Einführung in Business Continuity und Disaster Recovery
Das Thema der kontinuierlichen Bereitstellung von IT-Diensten wird in der Regel mit zwei Begriffen umschrieben: Business Coninuity (BC) und Disaster Recovery (DR). In einigen Fällen wird der Begriff Business Continuity auch durch den Begriff Operational Continuity ersetzt, der für Dienstleistungen steht, die im öffentlichen Interesse liegen und daher nicht mit dem Geschäft zusammenhängen.
Business Continuity und Disaster Recovery, was sind die Unterschiede?
Im Laufe der Zeit wurden diese beiden Arten der Kontinuität der Leistungserbringung auf unterschiedlichste und phantasievolle Weise beschrieben. In Wirklichkeit ist der Unterschied zwischen diesen beiden Begriffen funktioneller Natur.
Die erste Frage, die wir uns stellen müssen, wenn wir uns für eine der beiden Alternativen oder für beide entscheiden, ist die folgende:
Endet das System der Dienstleistungen des Unternehmens/der Einrichtung, die wir absichern wollen, mit der Beendigung des Standorts, von dem aus die Dienstleistungen erbracht werden??
Wenn die Antwort ja lautet, ist die Art der Geschäftskontinuität Business Continuity, wenn die Antwort nein lautet, muss die Geschäftskontinuität an einem Standort gewährleistet werden, der geografisch vom Hauptrechenzentrum entfernt ist, um die Erbringung des Dienstes sicherzustellen. Im letzteren Fall wird dies als Disaster Recovery bezeichnet.
Business Continuity
Die Business-Continuity-Lösung muss als Hauptmerkmal die Nähe zum Ort der Leistungserbringung aufweisen, um wirksam zu sein, und sie muss zwei getrennte, aber nahe gelegene Standorte vorsehen, z. B. dasselbe Gebäude (in geeigneter Weise durch Firewalls, doppelte Stromversorgung und Konnektivität getrennt) oder zwei getrennte Gebäude. Wichtig ist die Nähe des operativen Dienstes, denn selbst wenn keine externe Konnektivität von Telekommunikationsbetreibern (Konnektivitätsanbietern) vorhanden ist, muss mindestens eines der beiden Rechenzentren immer erreichbar sein.
Disaster Recovery
Für Tätigkeiten, die eine Kontinuität der Disaster-Recovery-Dienste erfordern, müssen die beiden Rechenzentren eine Mindestentfernung aufweisen, die gemeinhin auf etwa 70 km geschätzt wird. Dies ist die Entfernung, die es in den meisten Fällen ermöglicht, Infrastrukturen zu schützen, wie es leider bereits nach natürlichen oder vom Menschen verursachten Ereignissen (Erdbeben, das Kernkraftwerk Fukushima nach dem Tsunami von 2011, Tschernobyl 1986, dessen Sperrzone noch immer einen Radius von 40 km umfasst, usw.) erprobt wurde.
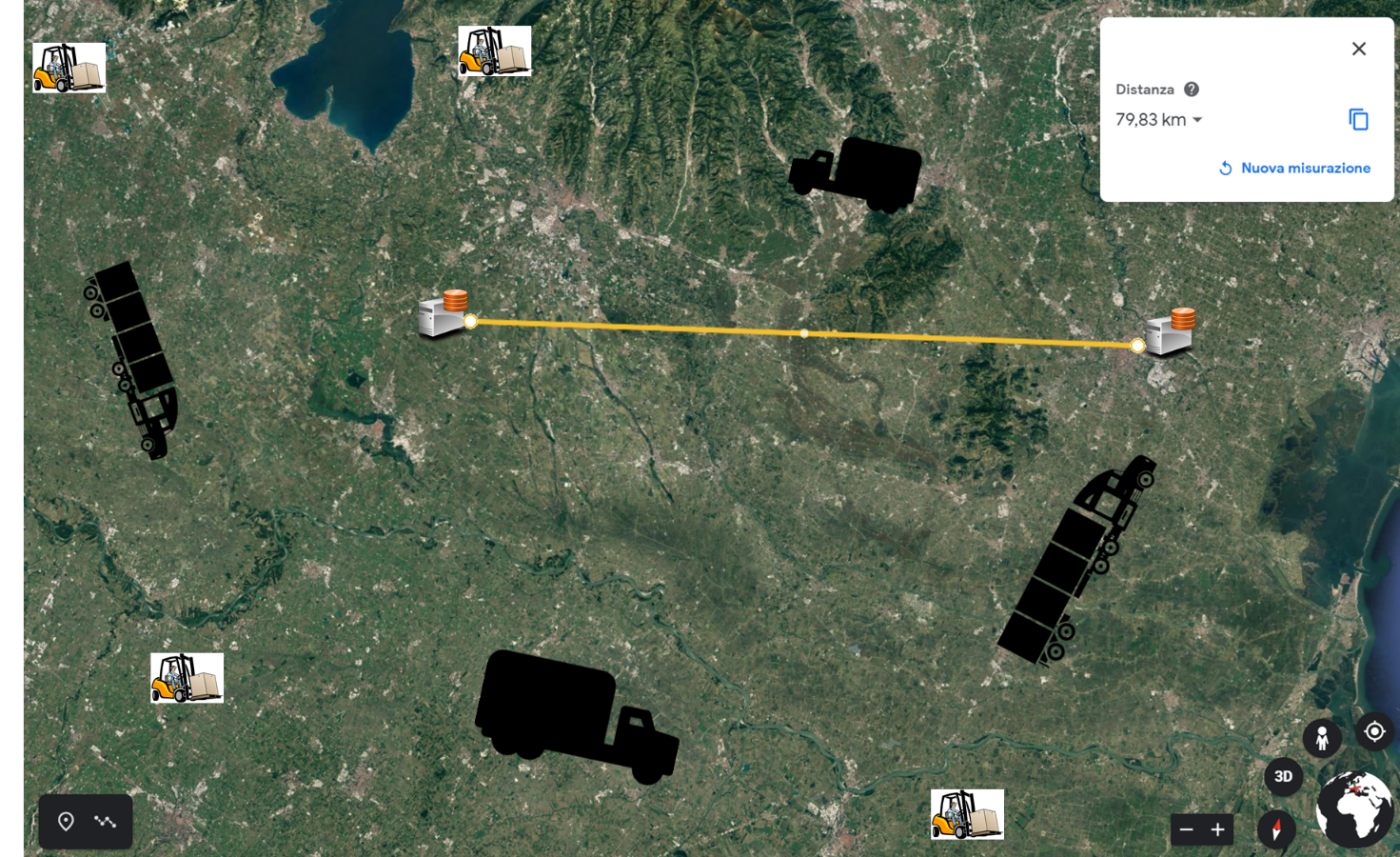
Beispiele für Business Continuity und Disaster Recovery: eine Krankenhaus-Notaufnahme und ein internationaler Kurierdienst
Als Beispiel können wir einen IKT-Dienst für eine Krankenhaus-Notaufnahme und einen IKT-Dienst für einen internationalen Kurierdienst annehmen.
Sollte ein Ereignis eintreten, das die Räumlichkeiten einer Krankenhaus-Notaufnahme völlig unbrauchbar macht, wie z. B. eine Überschwemmung, ein Erdbeben oder ein anderes Ereignis, so dass das medizinische Personal keinen Zugang zu der Einrichtung hat, wäre die Alternative für die Nutzer, eine andere Notaufnahme in der Nähe aufzusuchen.
In diesem Fall wäre es wenig sinnvoll, die IT-Dienste der Notaufnahme an einem Standort in einem anderen Gebiet zu reaktivieren, wohingegen eine gute lokale Belastbarkeit der IT-Dienste (Business Continuity) die Aufrechterhaltung des Geschäftsbetriebs auch bei fehlender externer Konnektivität ermöglichen würde, da die Notaufnahme das Ereignis überlebt hat.
Im zweiten Fall handelt es sich um ein internationales Unternehmen, bei dem im Falle eines Problems, bei dem der Hauptsitz nicht mehr betriebsbereit oder unerreichbar ist, keine Unterbrechung in dem Sinne eintreten darf, dass Filialen, Lager und Logistik im Allgemeinen betroffen sind, die unabhängig vom Hauptstandort unbedingt betriebsbereit bleiben müssen. In solchen Fällen ist der Disaster-Recovery-Standort in angemessener Entfernung, in der Regel 700 km und mehr, für die Kontinuität der Leistungserbringung absolut unerlässlich.
Erst nach der Beantwortung dieser Frage kann man nach dem Recovery Time Objective (das die Geschwindigkeit angibt, mit der Computersysteme wiederhergestellt werden können); dem Recovery Point Objective (das den zulässigen Datenverlust angibt); throughput (Reaktionszeit), Durchsatz (genutzte Übertragungskapazität) und was sonst noch notwendig ist, um die Geschäftskontinuität unter besonders kritischen Umständen zu realisieren, fragen.
Cloud & Datacenter für Geschäftskontinuität
Wenn wir von Rechenzentren sprechen, meinen wir sowohl eigene Rechenzentren als auch Einrichtungen, deren Platz speziell für die Gewährleistung von Geschäftskontinuität und Disaster Recovery gemietet wird. Dabei kann es sich um Markt-Clouds oder spezialisierte Rechenzentren handeln, die Dienste zur Gewährleistung der Geschäftskontinuität anbieten. Bei der Beurteilung, ob die eine oder die andere Lösung angemessen ist, spielen mehrere Faktoren eine Rolle, darunter die Kosten.
In beiden Fällen muss eine sorgfältige Verwaltung der Datensicherungen in Betracht gezogen werden.
Entwurf eines Plans für Business Continuity und Disaster Recovery
Bei der Durchführung eines Projekts zur Business Continuity oder zur Disaster Recovery ist eine Reihe von Überlegungen anzustellen. In diesem einführenden Dokument werden die Aspekte hervorgehoben, die in beiden Fällen zu berücksichtigen sind, und es wird eine Liste mit Prioritäten für die Vorbereitung des Projekts erstellt:
- Zählung der Diensteintrittsstellen
- Zählung der Anwendungsserver, die Dienste ermöglichen
- Zählung der strukturierten Datenbanken
- Zählung der unstrukturierten Datenbanken
Das folgende Bild fasst die Ebenen zusammen, die die durch die farbigen Bänder dargestellten Serviceanfragen durchlaufen müssen, um die Anforderungen eines typischen Rechenzentrums zu erfüllen.
Der Umzug von einem Rechenzentrum zu mehreren Rechenzentren mit Datenreplikation und der Möglichkeit, in kritischen Zeiten vom sekundären Rechenzentrum aus zu operieren, muss von Werkzeugen begleitet werden, die den Betrieb erleichtern und so weit wie möglich automatisieren.
Jede der genannten Schichten benötigt Verfahren und Werkzeuge, um die Migration von Diensten von einem Rechenzentrum in ein anderes entweder vollständig oder auch nur teilweise zu ermöglichen. Ein weiteres wichtiges Element ist auch der Test, der regelmäßig durchgeführt werden muss, um sicherzustellen, dass im kritischen Moment alle Verfahren aktualisiert wurden und einsatzfähig sind.
Alle Anbieter in den einzelnen Schichten, Hersteller von Web-/Applikationsservern, Datenbanken, Storage usw. bieten normalerweise ihre eigene Lösung zur Realisierung der einzelnen Funktionen an. Es werden dann Werkzeuge benötigt, um die Aktivitäten zu orchestrieren und die Dienste vorzubereiten, die an sekundären Standorten durchgeführt werden sollen.
Tools für die Einrichtung von Diensten in einem Rechenzentrum:
Eines der unverzichtbaren Werkzeuge, auf denen alle Business Continuity und Disaster Recovery Richtlinien basieren, ist der Oplon Application Delivery Controller (ADC). Dieses Element bündelt den Dienstleistungskatalog und ist somit der Einstiegspunkt für jede Anfrage an das Rechenzentrum. Im Falle von Disaster Recovery kommt auch der Oplon DNS Global Load Balancer ins Spiel, der es ermöglicht, die DNS-Antworten dynamisch je nach Standort des Dienstes zu ändern. Er ist daher in der Lage, Anfragen an den primären Standort oder an den sekundären Standort zu leiten, der auf eine andere IP-Adresse antwortet, weil er sich in einem anderen geografischen Gebiet befindet.
Schlußfolgerungen
Wir haben gerade eine lange Reise zu einer Politik der kontinuierlichen Dienstleistungserbringung begonnen.
Wir haben die anfängliche Diskussion bewusst auf die allgemeinen Aspekte ausgerichtet, die uns zu einer bewussten Auswahl der am besten geeigneten Instrumente führen sollen, basierend auf der Art der zu schützenden Dienstleistung.
Anschließend werden die einzelnen Punkte und die möglichen Architekturvarianten genauer analysiert.