Commander setup
Installation
To install Oplon Commander you must proceed with the installation of base available in the installation and setup manual.
Oplon Commander introduction
Oplon Commander introduces a new concept of high reliability in application area, covering the role of coordinator of the activity in a mission-critical datacenter. Oplon Commander is composed from two main modules: Oplon Commander Work Flow and Oplon Commander Decision Engine. The two modules were designed for work in cooperation with each other or, if not required automatic operations, you can use only the component Oplon Commander Work Flow. Oplon Commander Decision Engine was designed to cooperate with Oplon ADC.
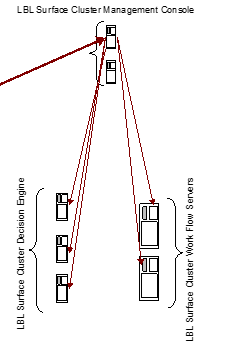
The general architecture can be summarized in the following scheme:
The flexibility of the instrument can be expressed in different architectures.
Just the feature of separation of activities between Oplon Commander Work Flow, what to do, and Oplon Commander Decision Engine, when it needs to be done, allows us to divide installation in two phases, first checking all manually flows and then, if automatic operation is required, proceed with the installation of Oplon Commander Decision Engine.
For this reason the manual is divided into this sequence on two chapters, one concerning the installation of Oplon Commander Work Flow the other concerning the installation of Oplon Commander Decision Engine.
Oplon Commander Work Flow introduction
The installation of the Oplon Commander Work Flow module requires a preventive analysis of the objectives to be pursued in as by its nature Oplon Commander Work Flow is a tool in able to carry out any operation that is scheduled.
For this manual we will use a minimal example where we will manage a Apache Tomcat process in its life cycle: Start, Shutdown (N.B .: When we talk about shutdwon we mean the stop of applications and not of the operating system that hosts them). Then wanting to reuse it same example for the Oplon Commander Decision component Engine. For now, we will identify two types of jobs: normalPrimer (primary trigger) and gracefulShutdown (shutdown controlled applications).
Oplon Commander Work Flow design
Oplon Commander Work Flow assumes that any complex operation can be broken down into elementary objects.
The first operation to be carried out is therefore the identification of the jobs to be performed (Work Flows) and the activities within each individual work (steps).
For example, if you want to start an Apache Tomcat process we will first need to identify the type of job with a name. In in this case we will choose normalPrimer as the identification name of the Work Flow to trigger the start of the process. Definitely a start a controlled stop must also be made possible. TO for this purpose we will also identify a name to perform this job: gracefulShutdown.
Once we have identified the work to be carried out we will check for each work (Work Flow) the characteristic steps.
In this case for the Work Flow normalPrimer surely we will have to use one step that will launch tomcat (ex .: startupTomcat) and one step that will end the execution of tomcat (e.g .: shutdownTomcat).
Another operation is the identification of the termination steps of the Work Flow. By convention, a Work Flow can end with normalEnd if the operation is successful and a step with the name abEnd (abnormal end) in case the operation does not finish successfully.
As we will see later, the normalEnd and abEnd steps are fairly constant in all types of Work Flow identify
Once we have identified the typical steps of our project we can focus on developing the commands that will lead to the definition of our Work Flows.
Oplon Commander Work Flow address plan
Being * Oplon Commander * Work Flow a service available on the network is need to make the address plan to be able to identify on which servers and their networks will be made available. The service comes delivered in the form of Remote Workflow Command (RWC) in secure mode (HTTP-SSL) authenticated. It is possible to identify one or more
- Oplon Monitor * that can interact through their Web Console with * Oplon Commander * Work Flow. * Oplon Commander * Work Flow is also used by * Oplon Commander * Decision Engine in case they are anticipated automatic triggering in the face of application events.
The address plan for * Oplon Commander * Work Flow is a lot simple and can be implemented through a simple table as ad example the one proposed below:
| Hostname/Address | Port number | Description |
|---|---|---|
| legendonebackend | 54444 | HalfSite A.A |
| legendtwobackend | 54444 | HalfSite B.B |
NOTE: Nodes/locations are identified by letters divided by a punctuation. Punctuation indicates infrastructural depth. The first letter indicates the context with any relationships with decision engines * Oplon Commander * Decision Engine. We report the general architectural scheme again for display convenience.
Oplon Commander Work Flow Web Console
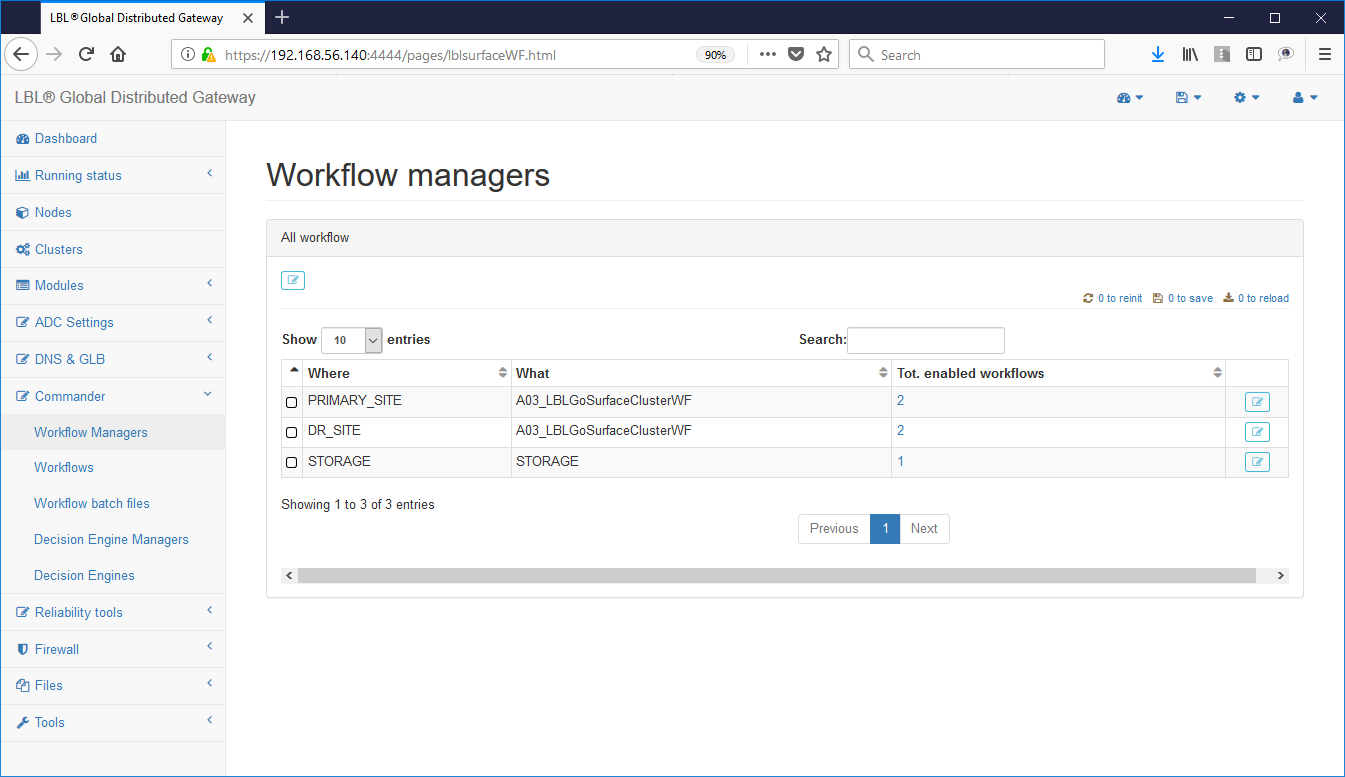
Oplon Commander Work Flow Web Console
Oplon Commander Work Flow directories and files
Oplon Commander Work Flow uses only two directories and one file configuration plus license file.
The default directories are:
(LBL_HOME) procsProfiles/A03_LBLGoSurfaceClusterWF/surfaceClusterWFCommandDir
(LBL_HOME)/procsProfiles/A03_LBLGoSurfaceClusterWF/conf
contains the license and configuration file surfaceclusterwf.xml
(LBL_HOME)/procsProfiles/A03_LBLGoSurfaceClusterWF/surfaceClusterWFCommandDir
is the default directory of the scripts/executables that will be started from the steps of a Work Flow. The distributions report in this directory batch files with names typical of a take-over stream of a site:
For UNIX/Linux environments:
unix/flushDisk.sh
unix/fractureReplications.sh
unix/fsck.sh
unix/inversionReplication.sh
unix/mountFileSystem.sh
unix/restartApache.sh
unix/selfTest.sh
unix/shutdownApplicationOne.sh
unix/shutdownApplicationThree.sh
unix/shutdownApplicationTwo.sh
unix/startApplicationOne.sh
unix/startApplicationThree.sh
unix/startApplicationTwo.sh
unix/startDatabase.sh
unix/umountFileSystem.sh
unix/waitSynchronization.sh
unix/checkApacheActivity.sh
For MSWindows environments:
windowslushDisk.bat
windowsfractureReplications.bat
windowsfsck.bat
windowsinversionReplication.bat
windowsmountFileSystem.bat
windowsrestartApache.bat
windowsselfTest.bat
windowsshutdownApplicationOne.bat
windowsshutdownApplicationThree.bat
windowsshutdownApplicationTwo.bat
windowsstartApplicationOne.bat
windowsstartApplicationThree.bat
windowsstartApplicationTwo.bat
windowsstartDatabase.bat
windowsumountFileSystem.bat
windowswaitSynchronization.bat
windowscheckApacheActivity.bat
Each of these files contains a minimal template ready to be populated with the appropriate commands of the platform concerned. TO Example title below is the contents of the commands listed above. For convenience, especially for MS Windows batch files, at the beginning of each command on the first parameter there is one interactive mode from a batch mode. This is comfortable in the phase implementation because in interactive mode it does not run the EXIT that would take MS Windows to exit the launch. In this case, the return code will be displayed with the which the batch file would be output to EXIT.
Obviously for what concerns Oplon Commander Work Flow the only one value used is the return code and so these examples are just from intended as a fully editable track.
MS Windows
Linux
The same operations can also be performed directly from web console through the following operations:
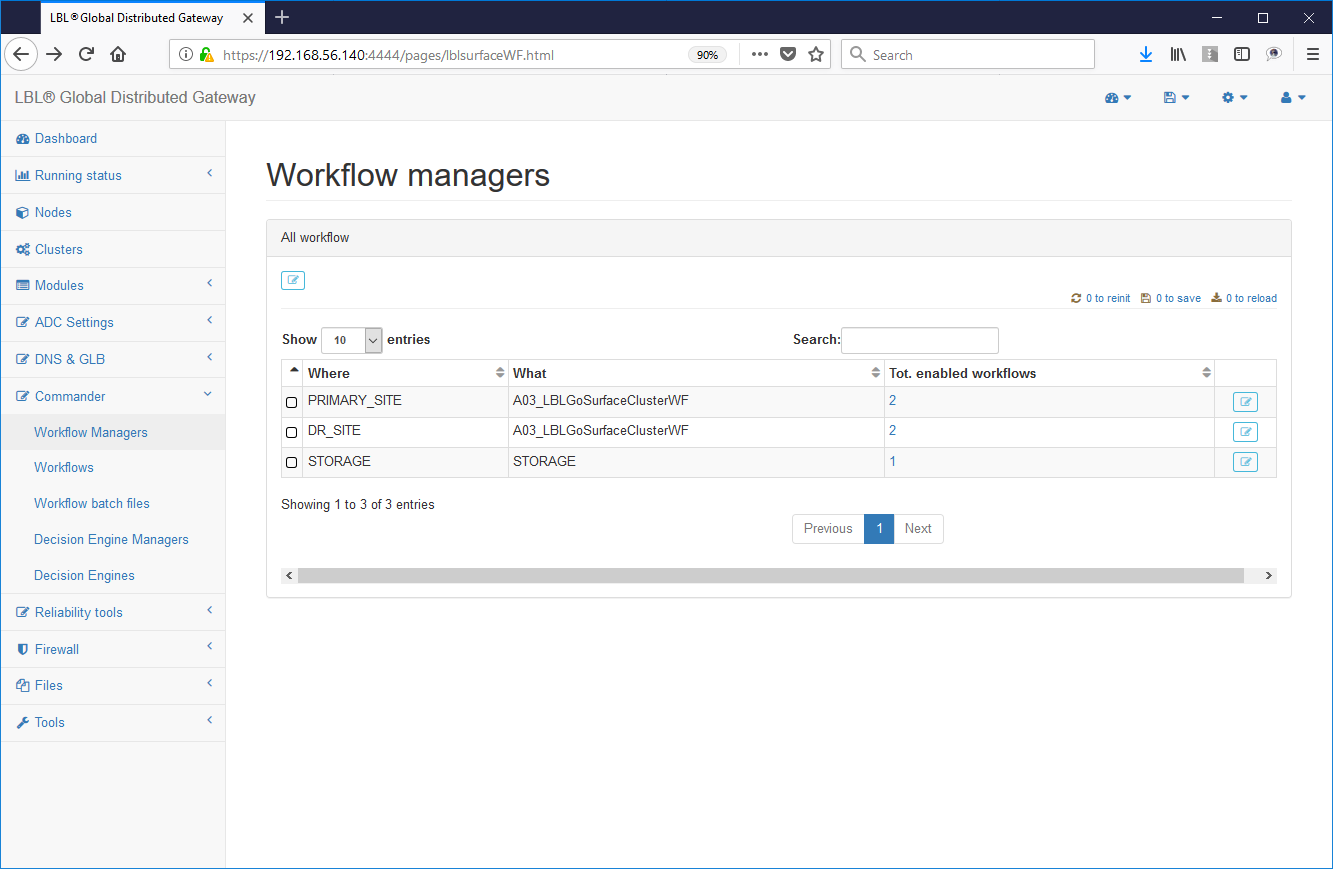 Commander-> Wirkflow Managers -> Choice
of the module
Commander-> Wirkflow Managers -> Choice
of the module
Choice of workflow
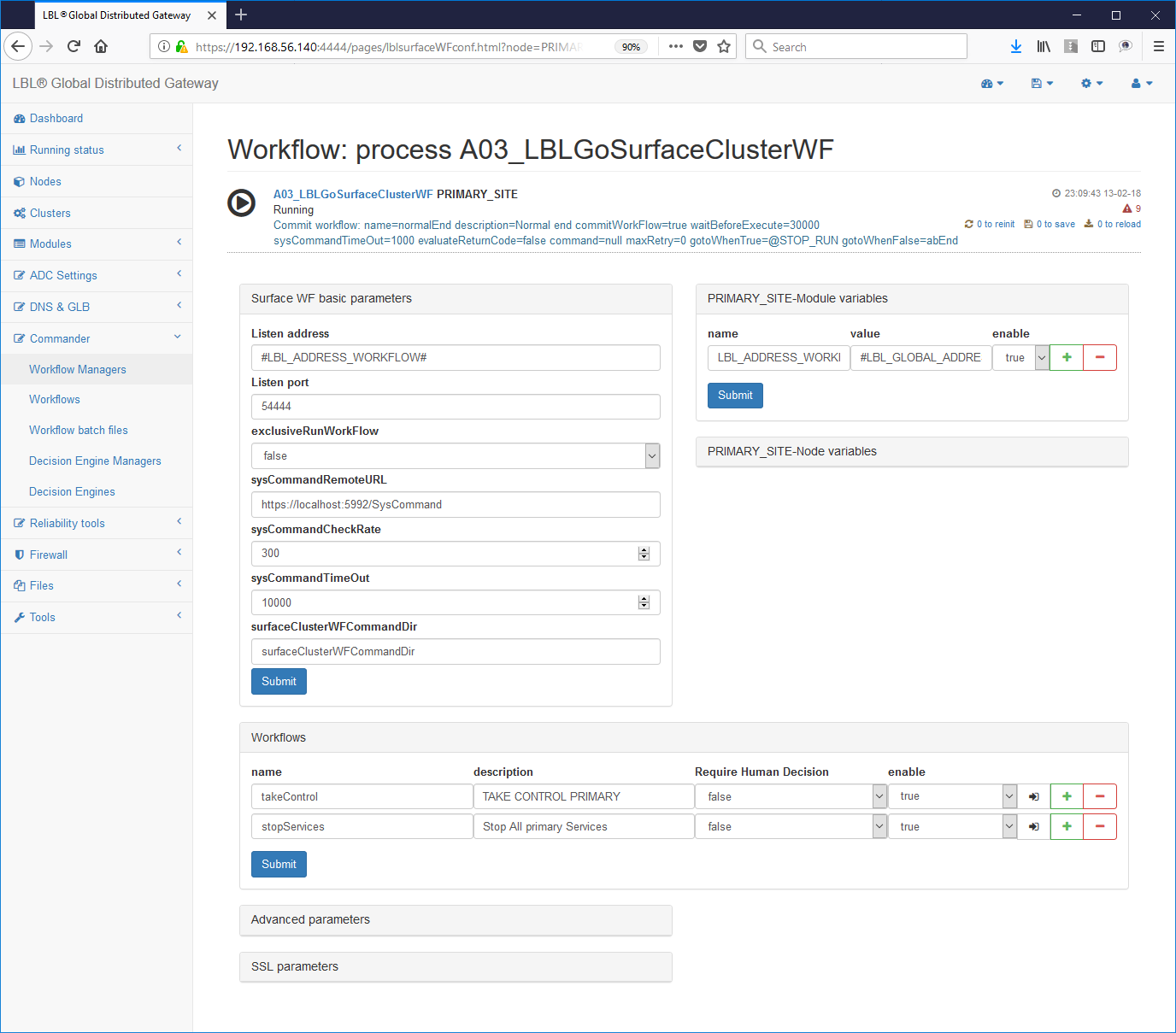
Choice of the step to edit e.g .:
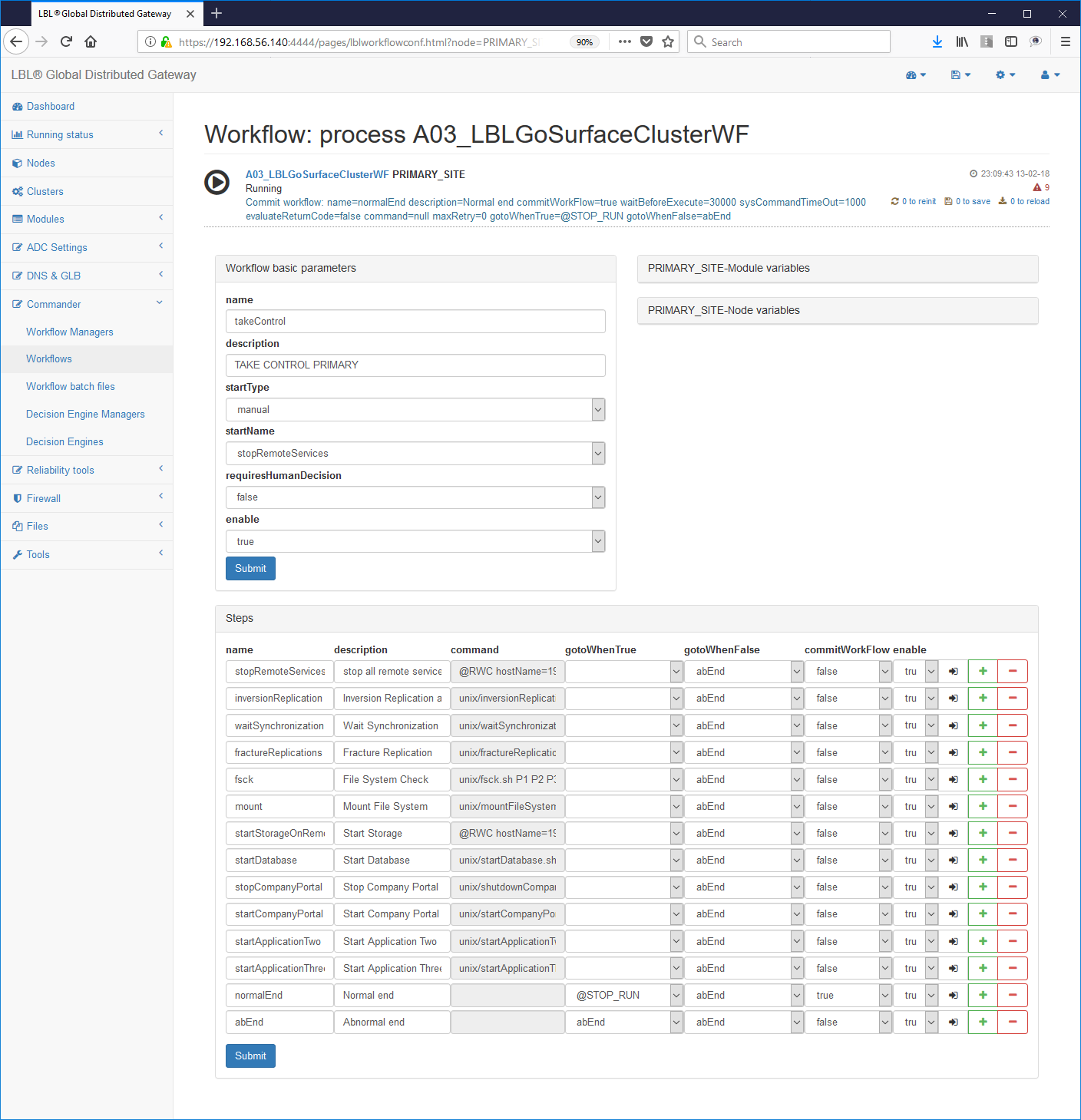
Script editing:
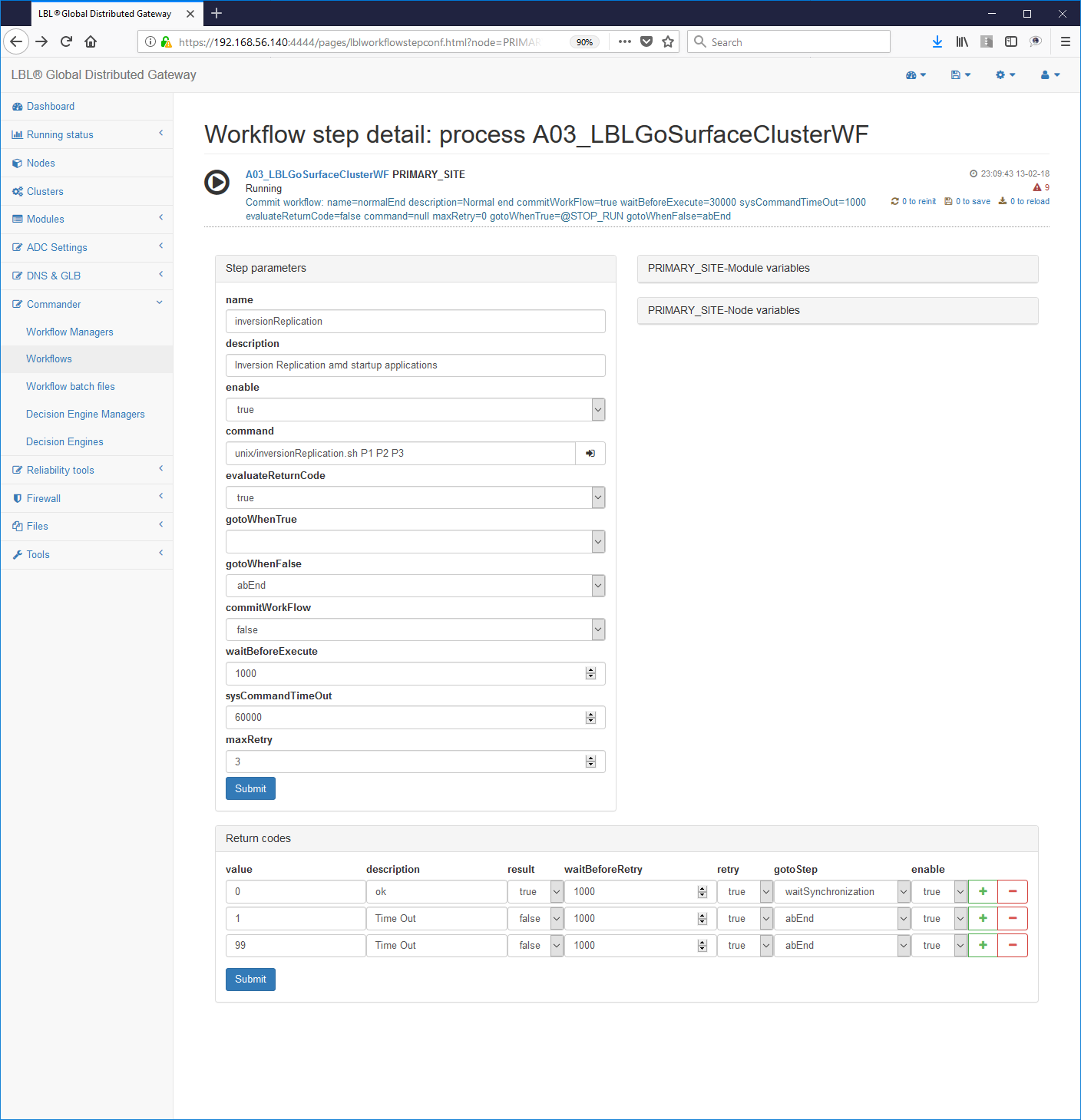
Edit
Oplon Commander Work Flow implement batch files
The first step therefore in the implementation and installation of a Work Flow is the analysis of the steps to be performed and then the writing and testing of the single steps and then move on to their insertion in a stream work.
For our purposes we will copy any distributed batch to:
MS Windows
cd (LBL_HOME) procsProfilesA03_LBLGoSurfaceClusterWFsurfaceClusterWFCommandDir
copy selfTest.bat tomcatStartup.bat
Unix/Linux
cd (LBL_HOME)/procsProfiles/A03_LBLGoSurfaceClusterWF/surfaceClusterWFCommandDir
cp selfTest.sh tomcatStartup.sh
For both platforms, but especially on MS Windows, it matters make sure that commands executed in batch files do not execute exits autonomous, implicit or explicit. To do this test it is enough use a single exit point in your batches and check with appropriate notification of the passage (common practice of good programming).
In our specific cases we will populate our new batch files with the start operations for Tomcat.
Here are the start files with the command lines highlighted used to start and stop tomcat instances.
MS Windows tomcat startup:
In this case, during the tests we noticed that the tomcat start in Windows environment always returns 1 even if the operation was successful end.
Performing the operations from the command line you will get the following result:

With the limitations of these examples and at the conclusion of this chapter we can see that we have begun to write our library of reusable "objects" on different platforms for different projects. It now remains to determine the use of these objects within logical workflows.
Oplon Commander Work Flow build Work Flows
Once the detailed tests of the basic commands have been completed and performed for the realization of our workflows remains to be implemented the context logic in the Work Flows we want to achieve.
Workflow parameterization starts from the setting of the address where the commands will be accepted: Typically it should not no changes can be made because the system is already set up to accept commands in the management address.
Commander-> WorkFlow Managers -> Choice of workflow
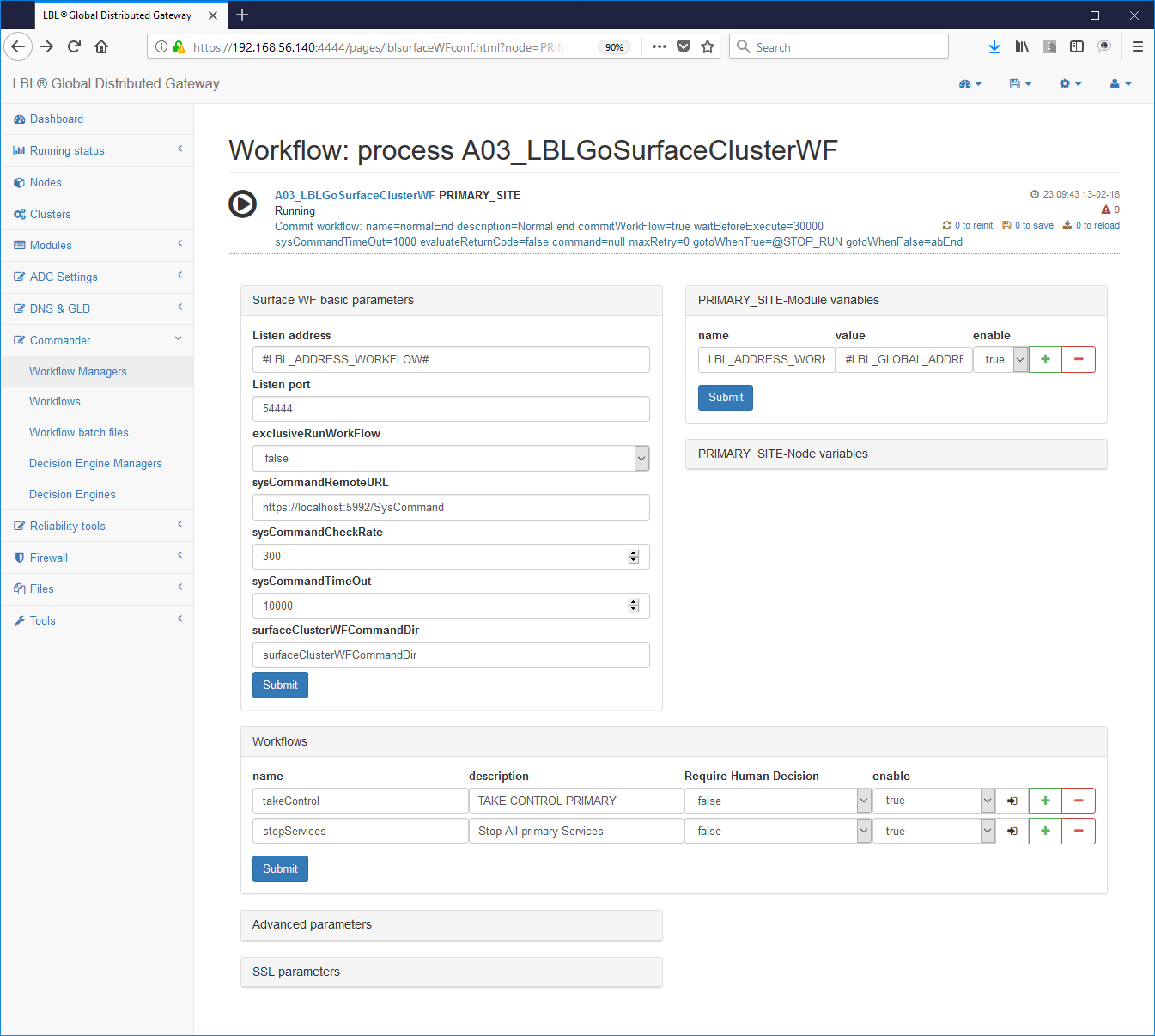
Another interesting value is the value: exclusiveRunWorkFlow = "false"
This parameter indicates whether the entire Work Flows Engine can have in the same time plus Work Flow in running state. For our purposes setting to "false", ie more Work Flows can be launched simultaneously is the correct option. It is to be remembered that however the Work Flows Engine does not allow, regardless of this parameter, to launch the same Work Flow at the same time. In other words if the Work Flow with name normalPrimer in the state of Running is not it can be cast further while it can be cast at the same time the Work Flow gracefulShutdown. Just in case exclusiveRunWorkFlow = "true" and the Work Flow was set normalPrimer were in the state of Running we would not be able to launch no other Work Flow including gracefulShutdown, until the end of normalPrimer.
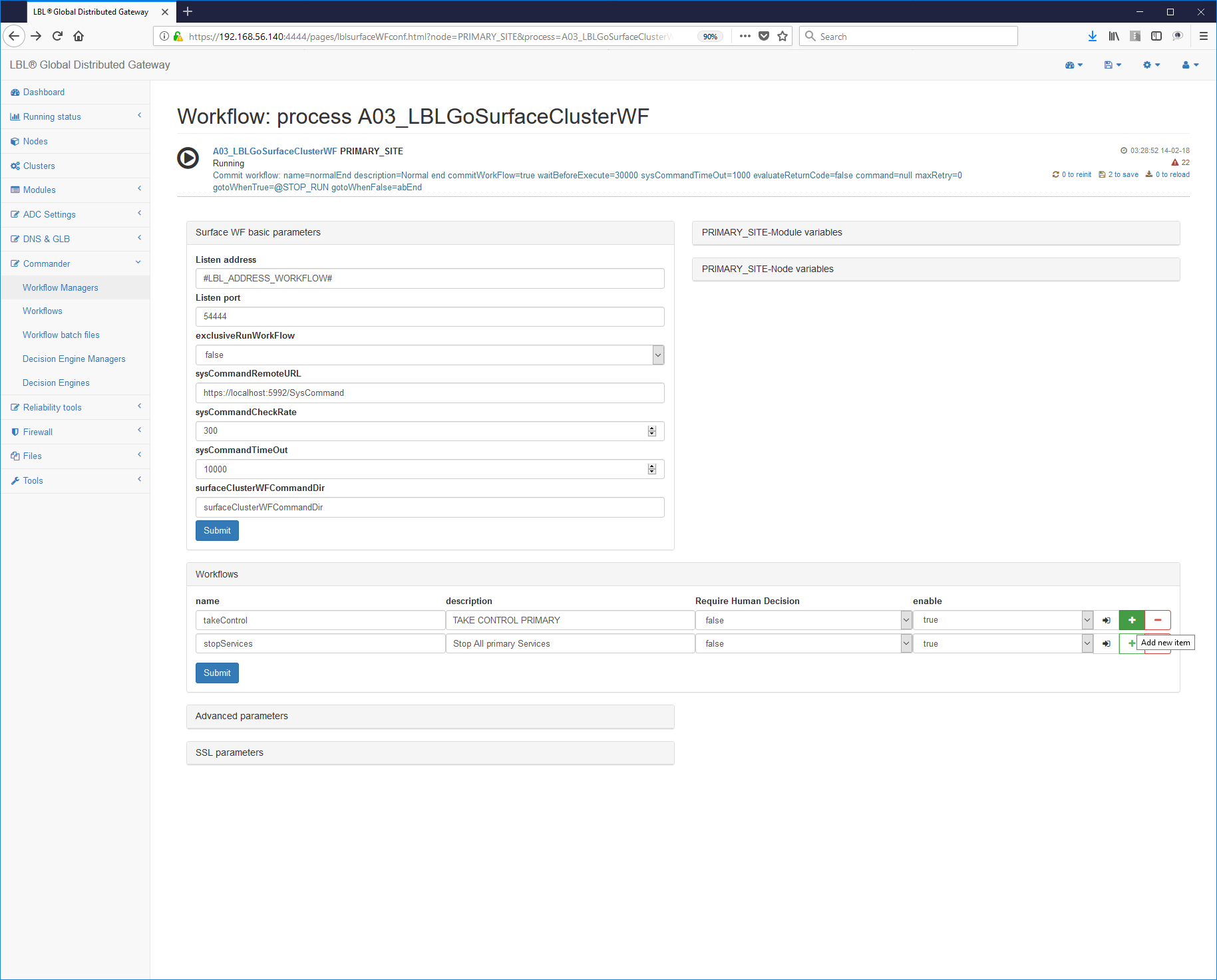
Once finished setting to be able to make accessible from outside the use of the Workflow system is passed to the paragraph next that contains the Work Flows with the actions divided into single ones step.
In our case we will have to have two Work Flows to be able to start and stop the Tomcat process as per the specifications we set ourselves initially.
The final result for the start must be similar to what is described
below where in the chapter <workFlow> you can see the parameters
name = "normalPrimer", the name of that particular work flow, the
brief description and the name of the step with which to start the flow
job startName = "startupTomcat":
The parameters related to each step are quite intuitive and therefore there we will focus only on some of them. A complete discussion of each single parameter and their behavior can be found in Reference Guide.
The significant parameters to dwell on are the command to come executed in step command = "tomcatStartup.bat", and step "normalEnd" with the parameter commitWorkFlow = "true".The latter parameter indicates that the step is a point of consistency and therefore not will produce log after the first time. In this case the step enters a loop with no way out and this is a deliberate behavior. As we will see later this behavior was exploited for not give the possibility of double execution of the same workFlow in the same moment. It is good practice in production to loop the workFlow periodically carrying out a HealthCheck of the service, for example through wget in this case, and exit to return code with any remedial actions such as a restart or reporting of the problem.
From now on you can start Oplon Commander Work Flow e check the effect. In order to be viewed from the Web Console you must have set up the monitor.xml file with references to the server Oplon Commander Work Flow you want to view as specified in the paragraph seen above.

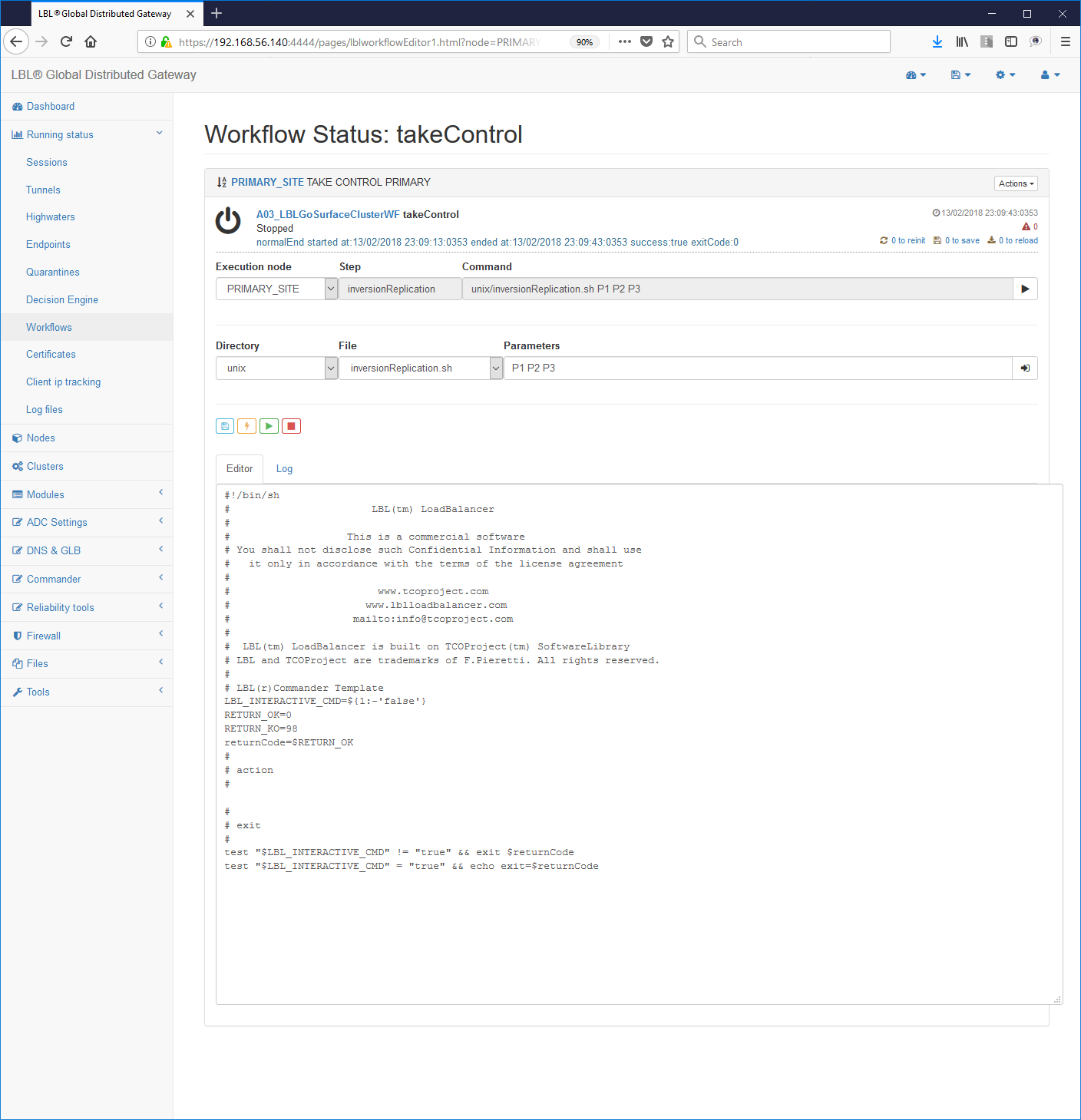
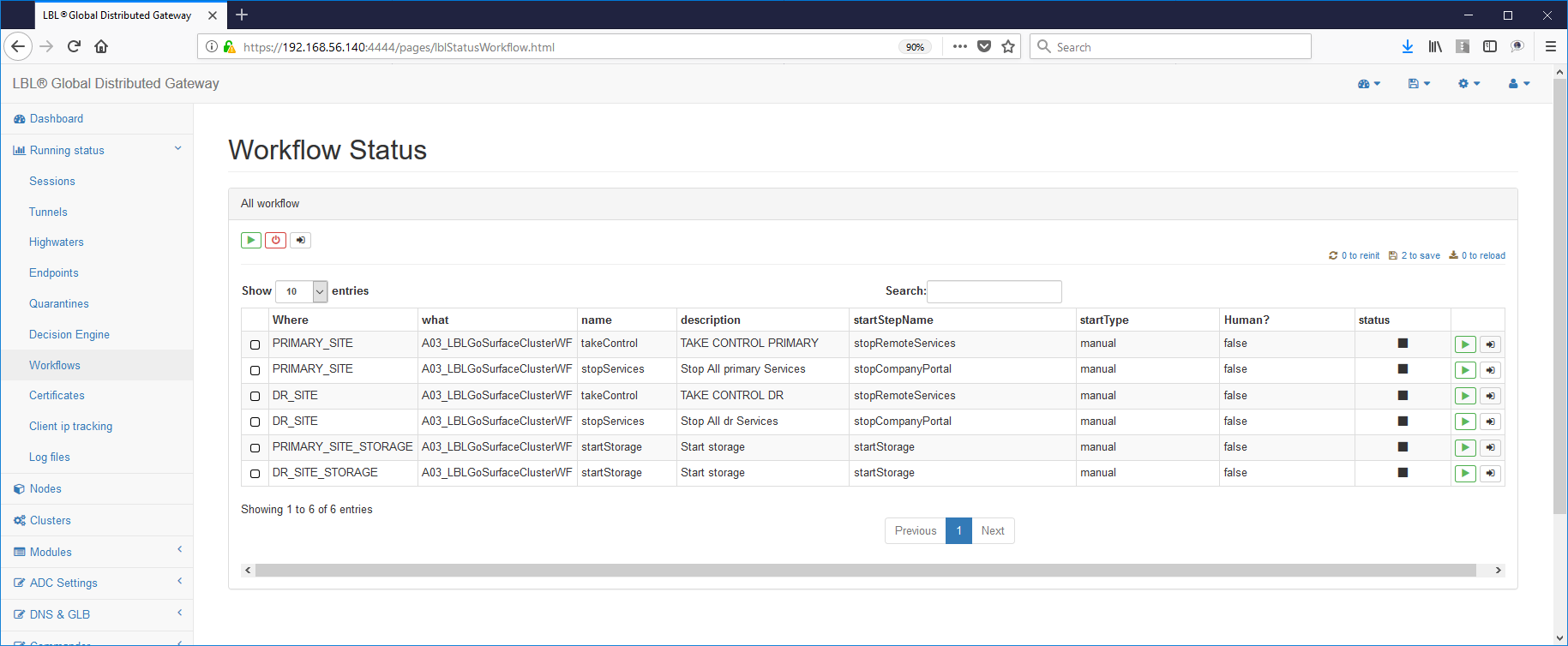
By following the HiperLinks it is possible to check the path step by step carried out by Work Flow once started:
It is recommended already from this moment to run to verify it the effects and functioning. In case of complex Work Flow it is You can run the run one step at a time using the button "Step action" on the right of each step.
If the tests of this first Work Flow have been successful it is possible move on to the development of the next Work Flow for the execution of the controlled shutdown of the Apache Tomcat service.
Through its administration interface by executing the Stop e the Start of the process Oplon Commander Work Flow can be managed also this new Work Flow.
Following the Hyperlink of the new Work Flow it is possible to verify the route:
In a very simple way it is now possible to remotely manage the start and stop the Apache Tomcat process.
Oplon Commander Work Flow distribuited events (@RWC)
From version 7.1 it is possible to perform within one step in one workflow an additional remote start workflow command (@RWC). This functionality allows the "Commander Work Flow System" to perform of distributed operations. With this functionality it is possible then propagate a WorkFlow process from the highest to the lowest layers o vice versa on different platforms to perform operations articulated on all the components that make up the application. There application availability is in fact the sum of the availability of many layers, from data availability, storage systems to mass, the availability of database services, the availability of directory services up to the availability of services applications provided by the application servers and the availability of connectivity.
These services are on physically separate systems, sometimes too geographically, and therefore the need to "govern" arises distributed but coordinated all these elements. Let's think for example of induce a targeted application restart. To perform a this type must identify the resources that contribute to return the service is available and therefore once determined which is the component in "failure" check the possibility of restoring operation. Such a complex activity must be governed by well-defined and proven procedures so that they can be scientifically repeatable. With the introduction of the functionality @RWC in one step of a WorkFlow is possible from a main WorkFlow perform these operations in a Centralized, Targeted, Localized, Automated.
-
Centralized Centralized because in a single Oplon Commander Work Flow Server it is possible to indicate management WorkFlows that trigger WorkFlow on remote systems.
-
Targeted It is possible to define specialized WorkFlows to trigger maintenance actions on individual services
-
Localized Each individual WorkFlow system locates its own management of the application life cycle
-
Can be automated Through Oplon Commander Decision Engine it is possible automate all operations to provide Business services Continuity and/or Disaster Recovery.
Also in this case, particular attention must be paid to ease of implementation and use with documented traceability e implied.
To perform an @RWC operation, simply enter in
"command" parameter of a paragraph <step> the reserved keyword
@RWC followed by indications of where you want to execute the command
(hostName) and what you want to do (workFlow). If so, then
execute the RWC of "startHealthCheckAndRestart" on the "dbserver" system
it would be sufficient to indicate:
command = "@ RWC hostName = dbserver workFlow = startHealthCheckAndRestart "
The login and password are not present because they use Oplon Autonomous Delegated Authentication.
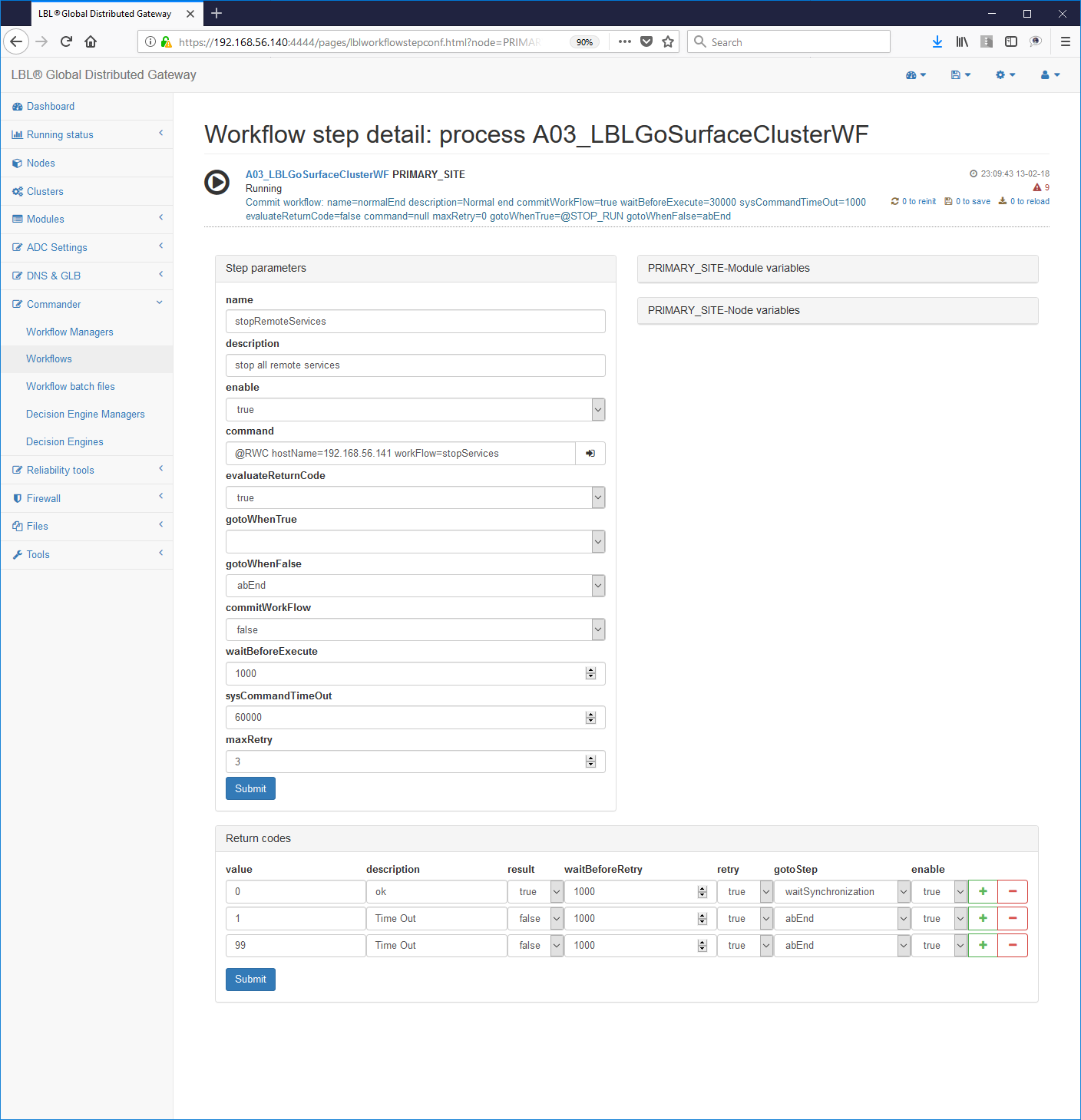
The login and password parameters will also be used in the future for execute new Inner Command.
The complete parameterization of the @RWC command allows you to execute all start operations, from the start of an entire WorkFlow to start of a WorkFlow starting from a pre-established Step at the start of a single step.
The complete command with all parameters is as follows:
@RWC hosname = system name or target address of the RWC [portNumber = system port number of SCWF] default 54444 [uriPath = Uripath of the SCWF system] default/SCWFCommand workFlow = workflow name [step = name of the step to be launched, if "" from the first] default [command = runWorkFlow | stopWorkFlow] default "runWorkFlow" [frhd = if true it executes only the indicated step] default false
Ex. 1: start workflow from the secondStep step
command = "@ RWC hostName = dbserver workFlow = startHealthCheckAndRestart step = secondStep "
Ex. 2: start workflow of the second step only
command = "@ RWC hostName = dbserver workFlow = *startHealthCheckAndRestart step = secondStep frhd = true "
It is useful to note that launching an @RWC on remote systems does not produces a significant return code. @RWC reports as an error only if it fails to produce a start of the procedure. Every remote procedure must be self-consistent by design so that only the application availability is the discriminating factor of functionality.
Oplon Commander Work Flow Remote Batch
This service allows you to start remote batches for run HealthChecks deployed safely. It consists of a service Web, which responds by default to port 5994, can interpret a profile xml file for launching executables or batch files.
The installation must include the following steps:
1- Check that the Oplon Commander license has been set Work Flow
(LBL_HOME) /lib/confSurfaceClusterWF/license.xml
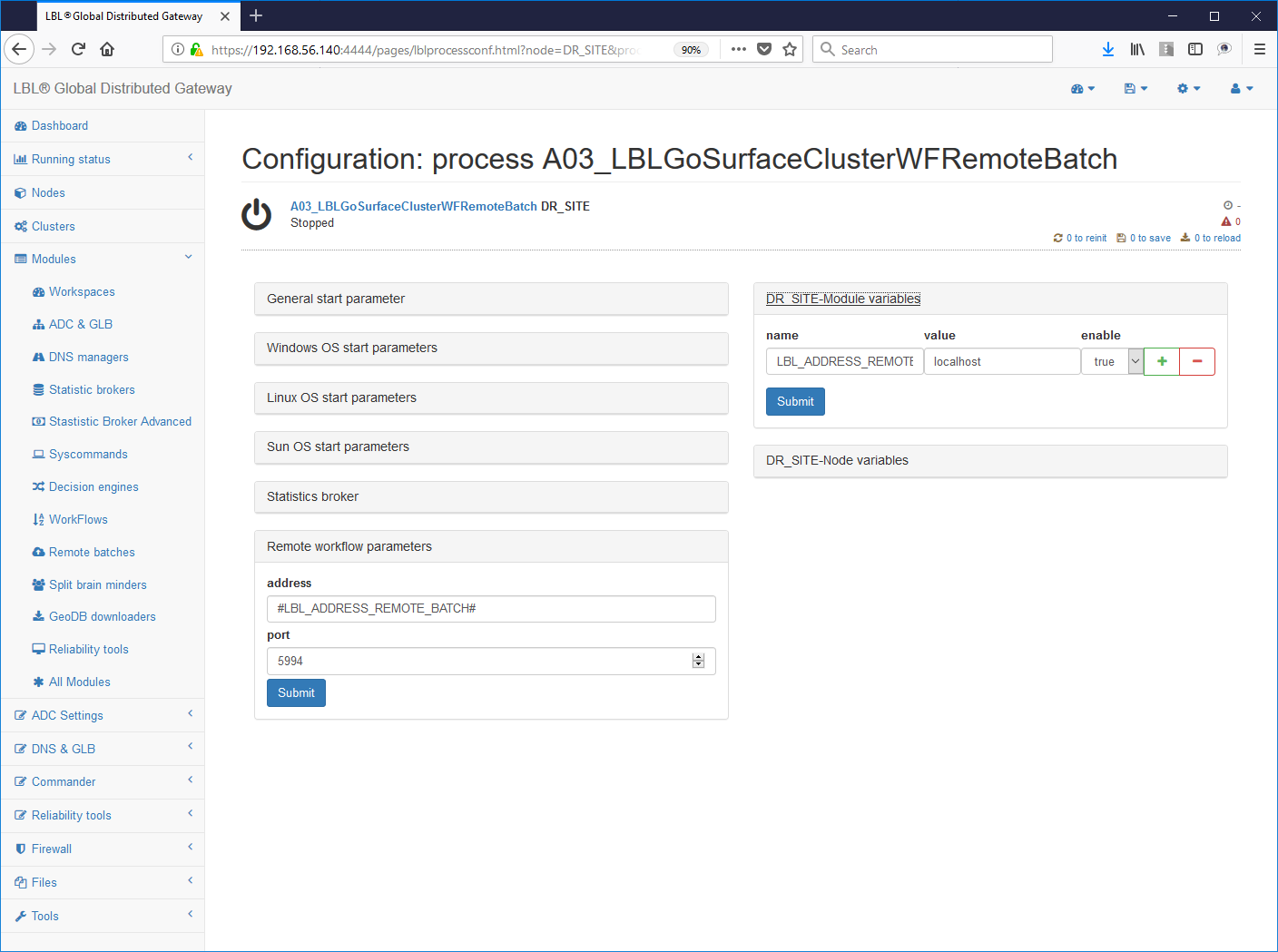 2 - Setting The configuration of the
service
2 - Setting The configuration of the
service
3 - Start the service checking the log with the success listen to the port address indicated:
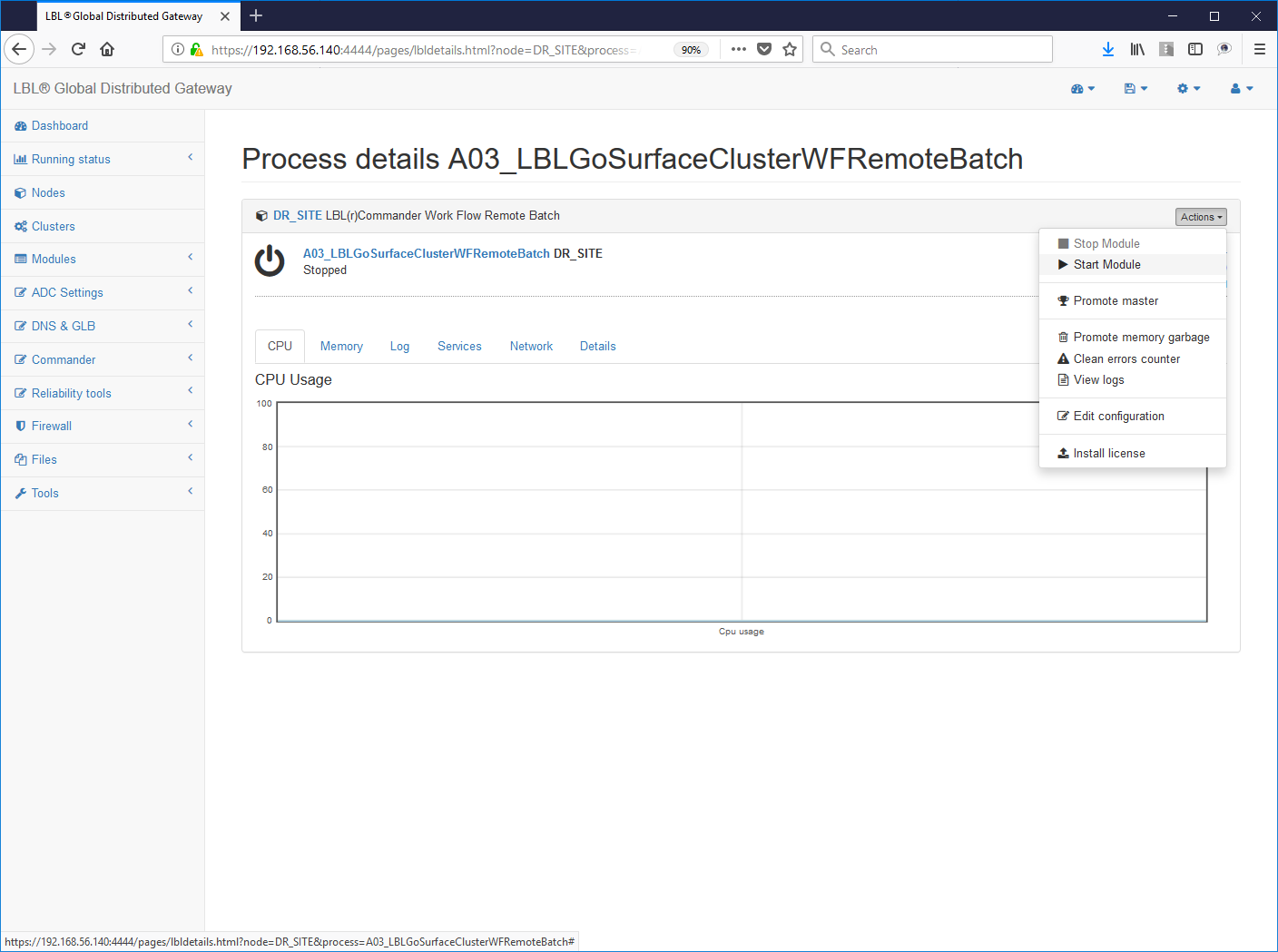
4- Batch writing and verification
Example vai.bat (windows systems):
echo% 0% 1% 2% 3% 4 >> C: logvai.txt
AA =% 1
exit 0
Example vai.sh (UNIX/Linux systems)
echo startBatch $ @ >>/tmp/logStartBatch.txt
exit 0
5- Setting the launch profile in
(LBL_HOME)/lib/webroot_remotebatch/webapps/RemoteBatch/
The profile file has the following format:
<startBatch>
<params remoteBatchTimeOut = "10000"
remoteBatchCheckRate = "300"
allowURIParams = "false" debug = "false" />
<legacyCommand> T: work0tmpvai.bat 11 </legacyCommand>
</startBatch>Being interpreted at the time of the recall, exactly as one HTML page, whose values can be dynamically changed a hot.
The file name must be the same as the main paragraph. In case described above, the file must be called startBatch and have a extension like: xml; txt, etc. (mime type text/html).
The parameters are very few and quite intuitive. Below is one detailed description. For further information on the single parameter yes refers to the Reference Guide documentation.
remoteBatchTimeOut =: default value "10000"
This is the time to wait before releasing the batch/executable process.
remoteBatchCheckRate =: default value "300"
It is the waiting time between one attempt and the next after waiting
remoteBatchTimeOut. After 3 attempts the batch launch comes declared bankrupt.
allowURIParams =: default value "false"
If true it allows to insert further parameters from URI. The default is false for security reasons. If not set or set to false any parameters set in the URIPath will be ignored.
debug =: default value "false"
if true it executes a log warning with the start values of the process and del result obtained.
<legacyCommand> =: default value "null"
It is the batch to be launched. For security reasons this value does not it can be empty.
The batch will be launched by requesting a URL that reports the name of the descriptor file to be interpreted for launching the batch/executable.
It is possible to indicate further parameters during the launch of the program in the URL itself as in the example below:
http://localhost:5994/RemoteBatch/startBatch.txt?parameters=2222 (opens in a new tab) 3333 4444
In this case the launch of the batch will be composed as follows in the part parameters:
T: work0tmpvai.bat 11 2222 3333 4444
A simple one can be used to verify the execution of the batch browser and set the address e.g .:
http://wileubuntudbenchbackend:5994/RemoteBatch/startBatch.xml (opens in a new tab)
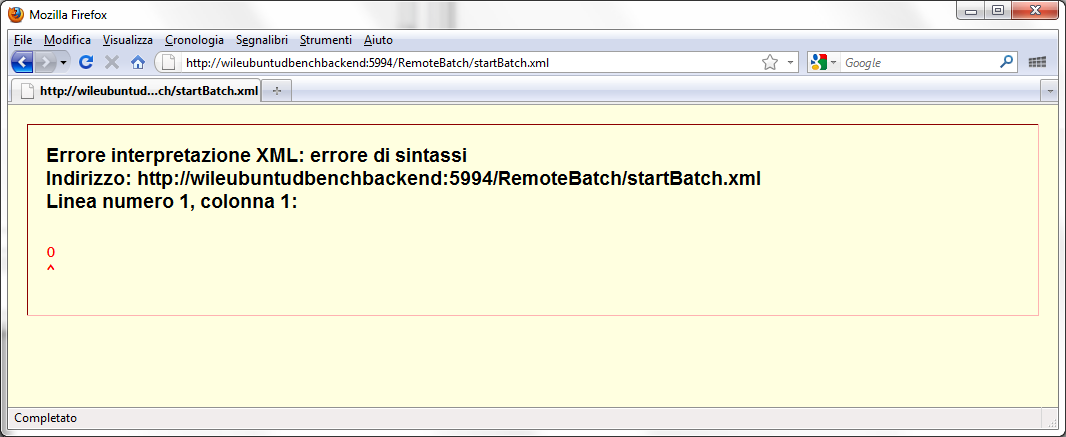
The XML interpretation error is related to the message body that it only reports the return code of the batch/executable. By code return equal to 0 the HTTP Response Code will be 200 OK. By codes batch return/executable other than 0 the HTTP response code it will be 500 Internal Server Error.
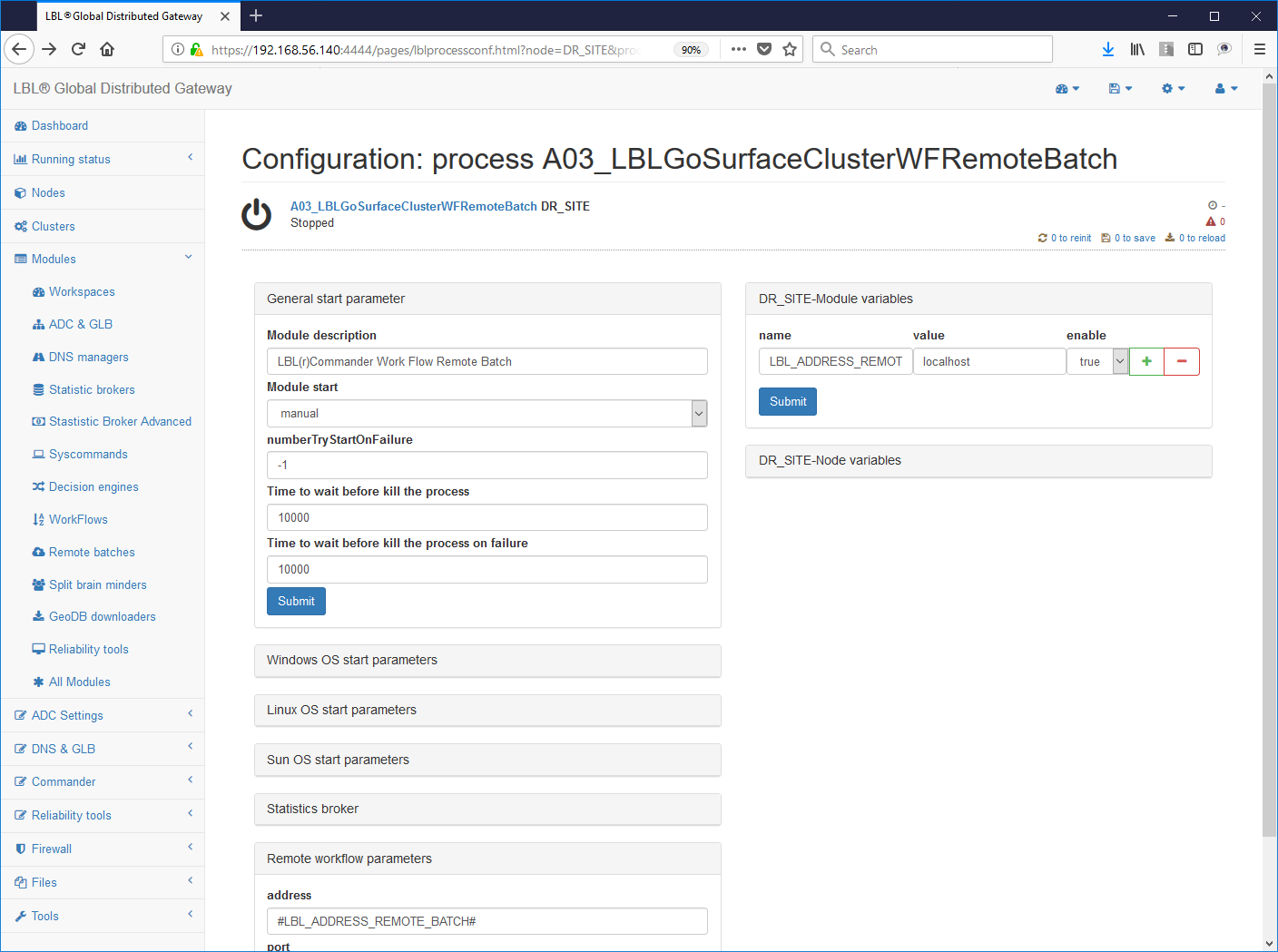
6 - Setting the automatic start of the service (from "manual" to "automatic")
Oplon Commander Work Flow with Decision Engine
Oplon Commander Work Flow can be coupled to features Oplon Commander Automatic start decision engine coinciding with application failure events.
By default Oplon Commander Decision Engine uses 3 Work Flow which they distinguish the start, stop and switch processes of an environment operating.
The three moments have been identified in:
- normalPrimer
normal startup of applications on the root node
- gracefulShutdown
stop of applications in controlled mode. This operation comes triggered by Oplon Commander Decision Engine on the node/site where it is A failure event was detected before taking control to another node/site. This is to be considered an attempt as the node/site may no longer be available.
- takeControl
is the set of processes that must be started in a node/site secondary to take application control.
N.B .: From version 7.1 it is possible to identify an intermediate moment between the detection of the damage and the decision of perform a service move. This moment, called restartWorkFlow was implemented to run, before the moving services, a restart in the primary site of the components which are believed to be more subject to criticality in an infrastructure. In fact, very often the controlled restart of the components only criticism allows to have a very low impact in operations and a better management of critical events without resorting to moving operations on another site/system with consequent subsequent action to restore operations.
These moments, hereafter called workFlow, must be available in order to use Oplon Commander Decision Engine. THE individual Work Flow names can be changed according to need. It is also important to know that an Oplon Commander instance Work Flow can contain these actions multiple times with different names based on to applications that you want to control from different Oplon Commander Decision Engine. In other words, if more than one coexist in a node application areas in different contexts and if you want to drive them separately the possibility of fail-over is enough to insert additional Work Flows with different names for performing actions related to that application area.
If you want to proceed with the installation of Oplon Commander Decision Engine it is therefore necessary to insert a new Work Flow to the two already created in the previous chapters: takeControl.
In this case of minimum this new Work Flow will be exactly the same to normalPrimer and that is it will trigger the start of Apache Tomcat. In distribution there are some examples, similar for systems Unix/Linux and MS Windows operating systems. The examples are a "template" on the which to build your own implementations.
You must then proceed with the creation of the "takeControl" Work Flow to then be able to use it as an event by Oplon Commander Decision Engine.
Below is the fragment of the surfaceclusterwf.xml file with the Work Flow takeControl:
After performing stop and start of the server Oplon Commander Work Flow the final result should look like this example:
In an environment with two mirrored nodes it is sufficient to execute image installation Oplon Commander Work Flow by running a zip of the directory (LBL_HOME) and then modify only the references to the host.
Oplon Commander Decision Engine introduction
Oplon Commander Decision Engine is a geographic cluster designed for automate Fail-Over operations in environments mission-critical. This module can be thought of as the module "thinking" to automate the management of procedures (Work Flow d'ora forward) placed on other Servers both locally and within geographical. Oplon Commander Decision Engine works in cooperation with Oplon Commander Work Flow for starting Remote Workflow Command (RWC).
The general architecture can be summarized in the following scheme:
The flexibility of the instrument can be expressed in different architectures. Below is another example of possible architecture where the Oplon Commander Decision Engine and Work Flow components are on same machine in each node/site ....
... or a Disaster Recovery scenario with take-over automatic...
Oplon Commander Decision Engine address/resource plan
The design of an infrastructure based on Oplon Commander Decision Engine is structured in the following fundamental aspects:
-
Identification of the resources that identify the public network
-
Identification of the resources that identify the backend network
-
Identification of the other decision-making engines that contribute to quorum
-
Identification of Application resources
These four elements lead us to develop a plan of addresses/application resources that describe the operational context.
The first table of the address plan serves to identify addresses/services that can be targeted for the determination of the reachability of the public network. The number minimum recommended target is 3 (three) the optimal is 5 (five). There logic is that if all targets are not reachable then the network public is declared "down". An example of a table addresses/services is summarized below:
The HealthCheck manager was designed to handle several HealthCheck mode based on the parameters that are provided. Self it is given only the Address parameter it will "ping" if the the "port" parameter is also provided will perform a connect e disconnect TCP/IP, if we also give it the URIPath it will perform a GET HTTP and will check the response-code which should be 200 (OK) for finish correctly. You can also indicate whether the service HTTP target is in SSL mode with one more parameter.
Public Network Health Check Address Port Number URIPath SSL Description 192.168.43.143 System A1 public 192.168.43.146 System A2 public 192.168.43.151 System A3 public
A similar table needs to be filled in for backend services:
Backend Network Health Check Address Port Number URIPath SSL Description 192.168.45.143 System A1 public 192.168.45.146 System A2 public legendonebackend 54444 /HealthCheck true Commander WF A.A legendtwobackend 54444 /HealthCheck true Commander WF B.B
In the latter example you can observe more health checks complex in HTTPS related to the services Oplon Commander Work Flow that they will be used for the automation of procedures.
The next table identifies the other decision engines that compete for the Quorum. The decision-making Quorum, ie the conditions that allow an instance Oplon Commander Decision Engine to be able making a decision is related to the possibility of reaching at least one other Oplon Commander Decision Engine. In case it wasn't no other Oplon Commander Decision Engine node reachable would declare isolated and therefore unable to make a decision autonomous. The table describing the other decision engines (peers) will have the following form:
Oplon Commander Decision Engine peers URL Description https://legendoneprivate:54445/ (opens in a new tab) HalfSite A https://legendtwoprivate:54445/ (opens in a new tab) HalfSite B https://legendquorumprivate:54445/ (opens in a new tab) Quorum Site
The number of Oplon Commander Decision Engines must be three (3) for the determination of the quorum. Fewer Oplon instances Commander Decision Engine would lead to not deciding in the absence of one of the two instances and a higher number could lead to having some decisional islands (split brain decision making). Another consideration is relating to the Heart-Beat network which does not necessarily have to be private but can be shared with other applications being able to arrive to work also in the geographical area (internet).
Each node's configuration files will always report only two (2) of the three references in the table, never having to report the reference to himself.
Oplon Commander Decision Engine Web Console
Oplon Commander Decision Engine requires one or more consoles, minimum 2 in mission-critical environments, in order to be managed. It's possible use the same administration console as the installation Oplon Commander Decision Engine or, as in the drawing, use other Oplon Monitor instances located in different servers used for administrative consoles. Both consoles can be managed from the same consoles Oplon Commander Decision Engine instances than Oplon instances Commander Work Flow.
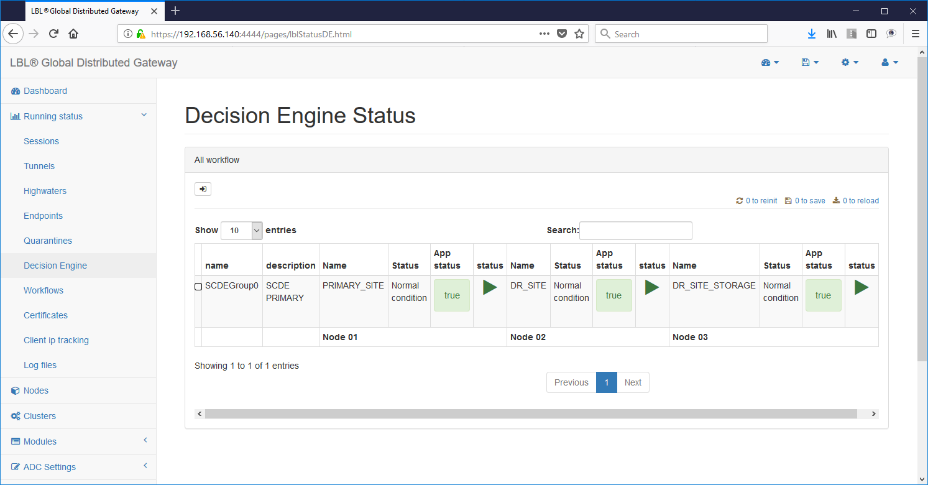
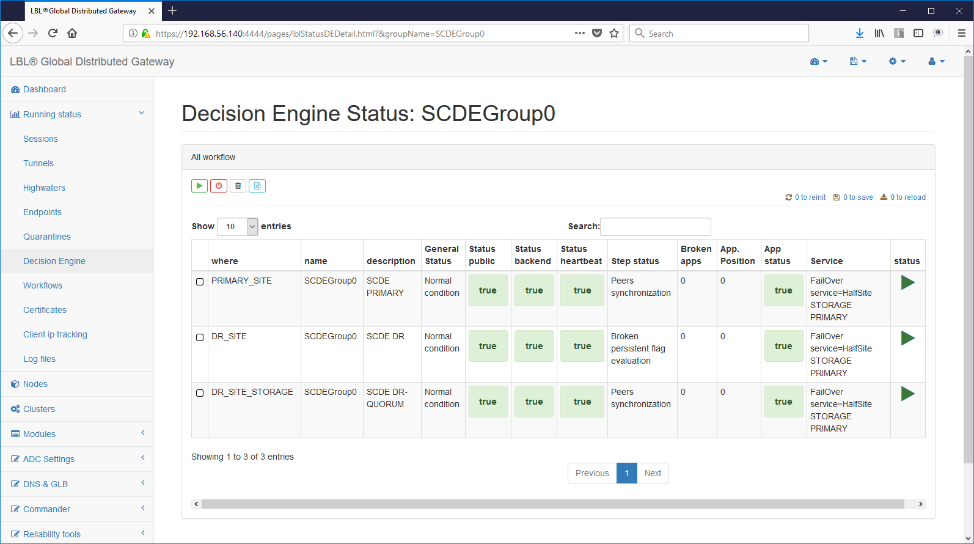
Oplon Commander Decision Engine directories and files
Oplon Commander Decision Engine uses only 3 directories and one configuration file if we exclude the license file.
The default directories are:
(LBL_HOME)/procsProfiles/A03_LBLGoSurfaceClusterDE/conf
(LBL_HOME)/procsProfiles/A03_LBLGoSurfaceClusterDE/surfaceClusterDEStatus
(LBL_HOME)/lib/notificationDir
-------------------------------------------------------------------------------------------------------------
(LBL_HOME)/procsProfiles/A03_LBLGoSurfaceClusterDE/confContains the license and configuration file
surfaceclusterde.xml
(LBL_HOME)/procsProfiles/A03_LBLGoSurfaceClusterDE/surfaceClusterDEStatus
It is the default directory for persistence of status flags. In this directory creates the files that identify the resources declared down and therefore no longer usable even after a subsequent one restart of the decision engine or of the whole system.
(LBL_HOME)/lib/notificationDir
It is the notification directory to Oplon ADC of the unavailability of the service. It is handled automatically by Oplon Commander Decision Engine by creating a file with the following characteristics:
outOfOrder.SCDEGroup_00000
| | +-------------- Numero identificatore della
sequenza di
| | Fail-Over in ordine di inserimento.
| | Questo valore deve essere inserito
| | nell'apposito parametro
| | <endp associateName="SCDEGroup_0000"...
| | in iproxy.xml
| +--------------------------------
Nome del gruppo del Cluster di controllo
| dell'applicazione
+------------------------------------------------
Identificatore di notifica Out Of OrderOplon Commander Decision Engine surfaceclusterde.xml
Once the collection of environmental data has been completed, you can start set up the Cluster configuration file.
Configuration files setup must be done on all three nodes where the Oplon Commander image was installed Decision Engine through one of its distributions.
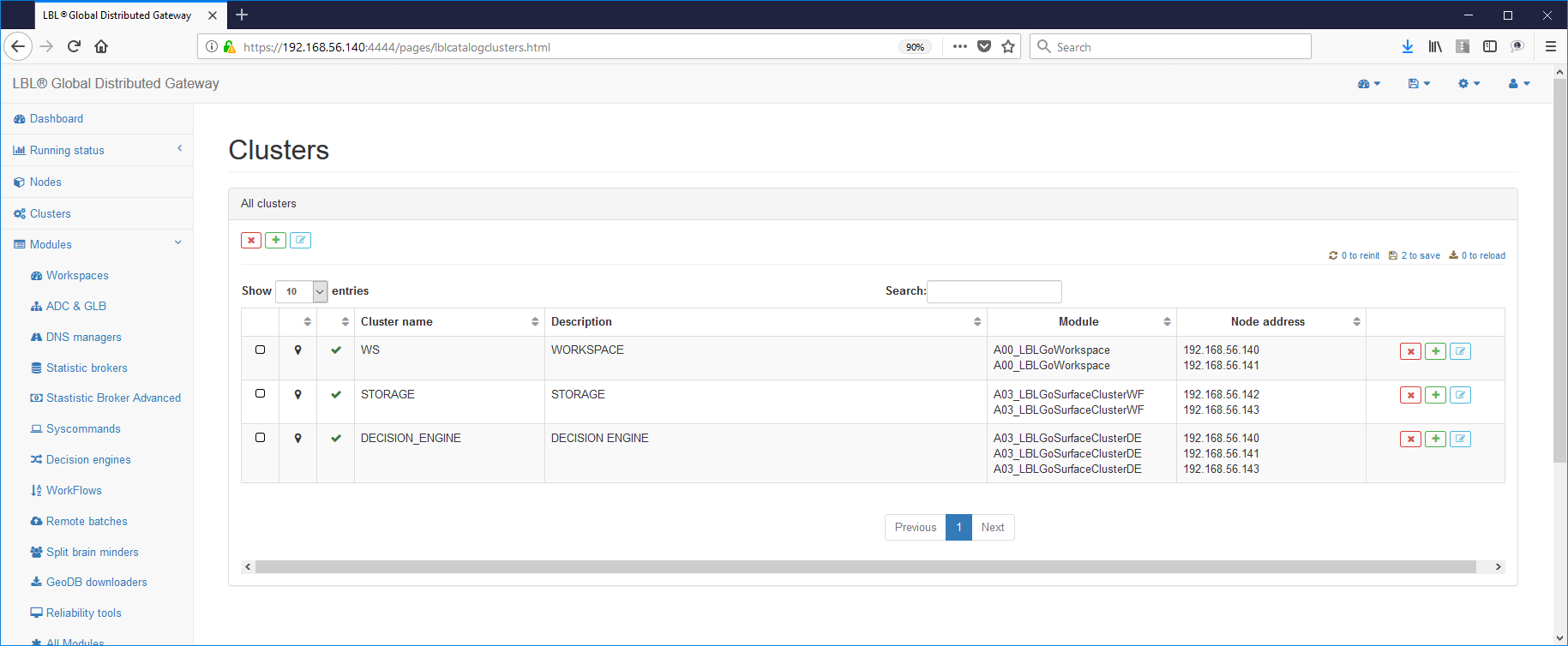 The first operation to be performed is therefore
cluster all decision engine modules and act on variables
to differentiate behaviors:
The first operation to be performed is therefore
cluster all decision engine modules and act on variables
to differentiate behaviors:
The file contains two main paragraphs, one for managing the Server Oplon Commander Decision Engine while the others are functional to the management of application clusters.
The following page shows the paragraphs highlighted with a
blue frame for the parameters relating to the management of the Oplon Server
Commander Decision Engine and in red the paragraphs relating to
management of a single Application Cluster. It is possible in the same
Oplon Commander Decision Engine manage multiple Clusters simply
duplicating the paragraph <decisionEngine> and setting a different
groupName with the name of this new cluster.
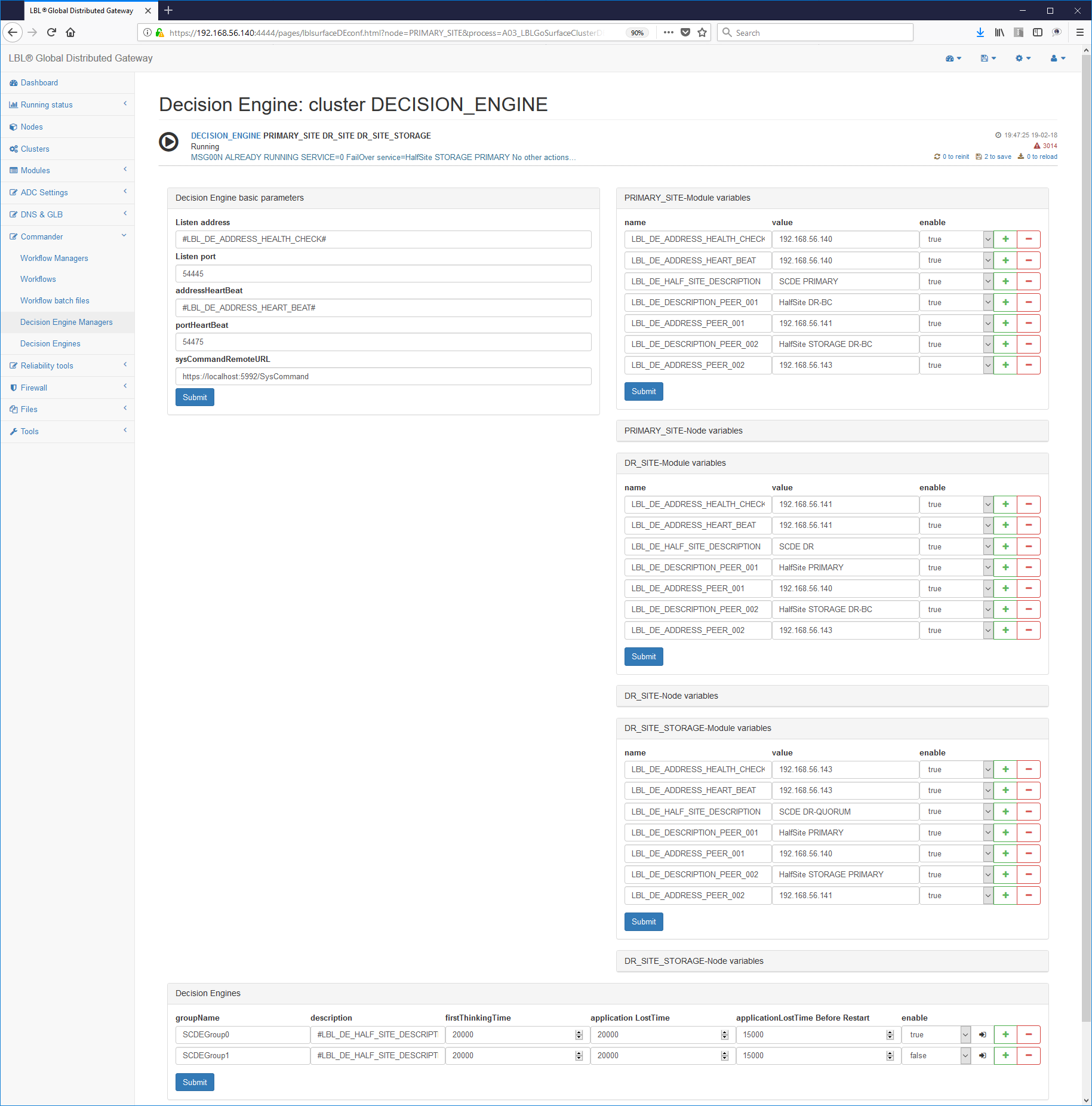
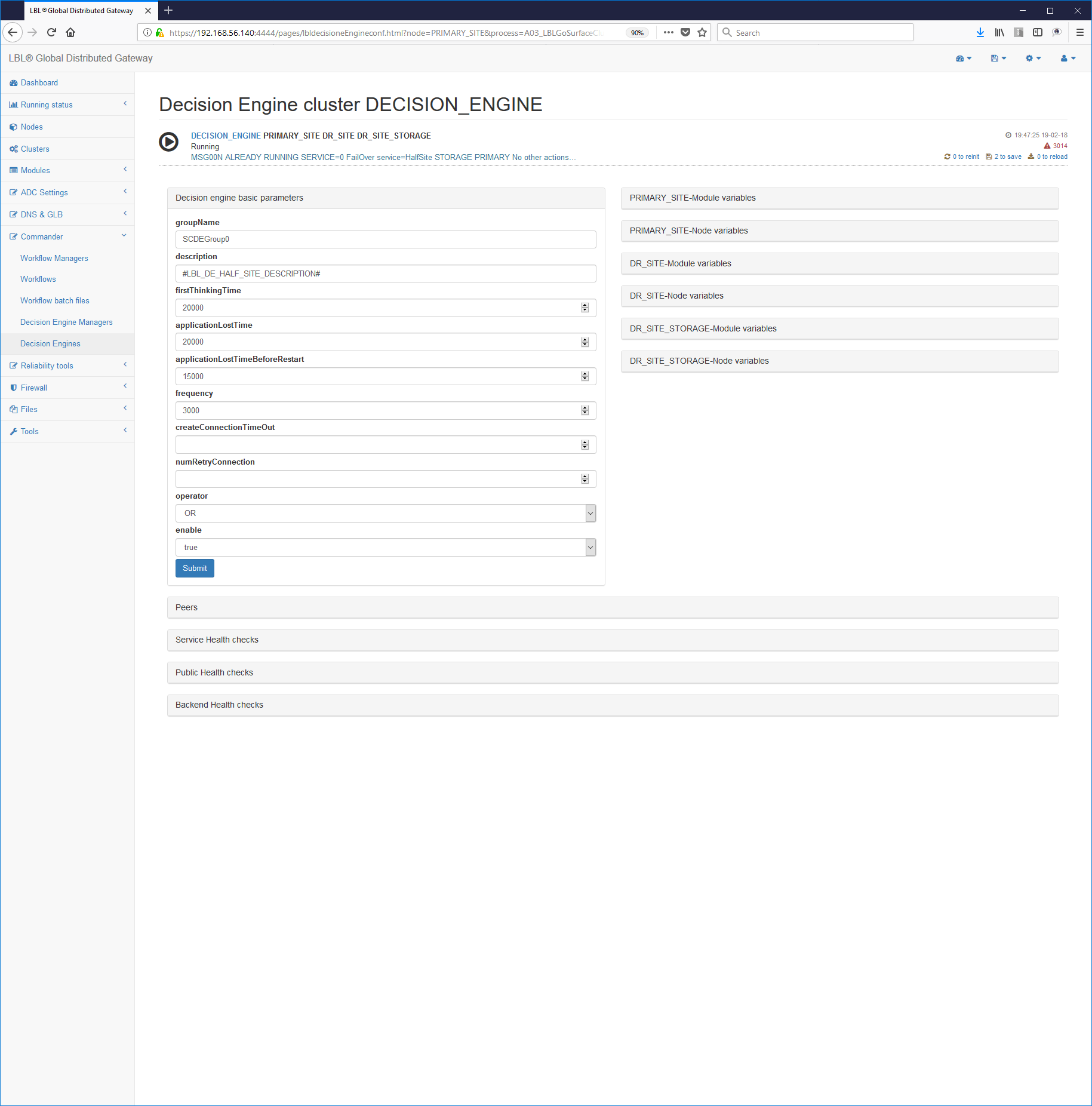
The setting of the first paragraph provides for the setting of addresses for Server management and remote control.
Below what is proposed in the distribution for the paragraph
<params>:
frequency is the frequency of checking the status of the cluster.
address is the public address on which to perform the operations check while addressHeartBeat is a second address, normally afferent to the HeartBeat network, for operations between peer nodes. The two addresses can coincide and in this case it is necessary change the door for coexistence.
Once the general parameters have been set, we move on to the configuration application cluster. The first paragraph to set is definitely the paragraph relating to the identification of the Cluster.
Each paragraph <decisionEngine> delimits an Application Cluster.
There can be multiple <decisionEngine> and thus multiple cluster managers
different applications at the same time.
enable=:default="false" UM=boolean
Enable or disable the interpretation of this paragraph in the instance.
groupName=: valore di default="SCDEGroup"
It is the name of the Decision Engine group. It is very important in that the decision engines contained on an instance are distinguished from this first name.
description=: valore di default="description: groupName"
It is the description of this decision engine. It must be concise but exhaustive.
frequency=: valore di default="<params frequency>"
UM=Milliseconds
It is the frequency of verification of state changes. If not specified
the frequency of the paragraph <params> is assumed
firstThinkingTime=: valore di default="45000" UM=Milliseconds
It is the waiting time for initialization and first checks. Passed this waiting time the decision engine will highlight a message. However, the decional engine does not proceed even after this time initialization and waits for the total initialization of the states.
applicationLostTime=: valore di default="30000" UM=Milliseconds
It is the waiting time since the application being tested declared in a down state. This is a very important value because exceeded this period of time and the application still appears not reachable and verified the switch quorum will trigger the recovery procedure. The 30 "is the minimum to avoid false positives.
The paragraph <decisionEnginePeers> delimits the relevant information
to the other two Decision Engines that contribute to the decisions.
The parameters are very simple and only need information related to connection and authentication.
enable=:default="false" UM=boolean
Enable or disable the interpretation of this paragraph in the instance.
URL=:default="" UM=URL W3c
It is the connection URL to the peer service through the network of HeartBeat.
description=:default="description peer: URL"
concise but exhaustive description of the service.
The paragraph relating to application services is the heart of the Cluster in what identifies the application services with the relative methods of HealthCheck This paragraph also includes the Work Flows that must be triggered for Fail-Over actions.
The parameters in the <healthCheckServicesPolicy> paragraph are relative
to management. The parameters are intuitive and taking up part of the
reference guide document and can be summarized in:
description=:default=""
General description of the service placed in high reliability.
waitTimeAfterNormalPrimer=:default="180000" UM=Milliseconds
It is the waiting time after starting the first available service (normal startup). After this time the decision engine will start check if the service has reached the activity status. In case otherwise the recovery procedures will be started. If the application goes up before this value the Decision Engine starts immediately in verification.
waitTimeAfterFlagBroken=:default="60000" UM=Milliseconds
It is the wait time after setting the persistent flag for the propagation to other peers.
waitTimeBeforeTakeControl=:default="180000" UM=Millisecondi
This is the waiting time before performing take control leave time for any graceful shutdown of the service previously active if the resource is still reachable.
waitTimeAfterTakeControl=:default="900000" (15') UM=Milliseconds
It is the wait time after take control is used to wait for the conclusion of complete take control before returning to check it activity status and then decide if it was successful or retry with another resource if available. If the application goes up before this value the Decision Engine starts immediately verification. This time varies according to the type of recovery e the amount of data if there is a database.
applicationLostTime=:default="<decisionEngine applicationLostTime>" UM=Mill
It is the wait time after take control is used to wait for the conclusion of complete take control before returning to check it activity status and then decide if it was successful or retry with another resource if available. If the application goes up before this value the Decision Engine starts immediately verification. This time varies according to the type of recovery e the amount of data if there is a database.
normalPrimerWorkFlow=:default="normalPrimer" UM=Work Flow name
It is the name of the Workflow that will be triggered if it is determined initial startup of the service.
gracefulShutdownWorkFlow=:default="gracefulShutdown" UM=Work Flow name
It is the name of the Work Flow that will be triggered if the down is determined of the service and immediately before carrying out the recovery action.
takeControlWorkFlow=:default="takeControl" UM=Work Flow name
It is the name of the Work Flow that will be triggered after starting the gracefulShutdownWorkFlow to start the recovery action.
<failOverService> identifies the services in the
their server. The order of insertion also identifies the priority of
services. The parameters proposed by the distribution template are
very few but in reality many typical parameters can be set
for this application in that particular node/site. Please refer to
Reference Guide document for a complete discussion.
enable=:default="false" UM=boolean
Enable or disable the interpretation of this paragraph in the instance.
description=:default=""
Punctual description of the highly reliable service. Yes advises, as far as possible, to use the nomenclature Oplon Surface Clsuter e.g .: HalfSite A.A rather than HalfSite B.B with the brief but exhaustive description of the service.
surfaceClusterWorkFlowURL=:default="https://"
It is the URL of the Oplon Commander Work Flow instance related to this application service.
The parameters relating to the <healthCheck> paragraph indicate the modes
HealthCheck of applications. There can be multiple paragraphs
<healthChekh> is the failure of only one of these HealthChecks
determines the state of verification of achievement of the decision-making quorum
for the switch. Obviously if at the next check and within the limits
of the applicationLostTime parameter the HealthCheck should return to
be positive all Decision Engines will return to normal verification
bringing back the critical state.
enable=:default="false"
If true this paragraph namespace is active. If false the paragraph does not is taken into account.
description=:default=""
Brief description of the HealthCheck.
address=: valore di default=""
It is the address where the health check is carried out.
port=: valore di default="0"
It is the door on which the health check service responds. If less than or equal to 0 it will come performed an ICMP check
SSL=: valore di default="false"
If set to true it performs the health check of the service through a SSL (HTTPS) connection.
uriPath=: valore di default=""
It is the URIPath on which the health check service responds. If not a connected TCP health check will be performed.
Oplon Commander Decision Engine Start/Stop/Manage Status
Oplon Commander Decision Engine is a decision engine designed for have very little maintenance and above all a very low impact operating. The management of the operations is completely entrusted to Web interfaces usable through any instance Oplon Monitor properly trained. After setting the parameters context at start Oplon Commander Decision Engine executes the initialization of the states to check the state conditions application and environment.
It is possible to check these states through the web interface:
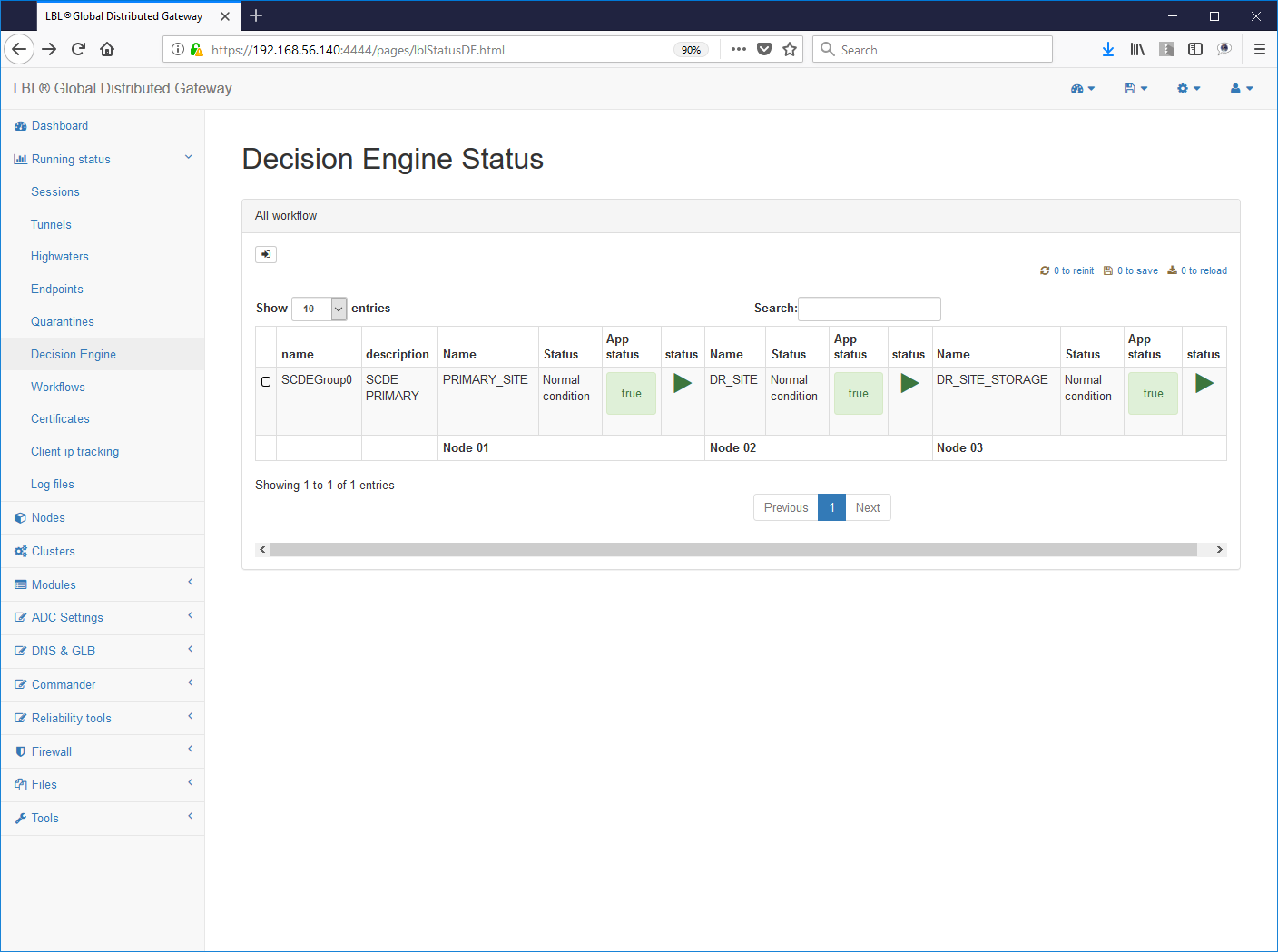
In this phase the application and control controls are started in parallel environment. Once you have finished checking the status of the Oplon node Commander Decision Engine changes giving the exact state image of the environment on which application control has been set.
Just finished initialization if all the environment was set correctly and there are no anomalies found ad a subsequent refresh will show the following situation:
No status dials should be colored red or yellow. There red color indicates an important anomaly while a coloration yellow indicates an anomaly that does not compromise the decision-making faculty.
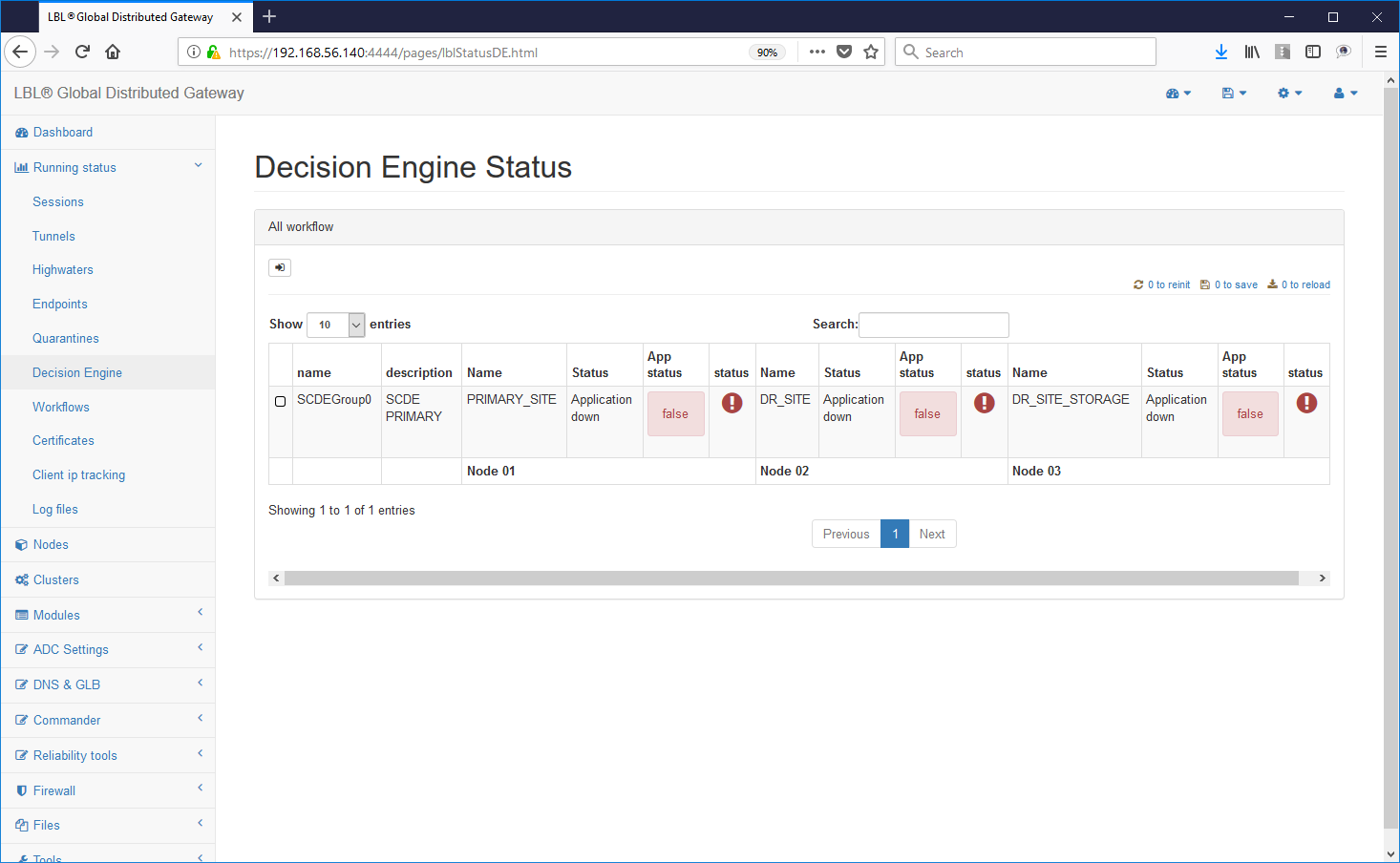
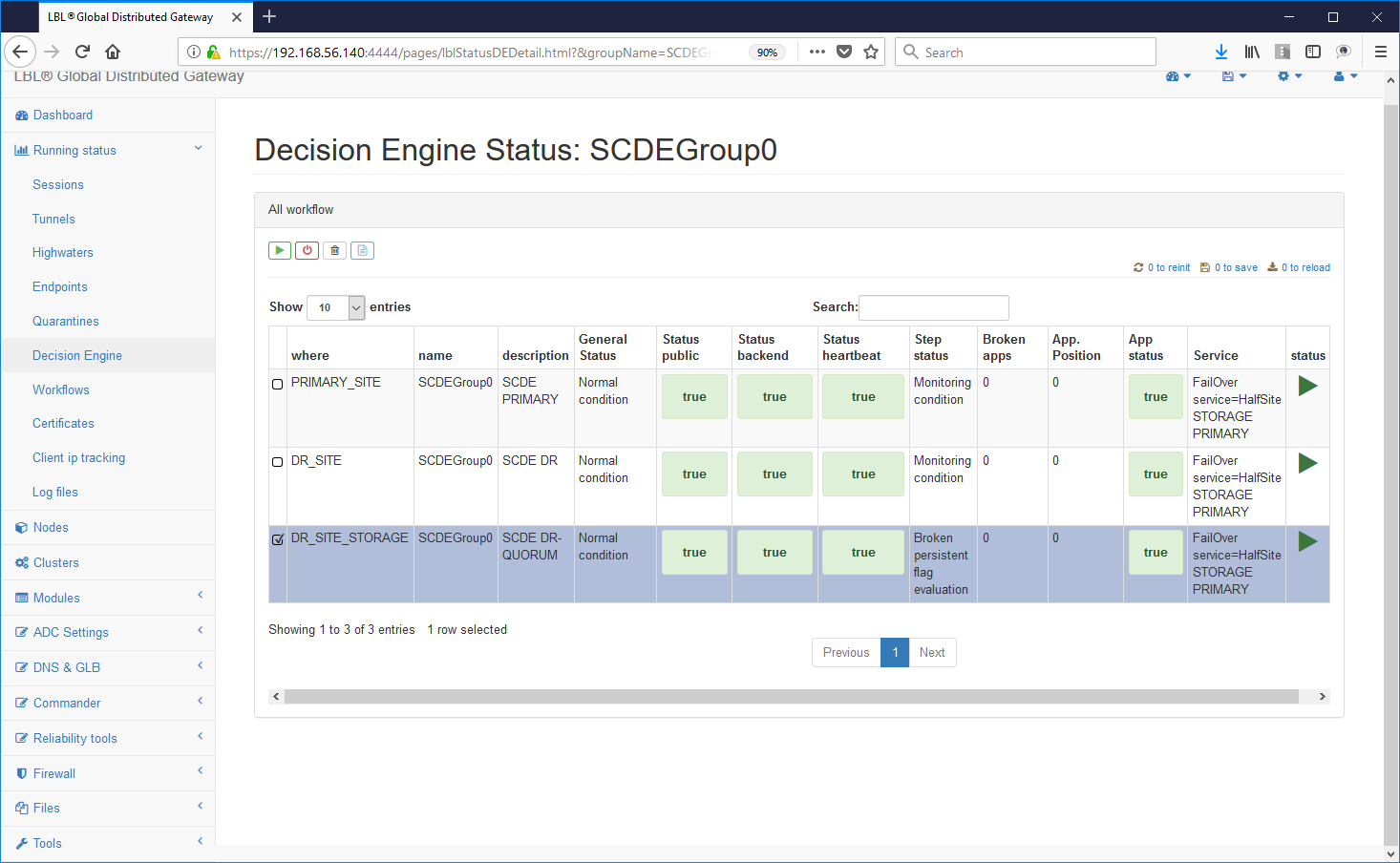
To check if the settings made are correct it is enough follow the HiperLinks as in this case: groupName-> SCDEGroup
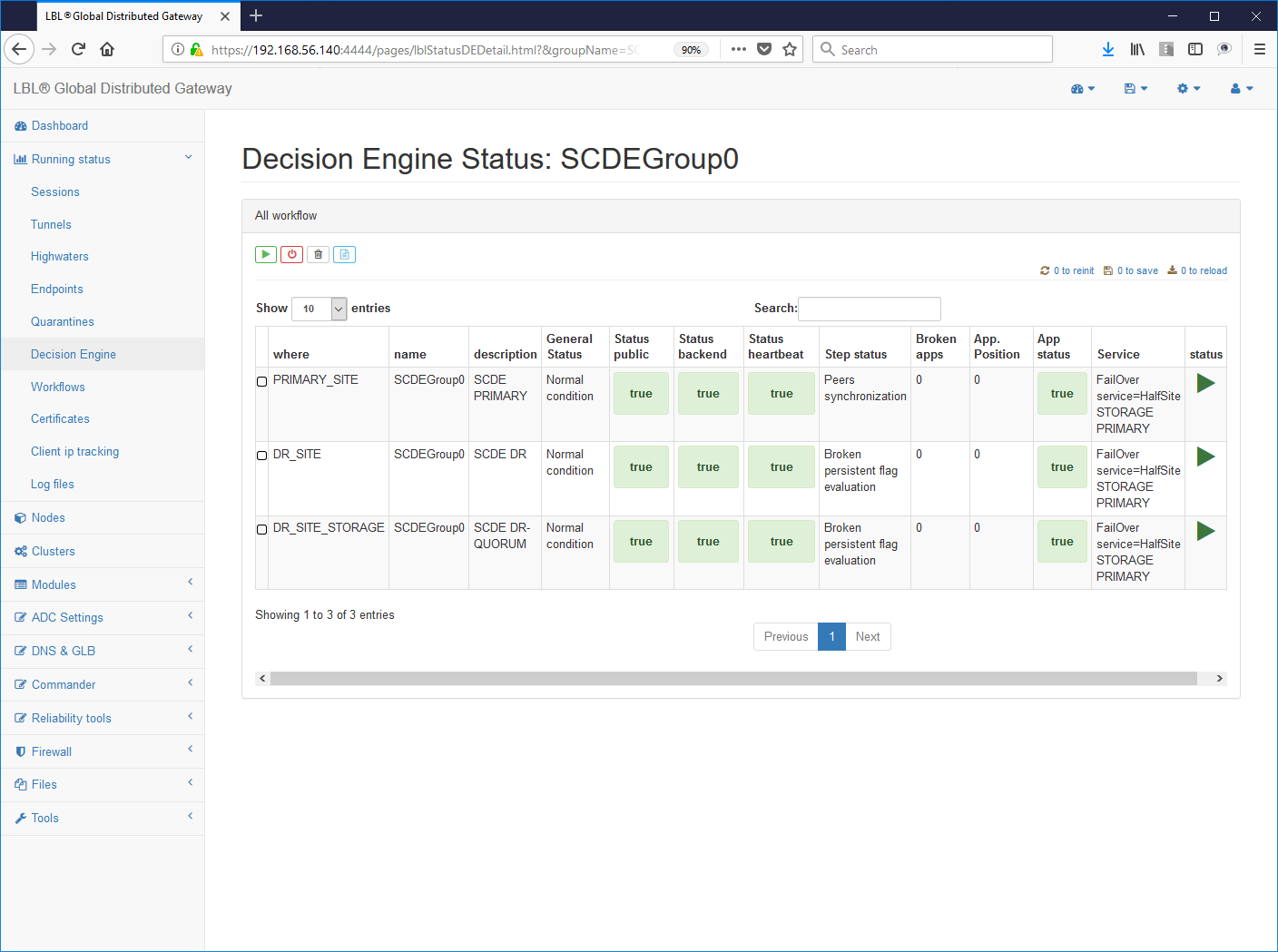
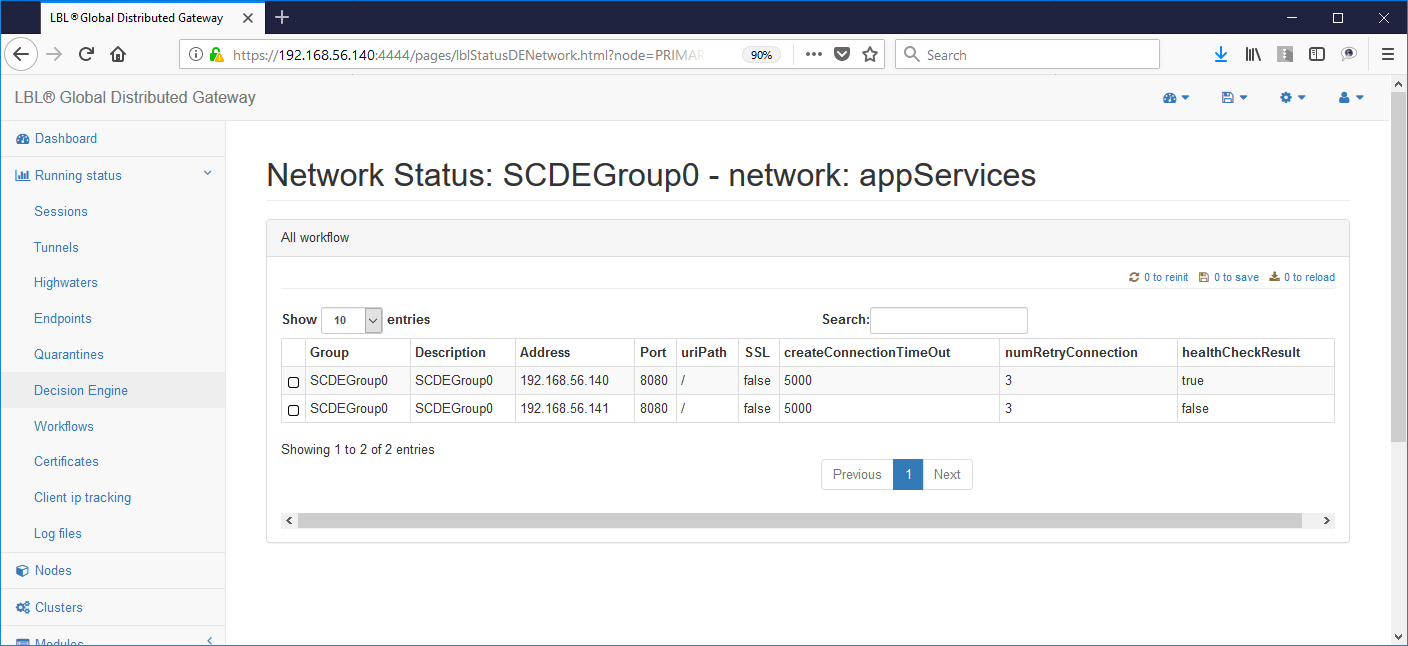
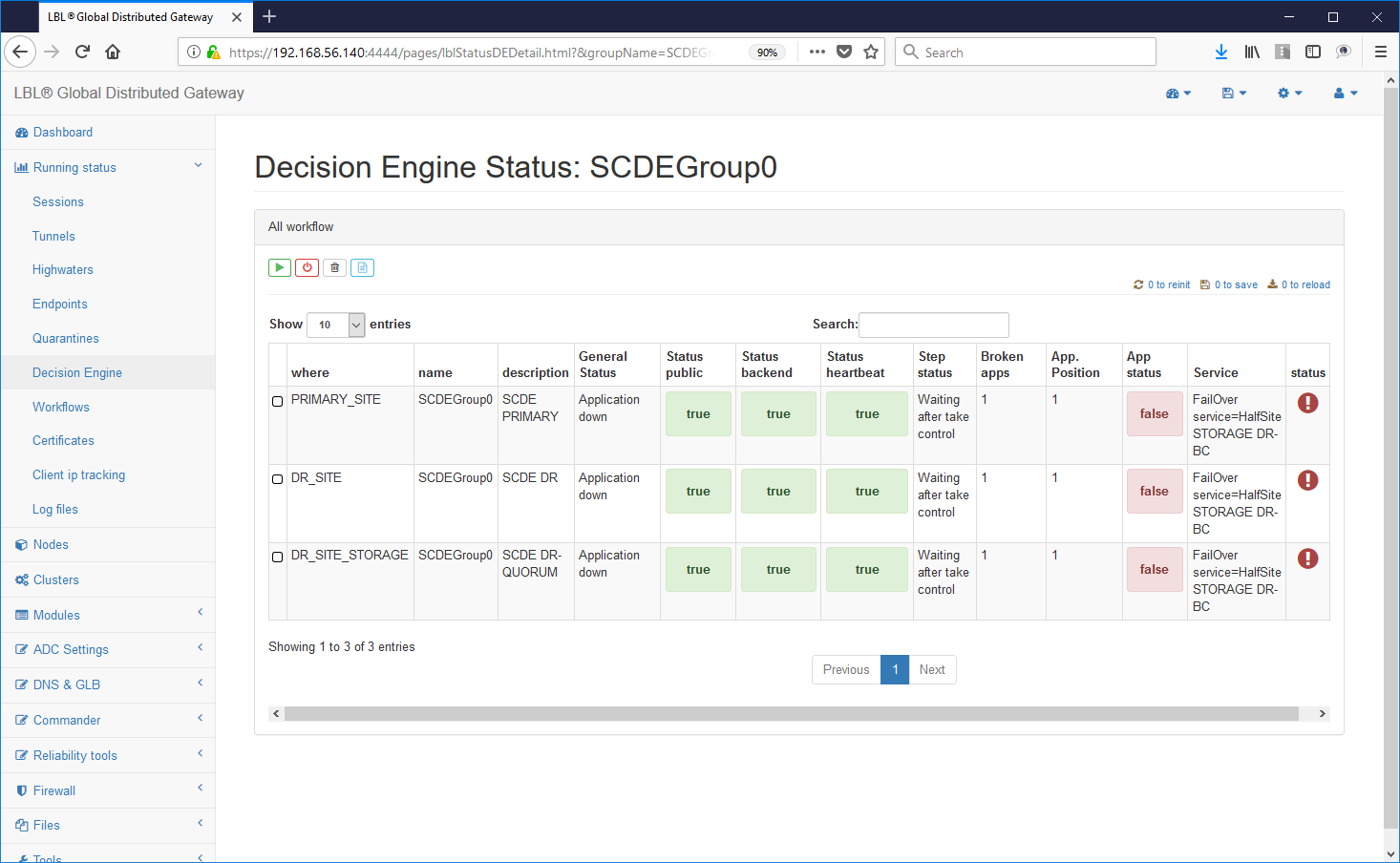
This view shows us on which node it is active the application. In this case the primary application site (A.A) is up and running while the secondary site does not correctly the active application. This of course is the normal condition if the application on the secondary site (B.B) was also active we would be in an application Split Brain situation. Wanting to simulate this condition now let's try to start the Apache Tomcat instance also on the secondary site ...
On Oplon Commander Work Flow of the secondary site we execute the start Apache Tomcat manual ...
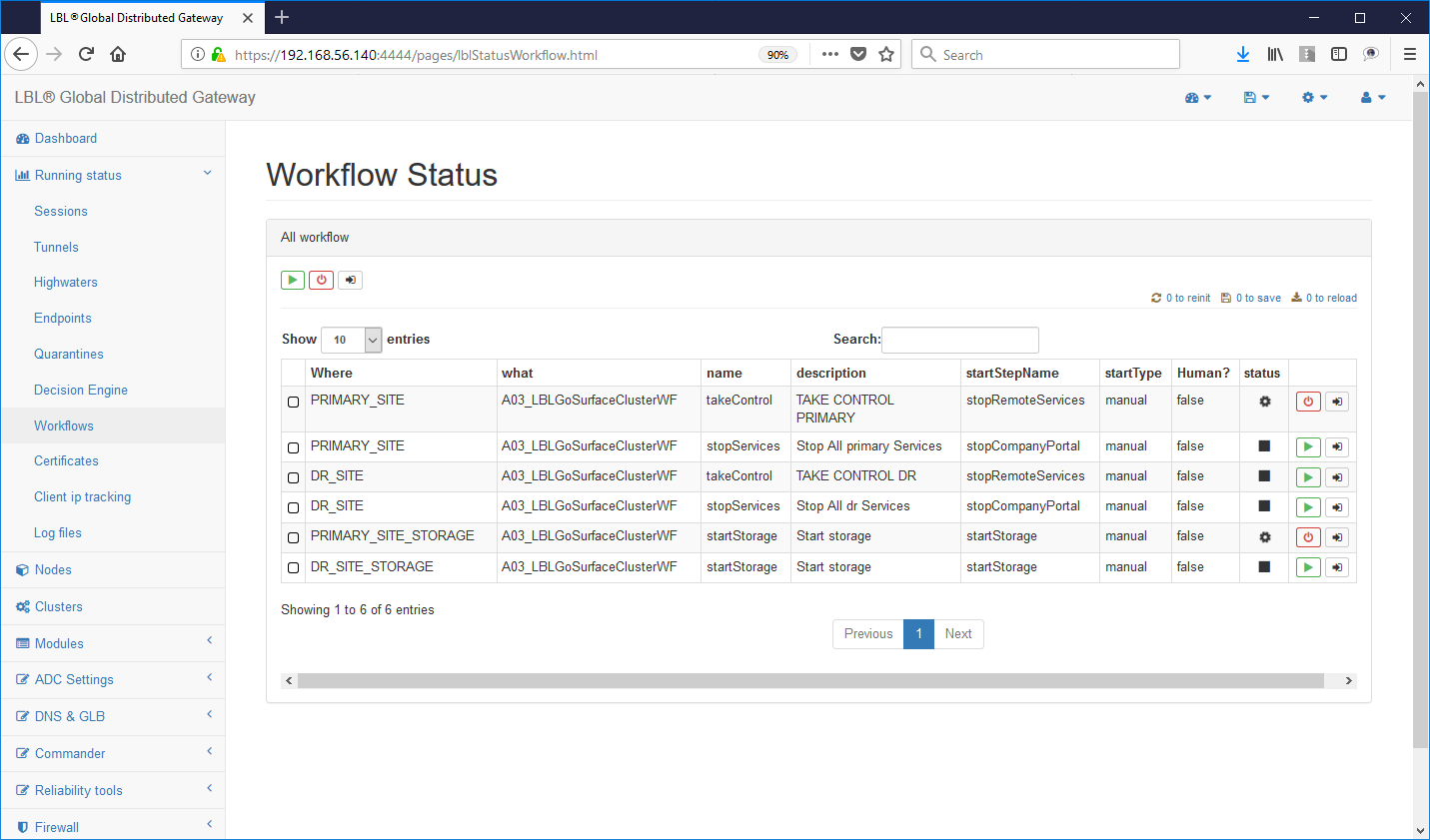
Immediately all instances Oplon Commander Decision Engine detect the anomaly by reporting it on the logs via e-mail and HTTP post. Also in this situation Oplon Commander Decision Engine arises in a state of inconsistency and therefore unable to take one decision.
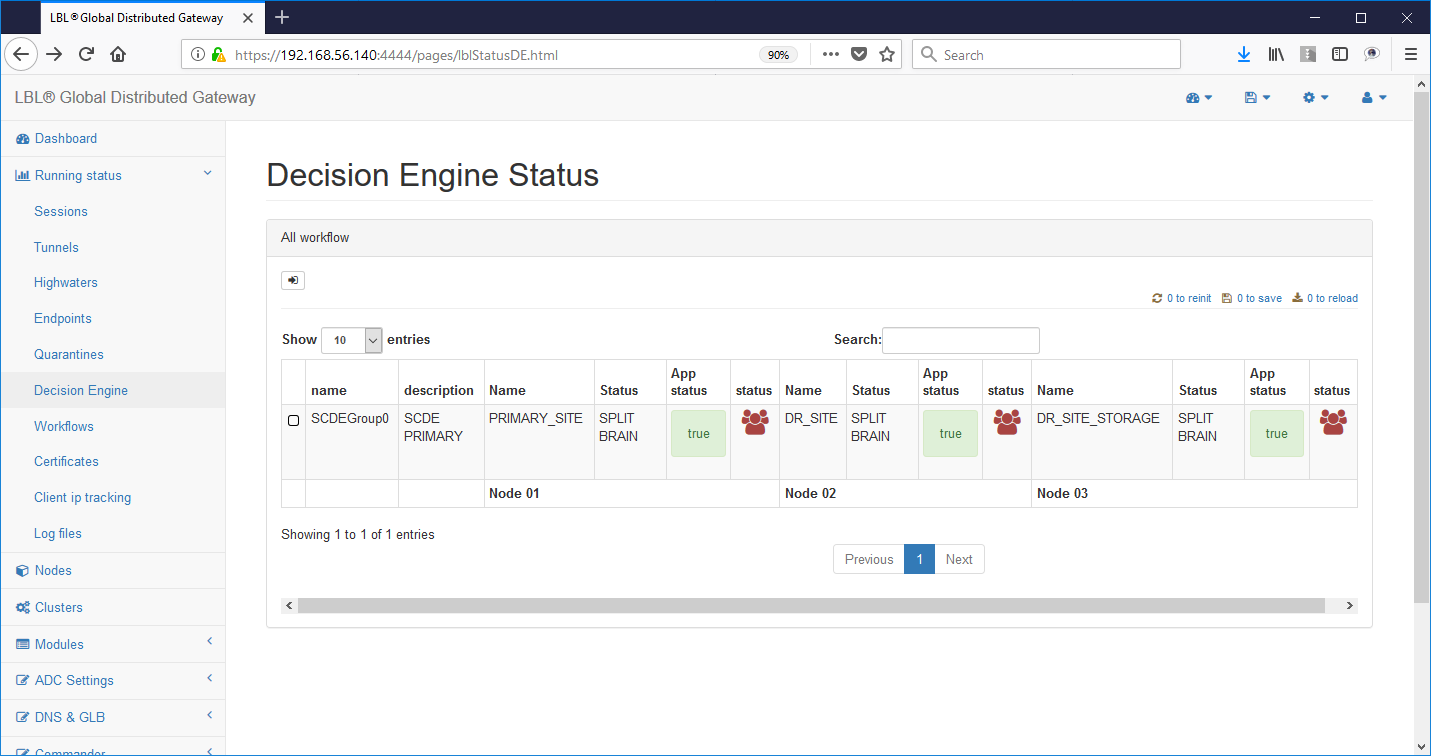
Oplon Commander Decision Engine was designed to work in geographical contexts and maintains a conservative decision-making behavior identifying situations in which it is not possible to take autonomous decisions for insufficient information or identifying situations of inconsistency.
Also through the Web interface we operate on Oplon Commander Work Flow to restore the situation and delete the report SPLIT BRAIN status:
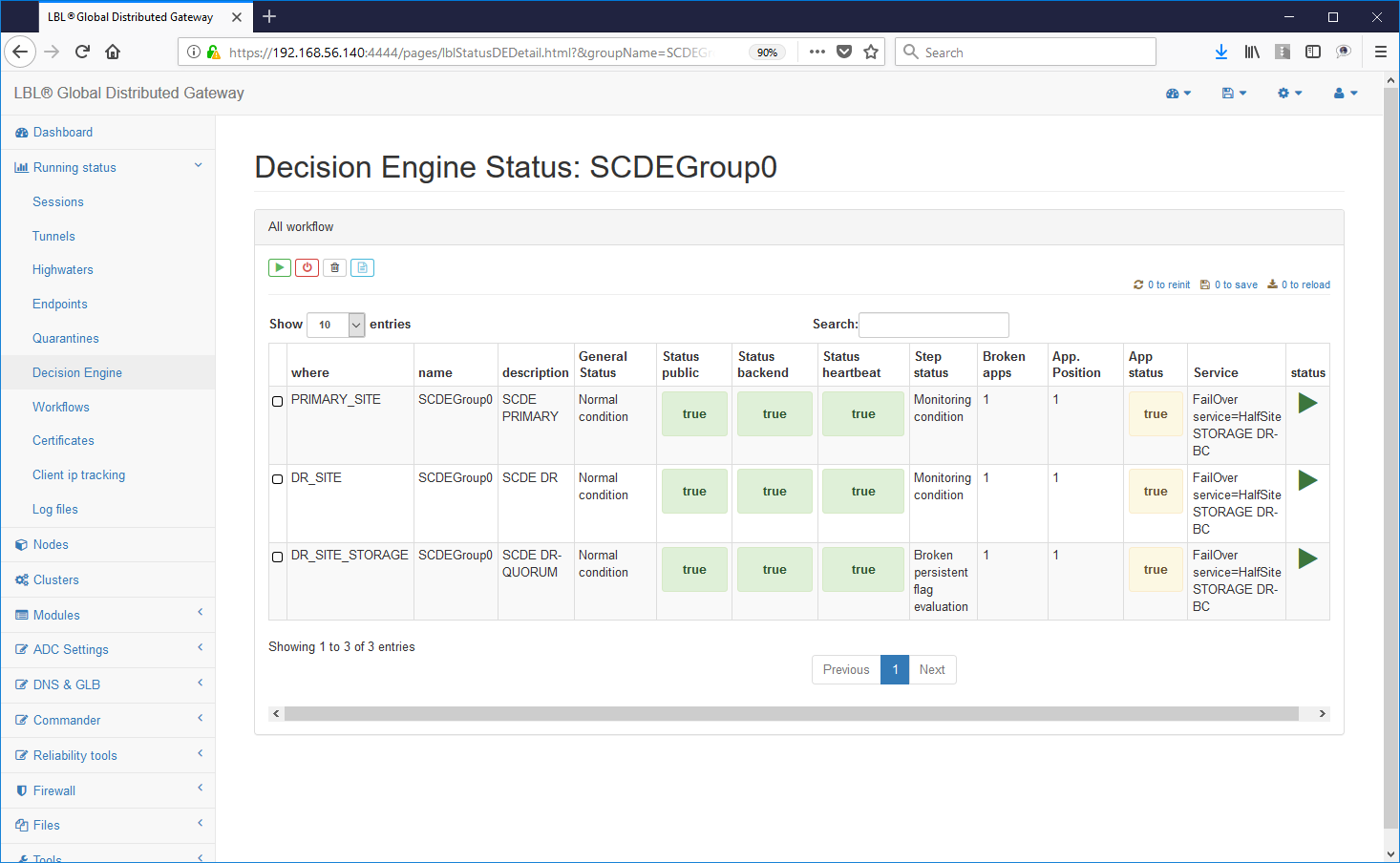
We perform the "gracefulShutdown" Work Flow in the secondary site ...
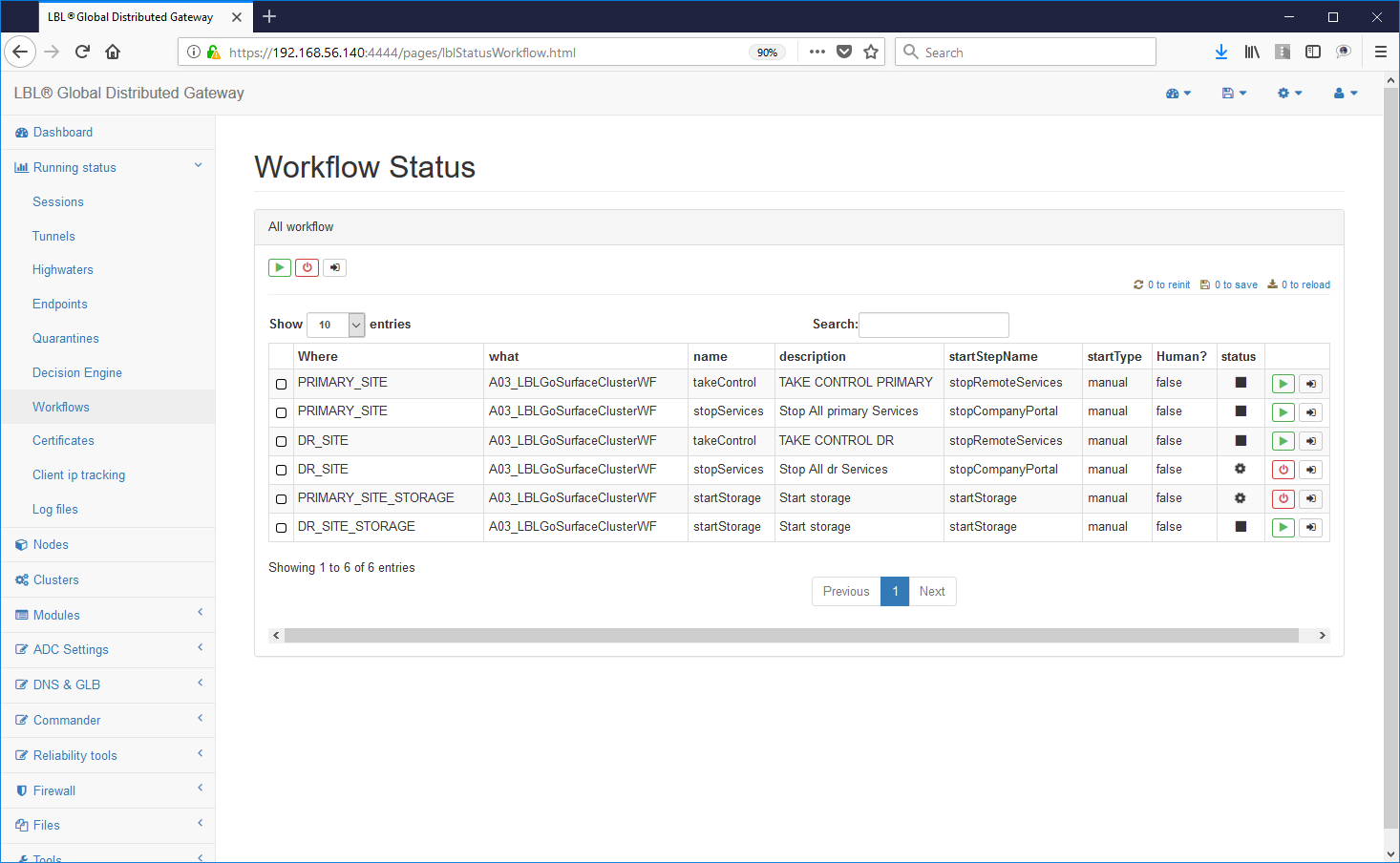
... Oplon Commander Decision Engine instances detect what happened restoration of a coherent situation ...
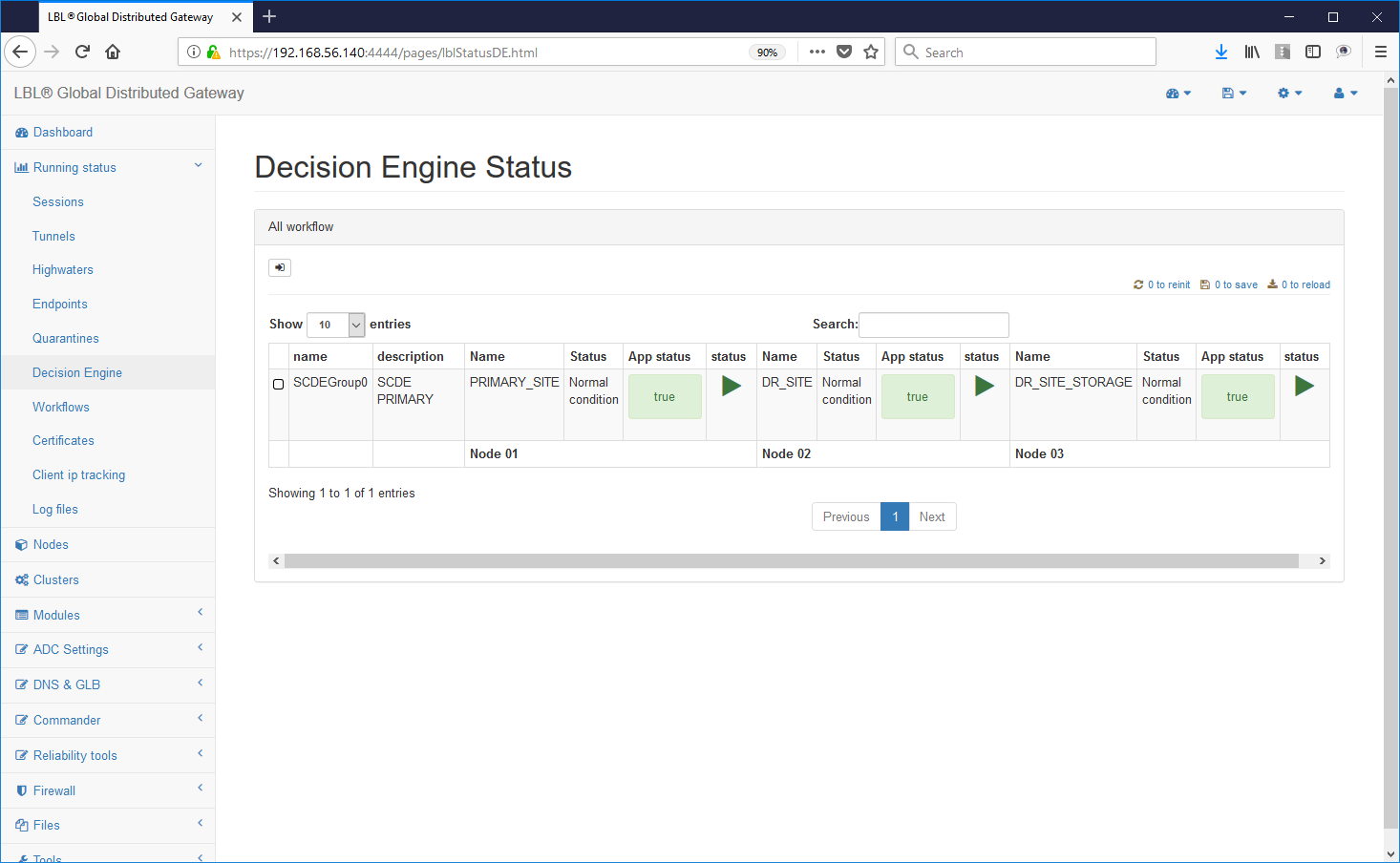
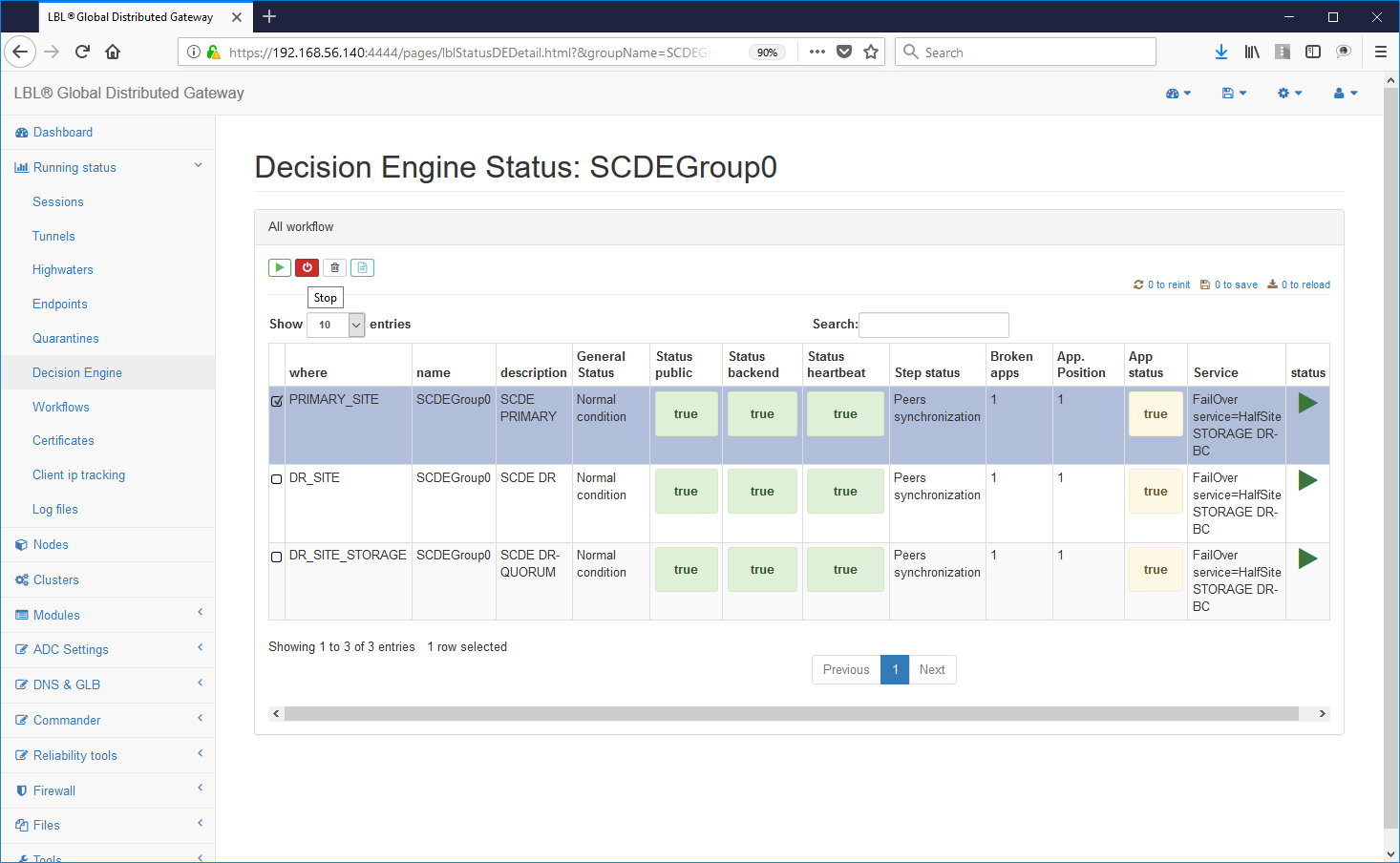
Now let's try to generate a problem by performing a forced stop of the Apache Tomcat instance on the primary site ....
Instantly Oplon Commander Decision Engine instances will detect the problem...
 set by lease-time completely
settable in relation to the application and the operating environment
Oplon Commander Decision Engine instances check if the condition
abnormal is a condition of actual error event or has been
caused by a sporadic event and once persistence has been verified
of the error event and verified the condition to be able to take
Oplon Commander Decision Engine instances of "autonomous" decisions
definitively place the node/site source of the
problem...
set by lease-time completely
settable in relation to the application and the operating environment
Oplon Commander Decision Engine instances check if the condition
abnormal is a condition of actual error event or has been
caused by a sporadic event and once persistence has been verified
of the error event and verified the condition to be able to take
Oplon Commander Decision Engine instances of "autonomous" decisions
definitively place the node/site source of the
problem...
all decisions made by Oplon Commander Decision Engine instances they are part of a sophisticated decision engine with detection parallel of the events coming from the surrounding environment and in each moment the actions will follow each other independently but coherently in all decision nodes ...
... once the surviving decision nodes achieve consistency of information relating to the explicit declaration of "down" of the application independently and in competition try to restore an application situation of operation ...
... the operations that follow the "down" declaration of the site primary are a last-ditch attempt on the primary site anyway a controlled shutdown to try if possible to minimize the problems due to a forced take-over.
... after performing controlled shutdown of applications in the primary site Oplon Commander Decision Engine waits for a while reasonable that the primary node/site could have done theirs controlled shutdown operations ...
.... and in any case when the time limit is exceeded, the take-over is forced services on the node/secondary site ... waiting for the startup application on the secondary site.
return to operational normality and obviously reporting the status of secondary site error ...
Oplon Commander Decision Engine Application Recovery Wizard
Oplon Commander Decision Engine is a decision engine designed for have very little maintenance and above all a very low impact operating. The management of the operations is completely entrusted to Web interfaces usable through any instance Oplon Monitor properly trained. At a failure event application Oplon Commander Decision Engine uses indicators persistent and distributed on the different nodes as a trace of the event.
To restore the situation to normal operating with the site active main and secondary site in replication is sufficient to operate through the Oplon Commander Decision Engine web interfaces e Oplon Commander Work Flow.
For example, if you want to restore operations on the main site of the Apache Tomcat instance it is sufficient to logically stop the decision engines for that group of applications ...
Stopping the decision engines does not affect the instances in the least Oplon Commander Work Flow and is therefore possible at any time stop the decision engines.
By stopping the decision-making engines it is possible to manage in a guided way through the instances Oplon Commander Work Flow the activities of restore without having to intervene directly on the nodes but by activating the procedures (Work Flow) provided for the restoration.
Having to manually restore the initial situation with Apache Tomcat running on the main node/site once stopped logically the decision engines just go to the site and carry out the operations in the opposite direction: gracefulShutdown of the application on the secondary site and then takeControl on the main site.
Before carrying out operations on the nodes/application sites make sure that all Oplon Commander Decision Engine instances related to the application group, SCDEGroup in this case, are in the state of STOPPED:
At this point, once it is established that the decision-making engines for the group application have been placed in STOPPED status, you can proceed with the restoration of the initial condition.
From this moment on, the operation was restored from one point operational view.
We just have to bring the decision-making engines back to a useful state next failure event ... Returning to Oplon instances Commander Decision Engine stops at the beginning of the process restore you will notice that an X has been made available on the right. This button is used to clear all persistent flags of indication of failure on nodes/locations. Clean up the persistence on all nodes Oplon Commander Decision Engine.
The situation should appear in all nodes in the following situation: 0 BrokenApps and the X button no longer enabled. ATTENTION: Make sure that all decision engines have been cleared of persistence flags. The persistence flags come automatically propagated on all nodes and therefore in case it remains also I am one in the three nodes Oplon Commander Decision Engine also all other nodes at startup would inherit it causing a new one "takeControl" of the secondary site.
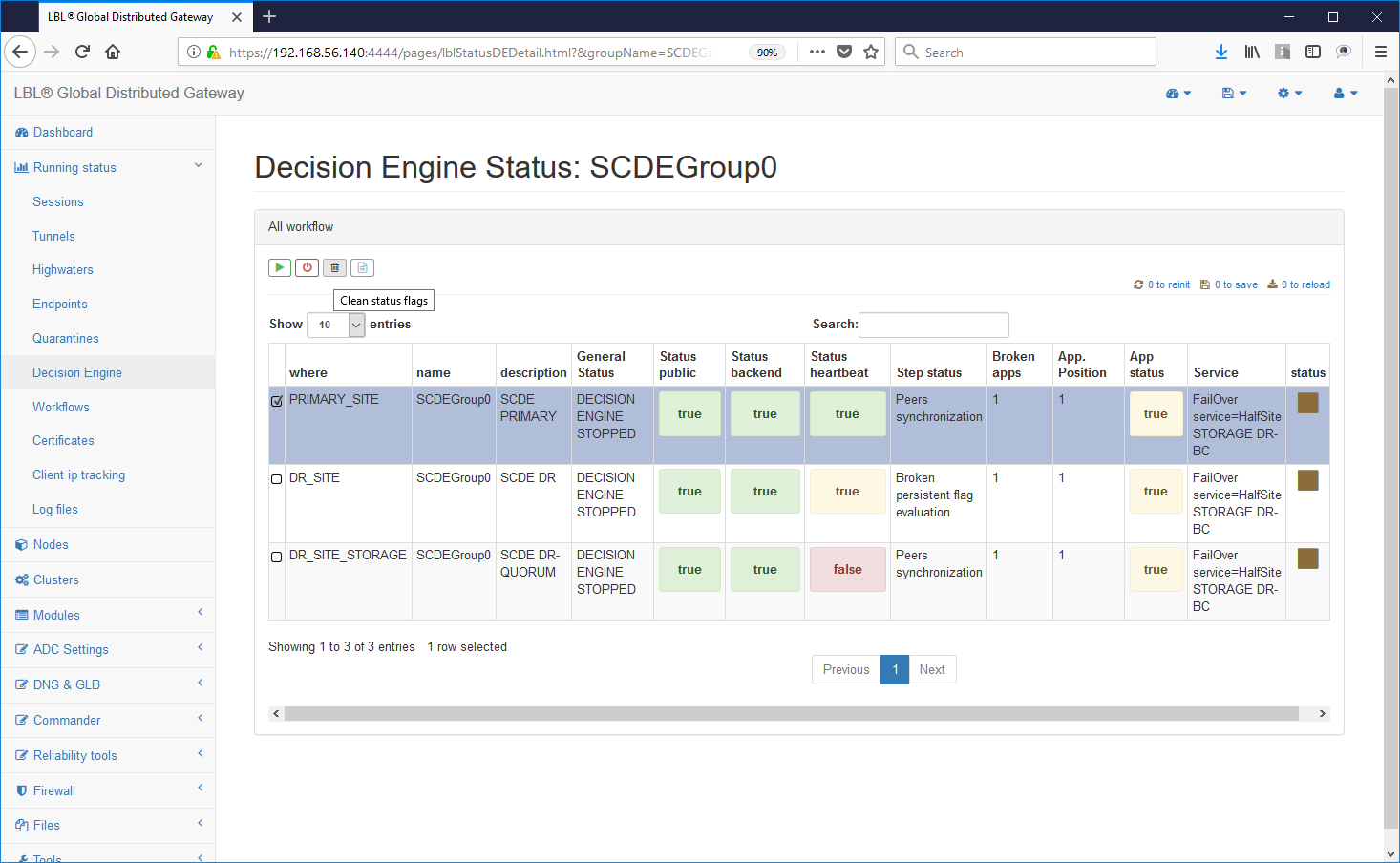
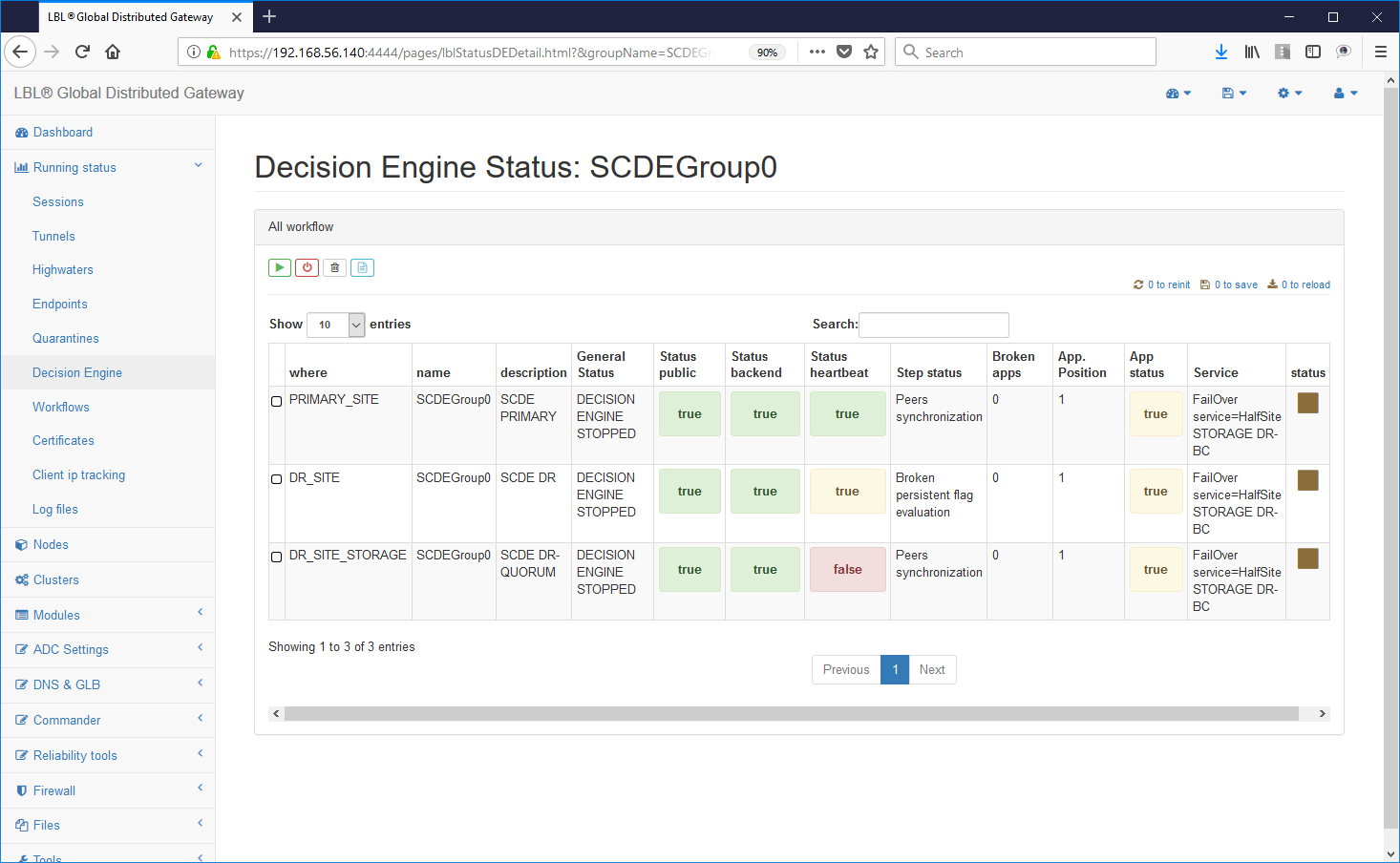
Once it is established that all the Oplon Commander Decision Engine are aligned from the perspective of persistence flags (zero) is just restart them without any particular boot order ...
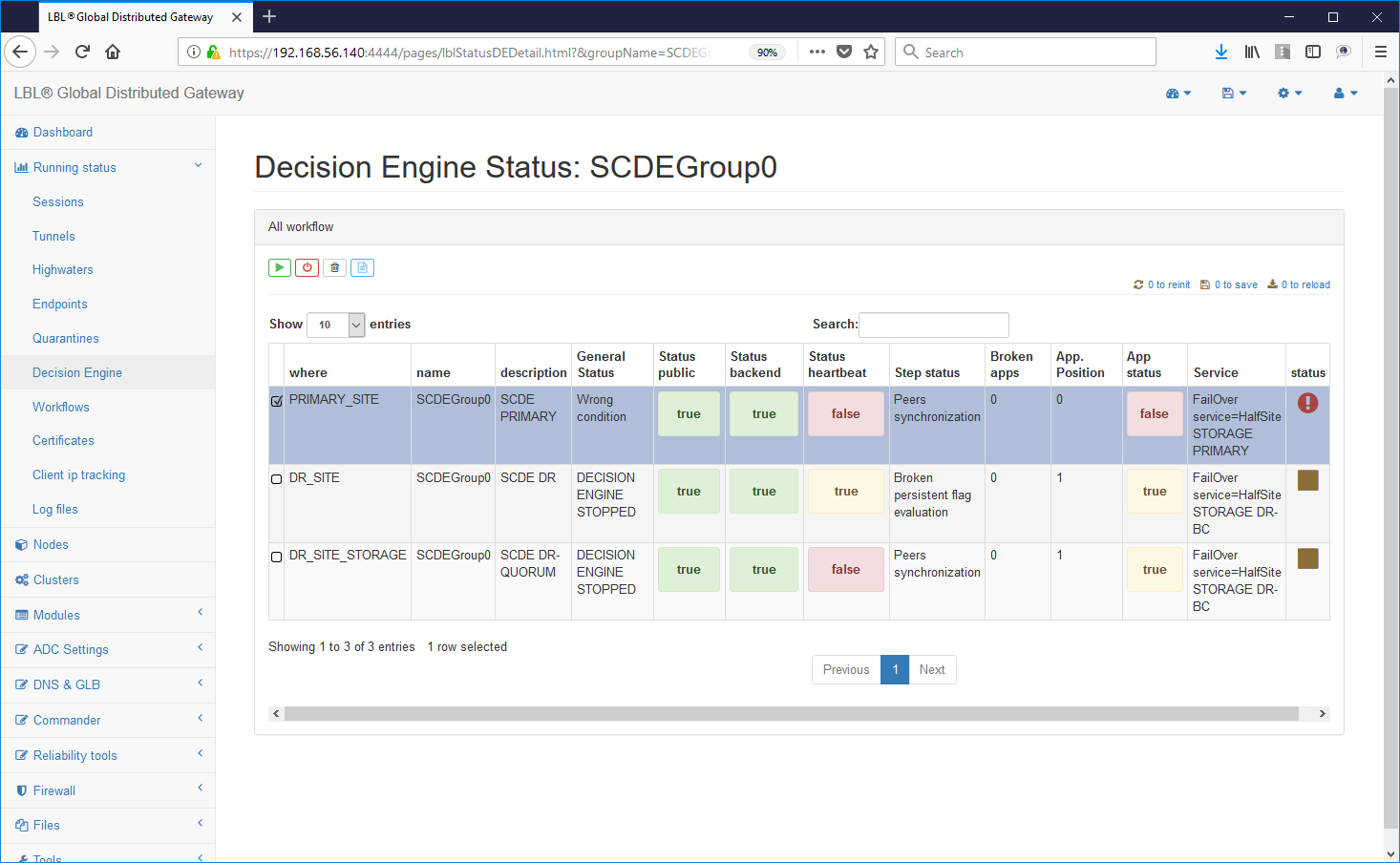 After the start of the first decision engine
you will have a Wrong Condition determined by the fact that it is the only one
operational decision engine ...
After the start of the first decision engine
you will have a Wrong Condition determined by the fact that it is the only one
operational decision engine ...
Already from this start, however, the operation of the applications on the main site ...
Then starting the second decision engine will reset the situation in which the engines are able to make decisions autonomous ...
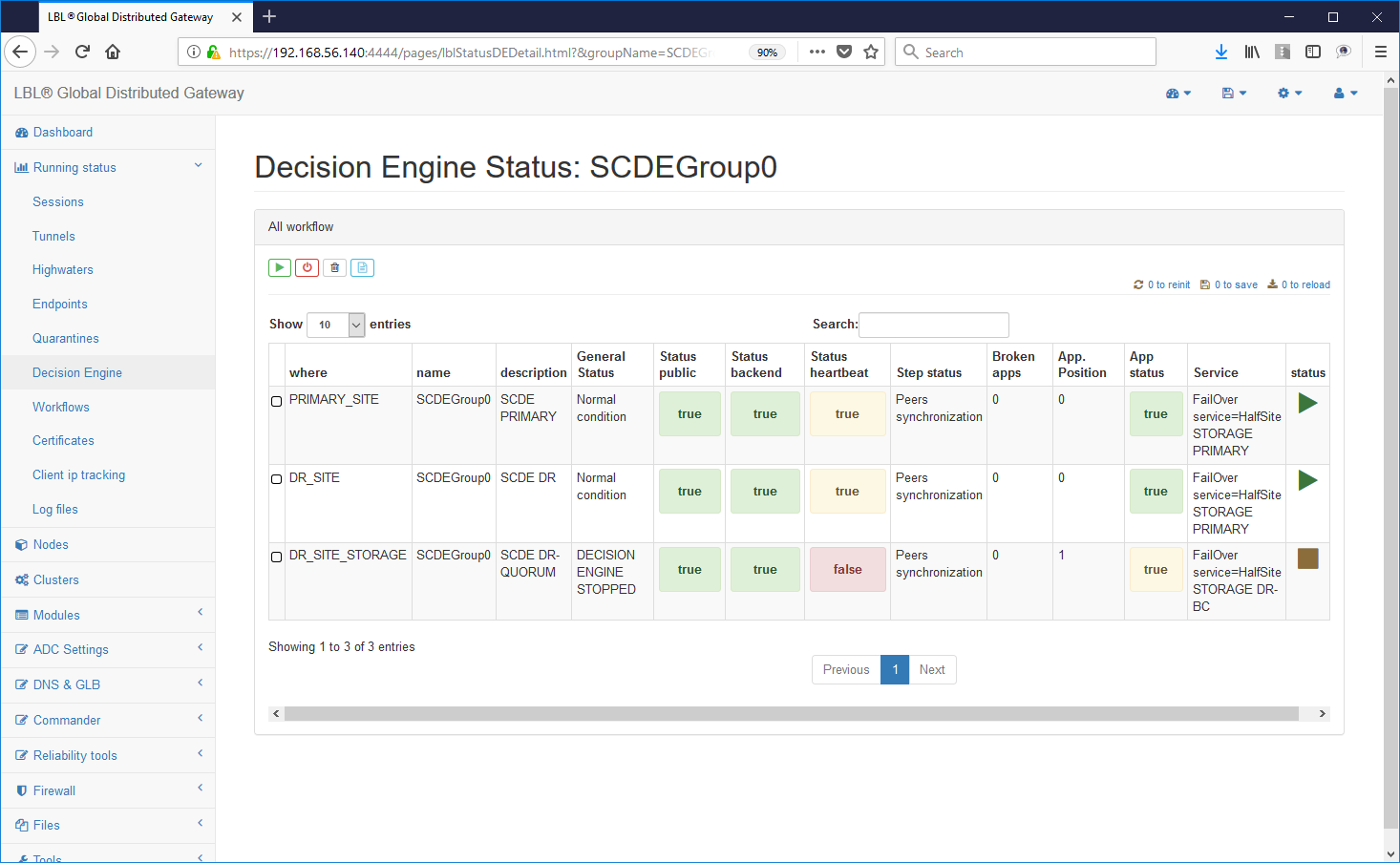
The status of the HeartBeat in yellow indicates that not all engines decision-makers are operational but that already from this moment the two instances they can make their own decisions ...
The start of the third decision engine also brings everything back to the state
initial...
Oplon Commander Restart phase
Since release 7.1 Oplon Commander Decision Engine manages a phase intermediate between the failure detection and the switch in another node/site of operation. This optional intermediate stage commands a Restart to verify if with a less invasive intervention than the switch over, the original operation can be restored.
This phase was introduced by verifying in the field that very often it is a restart of the application servers or the database, or both, to solve the problems that had arisen.
The implementation of this phase involves development first of the restart workflows and therefore their setting on the motors decision-making.
- Restart Workflow Development
The development of the Restart Workflow plans to perform a stop "graceful" of the operating environment with subsequent start at the end of which the overall application operation will occur again. This phase is characterized by two important considerations, the first it is certain that the restart has not already been performed in a moment relatively close so as not to trigger chain restarts, the other consideration is to still perform a fail-over if all restart procedures were not successful.
The solution to not trigger chain restarts is very simple from implement as in one Step of Oplon Commander Work Flow is You can set a wait before executing the Step. With this parameter it is sufficient to insert a wait in the last Step of the Restart workflow to avoid multiple restarts. The calculation the waiting time before making the Workflow available again to another possible Restart command must be carried out as of following:
The formula is obviously indicative and tends to highlight that the total waiting time in the last Step of a Restart Workflow must be greater than the waiting time of the promotion of fail-over to another node/site. Using this simple trick you are sure not to run into Split Brain caused by the simultaneous start of the applications on the two sites and you are also safe not to run into multiple chain restarts of an application by now compromised.
You can extend the total waiting time in the last step as desired. For example, if the application you want to test requires normally a restart every two days, it can be deduced that it will cause a further Restart due to detection of malfunctions in the arc of the 6 hours following the previous Restart can be considered as a problem with the "system" and not with the application.
Upon detection of a further failure event and consequent command of Restart, by the Server Oplon Commander Decision Engine, in the time window of 6 hours from the previous Restart, being the Workflow still pending in the last Step will not come further performed. After the lease time, set in Oplon Commander Decision Engine, the application failure declaration will come promoted the fail over on another node/site.
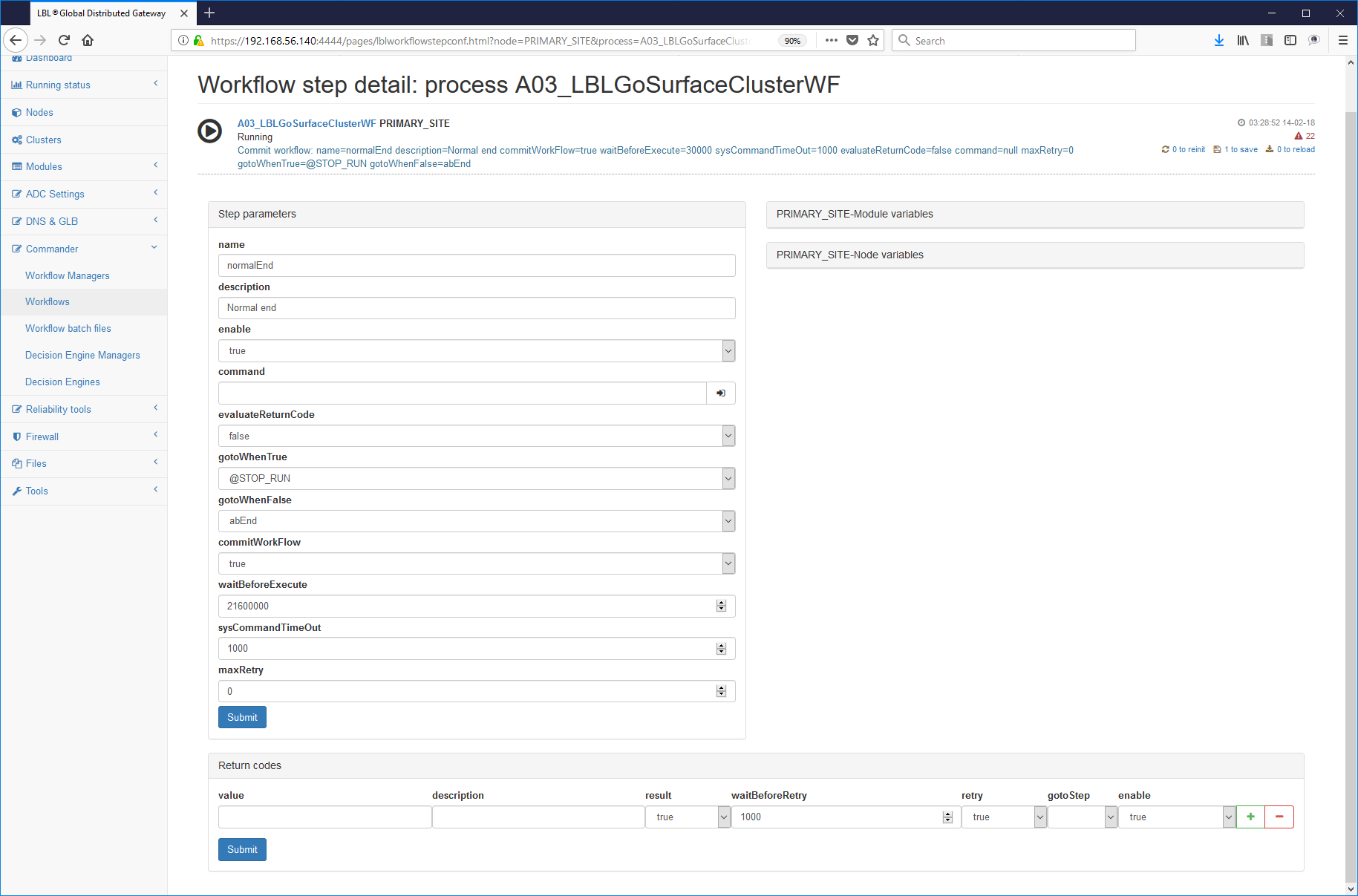
To develop the Restart Workflow it is probably sufficient use part of the ** gracefulShutdown ** Workflow Steps and part of the Steps of the Workflow ** normalPrimer ** highlighting more the reusability of previously created script modules.
In the last steps, normally normalEnd or abEnd will suffice insert the waitBeforeExecute parameter = "21600000"
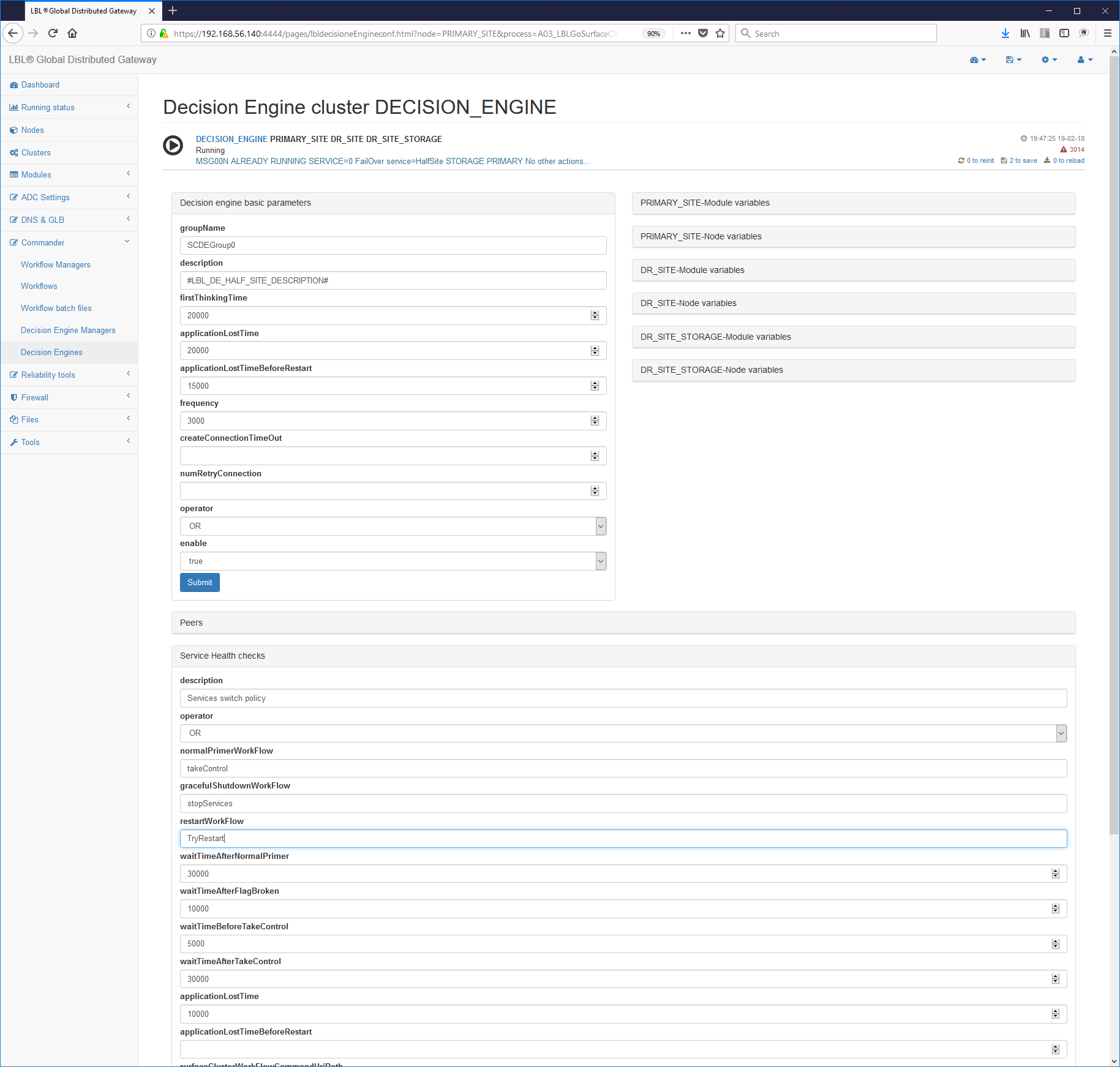
- Setting the Restart in Oplon Commander Decision Engine
The setting of the Restart phase in the motor parameters decision making is very simple because it just adds the new parameters applicationLostTimeBeforeRestart and restartWorkFlow respectively the lease time between the detection of the failure and the time of the Retsart and the name of the Restart Workflow to be called. Below is a fragment of the surfaceclusterde.xml parameters file (for more details see the Reference Guide document):
Oplon Commander Decision Engine Split Brain Assassin
This service manages, in distributed and peer cluster environments (stretch cluster), any possibility of Split Brain.
Oplon SCDE Split Brain Assassin has very few parameters and is therefore usable with great simplicity. Simplicity needed in these cases.
Normally Oplon SCDE Split Brain Assassin will be configured in the nodes that have Oplon ADC instances. This is because the main purpose of Oplon SCDE Split Brain Assassin is to notify the ADC layer to exclude access to some services up to the exclusion of the whole traffic eliminating any possible interaction with the backend.
The Oplon SCDE Split Brain Assassin service will be activated last, after installing and configuring the Oplon balance layer Commander Decision Engine, Oplon Commander Work Flow and tried it all the whole. Only then will the possibility of Split Brain be evaluated geographic, see Oplon White Paper for a full explanation, and yes will proceed with the installation and start of Oplon SCDE Split Brain Assassin.
The steps required for configuring Oplon SCDE Split Brain Assassin are summarized as follows:
1 - Check that the Oplon Commander license has been set Decision Engine
(LBL_HOME) /lib/confSurfaceClusterDE/license.xml
2 - Setting the service configuration file
(LBL_HOME) /lib/confSurfaceClusterDE/splitbrainassassin.xml
There are two main paragraphs, the first is, as a rule, the
paragraph <params>. This paragraph defines the behaviors
generic such as HealthCheck frequency and some default parameters.
First you need to identify the targets for health check. These targets are easily identified in the two Oplon SCDE nodes, the joint venture and the Quorum. Oplon SCDE Split Brain Assassin only in lack of both targets (or all targets if more than two) will notify Oplon ADC by setting files notification.
Oplon SCDE Split Brain Assassin can be set to notify Oplon ADC a complete disconnection of all services, through the elimination of virtual addresses, or to exclude only part of the services interested in the event.
Configuration file example: splitbrainassassin.xml
<splitbrainassassin>
<params
frequency="10000"
createConnectionTimeOut="4000"
numRetryConnection="3">
</params>
<decisionEnginesPeers>
<peer enable="true"
description="Sys 001"
URL="<https://peerOne:54445/>" # Modificare
healthCheckUriPath="/HealthCheck?decisionEngine=SCDEGroup"/>
<peer enable="true"
description="Sys 002"
URL="<https://peerTwo:54445/>" # Modificare
healthCheckUriPath="/HealthCheck?decisionEngine=SCDEGroup"/>
<notification
fileName="lib/notificationDir/outOfOrder.systemsMonitorGroup"
description="All vips"/>
<notification fileName="lib/notificationDir/outOfOrder.gr1"
enable="false"/>
<notification fileName="lib/notificationDir/outOfOrder.gr2"/>
<notification fileName="lib/notificationDir/outOfOrder.gr3"/>
<notification fileName="lib/notificationDir/outOfOrder.gr4"/>
</decisionEnginesPeers>
<sysobserver>
<service name="syslog" id="syslogsplitbrainassassin"/>
</sysobserver>
</splitbrainassassin>
</serviceconf>3 - Start the process and check the logs:
3 - Setting the automatic start of the service
(LBL_HOME)/lib/confMonitor/A03_LBLGoSurfaceClusterWFRemoteBatch.xml
<A03_LBLGoSurfaceClusterDESplitBrainAssassin>
<process enable="true"
description="LBL(r)Commander Split Brain Assassin"
start="automatic" -----> Modificare da "manual" ad "automatic"
numberTryStartOnFailure="-1"
waitBeforeKill="60000"
waitBeforeKillOnFailure="10000">
<start osName="Windows">
<env>CLASSPATH=.;lib;libLBLADC.jar</env>4 - Perform the same operation in the other nodes of balancing...
NOTE:
To have a more reliable test it is possible to add HealthCheck on other services. We do this in the example below a HelthCheck service offered was also checked by Oplon Commander Work Flow Remote Batch.
<peer enable="true"
description="Sys 002"
URL="<https://peerTwo:54445/>"
healthCheckUriPath="/HealthCheck?decisionEngine=SCDEGroup"/>
<peer enable="true"
description="Sys 002"
URL="[https://peerTwo:5994/](https://peerTwo:54445/)" <--- Modificare
healthCheckUriPath="/RemoteBatch/startBartch.xml"/> <--- modificare