaries.
This eventuality is, as mentioned, the worst since archives and databases are not corrupted physically but logically. Logical corruption means that, for example, a progressive value key 101 on one site is assigned a value to “Mr. Bianchi” and the other site is assigned a value to “Mr. Verdi”. This type of data mixing makes a realignment of the databases between the two sites practically impossible, or too expensive, and almost always opt for the loss of some information.
Can Split Brain be avoided?
Yes, it can be avoided by describing the scenarios and putting them in a grid in order to verify each possible event with the foreseen actions. Then we will come to a conclusion that we call “Quorum Games” where no one, as in the Tic Tac Toe game, comes out victorious and for this reason we wanted to call it “Quorum Games” paraphrasing the famous film “Wargames” where nobody is a winner but the common sense leads you to find a solution.“Quorum Games” will be the topic of the next article with a specific study on the algorithm and how it can mitigate decision-making deadlocks.
What can Olpon Networks do to achieve maximum reliability?
Based on long experience in mission-critical and business-critical fields, Oplon Networks designs and builds products that meet reliability requirements for large and small businesses that cannot afford data loss or discontinuity of service.
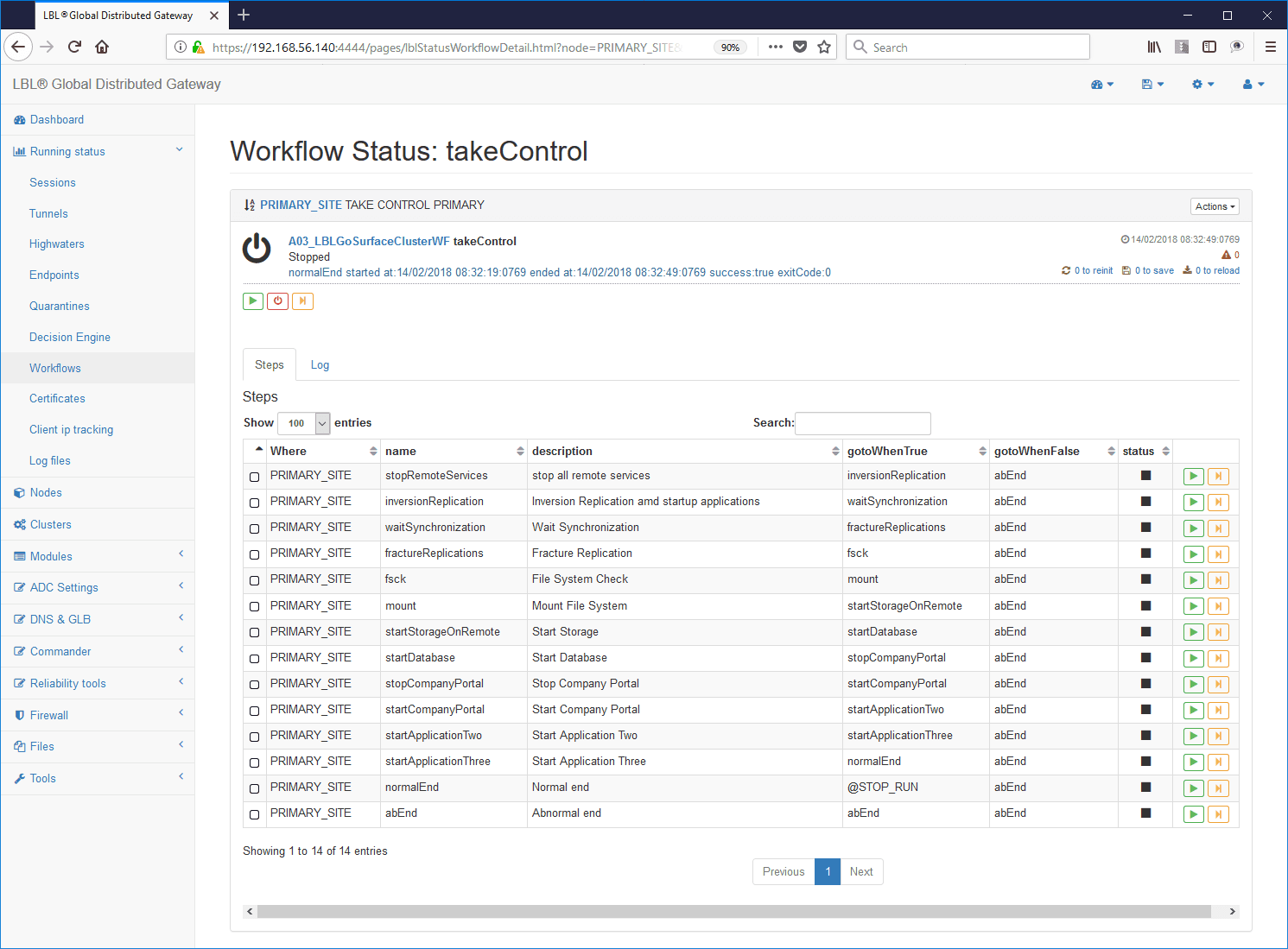
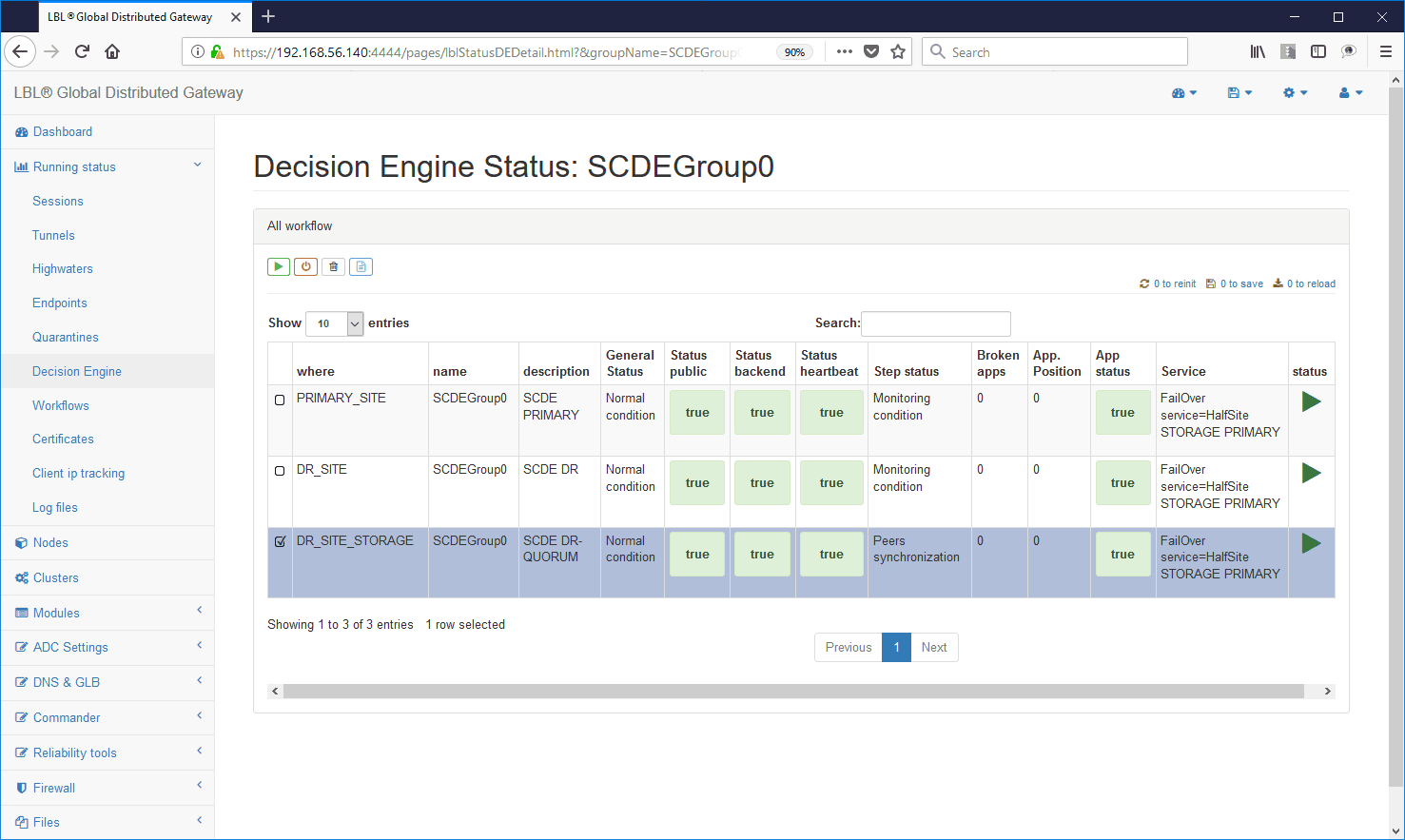
In support of critical infrastructures the products Oplon Commander Decision Engine, Oplon Commander Workflow integrated into the system Oplon Application Delivery Controller allow complete control of the operations in critical operating theaters where reliability must be at the service of control.
Decision Engine example of a critical event in a service:
Example of WorkFlow with self-documenting procedural steps: