Business Continuity (BC) und Disaster Recovery (DR): automatische Entscheidungen oder menschliche Entscheidungen??
Dieser zweite Artikel zum Thema **Business Continuity (BC) und Disaster Recovery (DR) befasst sich mit der Frage, welches Verfahren bei der Verlagerung von Diensten von einem Hauptstandort zu einem sekundären Standort anzuwenden ist, und insbesondere damit, ob die Entscheidung menschlich oder automatisch sein sollte.
Normalerweise ist man geneigt zu denken, dass eine Business-Continuity-Site durch automatische Entscheidungen gewährleistet werden muss, wohingegen bei der Disaster Recovery die Entscheidung einer menschlichen Entscheidung überlassen werden muss, die oft aus einem Katastrophenausschuss besteht, der entscheidet, was zu tun ist.
**In Wirklichkeit sind es nicht die BC- oder DR-Bedingungen, die eine automatische oder menschliche Entscheidung bestimmen, sondern die Art des Dienstes, den wir in unserem Betrieb schützen müssen.
Im vorherigen Artikel zu diesem Thema haben wir darüber gesprochen, wann BC oder DR eingesetzt werden sollte, und wir haben uns auf die Art der Dienstleistung konzentriert, um zu verstehen, ob wir Business Continuity oder Disaster Recovery benötigen.
In dem genannten Beispiel wurde ein Notfalldienst, der BC benötigt, mit einem Logistikdienst verglichen, der auf der Grundlage einer Kosten-Nutzen-Analyse (RTO/RPO) unbedingt eine BC-Infrastruktur benötigt.
** Auch hier ist es die Art der Dienstleistung, die uns zu autonomen oder menschlichen Entscheidungen bewegen wird.**
Nehmen wir als Beispiel einen Notrufdienst wie die 112. Dieser Dienst erfordert naturgemäß die Koordinierung mehrerer Organisationen wie Krankenwagen, Feuerwehr, Polizei usw. in einem bestimmten Gebiet. Es liegt daher in der Natur der Sache, dass ein 118-Dienst über einen Disaster-Recovery-Standort verfügen muss, der im Falle eines Ausfalls oder einer Nichterreichbarkeit des Hauptstandorts die Koordinierung sehr schnell fortsetzen kann.
Wie lange wird es dauern, bis der Betrieb wieder aufgenommen werden kann?
Typischerweise muss ein solcher Dienst innerhalb von maximal 15 Minuten einsatzbereit sein. Eine Zeit, die daher nicht mit einer menschlichen Entscheidung vereinbar ist, die u. a. zum Zeitpunkt des Ereignisses nicht verfügbar sein kann. Die Entscheidung, auch wenn es sich um eine DR-Infrastruktur handelt, muss notwendigerweise von einem autonomen Entscheidungssystem getroffen werden, um innerhalb des SLA (Service Level Agreement) in Übereinstimmung mit dem für diesen Dienst festgelegten RTO (Recovery Time Object) Parameter zu sein.
Aufgrund welcher Parameter entscheidet das Katastrophenkomitee, DR für Dienste zu aktivieren, die keine automatische Entscheidung erfordern?
Je nach Komplexität des Dienstes sind die grundlegenden Fragen, die eine Entscheidung über die Aktivierung des DR-Standorts bestimmen, die folgenden:
- Ist der Hauptdienst dauerhaft beeinträchtigt?
- Wann wurde der letzte DR-Test durchgeführt?
- Wie viel kostet es mich, nach der Aktivierung der DR-Site wieder zur Hauptsite zurückzukehren?
Dauerhafte Beschädigung des Hauptstandorts bedeutet eine Beschädigung, die es nicht erlaubt, ihn wieder zu aktivieren, es sei denn, die Kosten übersteigen die Kosten für die Wiederherstellung des Normalzustands nach Beendigung des Notfalls (Fail-Back), kombiniert mit dem Wissen um die Güte der Aktivierungsverfahren des DR-Standorts und dem letzten erfolgreichen DR-Test.
Bei der Entscheidung, vom Hauptstandort auf den DR-Standort umzuschalten, müssen die Punkte 2 und 3 berücksichtigt werden. Aus diesem Grund ziehen es viele Unternehmen vor oder sind gezwungen, die DR-Dienste nicht zu aktivieren, indem sie vielleicht Hunderte von Zweigstellen mit Tausenden von Mitarbeitern geschlossen halten und auf die Wiederherstellung des Hauptstandorts warten, anstatt den DR-Standort zu aktivieren. Sofern der Hauptstandort nicht dauerhaft außer Betrieb ist - zerstörerischer Brand, Überschwemmung oder Naturkatastrophe - wird der DR-Standort in komplexen Umgebungen wahrscheinlich nicht ohne Weiteres aktiviert, es sei denn, dies ist unbedingt erforderlich.
Aber wenn meine Dienstleistungen kritisch sind und ich schnelle und daher automatische Entscheidungen brauche, welche Parameter sollten dann meine Wahl leiten?
-
Zunächst einmal muss geprüft werden, ob der Gesprächspartner, der mir eine Lösung vorschlägt, mit anderen quorum-basierten Algorithmen vertraut ist, um Vereinfachungen zu vermeiden, die insbesondere bei kritischen Diensten gefährlich sein können.
-
Zweitens, aber nicht zuletzt, prüfen Sie mit einem "Raster der Ereignisse" die Möglichkeiten des Versagens und legen Sie fest, welche Abhilfemaßnahmen die einzelnen Elemente in allen Situationen durchführen werden. Der Fokus muss von einem Totalausfall bis zu einem Teilausfall reichen, wobei die logischen Split Brain-Phänomene, die heimtückischsten, die die Daten aus logischer Sicht beeinträchtigen können und somit Wiederherstellungskosten oder sogar Datenverluste verursachen, die nicht im Voraus kalkulierbar sind, gebührend zu berücksichtigen sind. Ein Beispiel für ein Ereignisraster kann wie folgt beschrieben werden:
| Ereignis | Auswirkungen auf das Primärsystem | Auswirkungen auf das Sekundärsystem | Erwartetes Ergebnis* |
|---|---|---|---|
| Ausfall des Heartbeat-Netzes zwischen den beiden Standorten | Xxxx | Yyyy | Zzzz |
| Ausfall des öffentlichen Netzes, Nichterreichbarkeit von Diensten | Xxxx | Yyyy | Zzzz |
| Ausfall des Quorum-Netzes der primären | Xxxx | Yyyy | Zzzz |
| Ausfall des Primärspeichers | Xxxx | Yyyy | Zzzz |
| Ausfall des Sekundärsystems | Xxxx | Yyyy | Zzzz |
| Ausfall des sekundären Systems und Nichterreichen des Quorumssystems | Xxxx | Yyyy | Zzzz |
| Ausfall eines Teils der AAA-Dienste | Xxxx | Yyyy | Zzzz |
| … | |||
| … |
Was ist ein Split Brain?
Split Brain bezieht sich auf das Ereignis, in dem beide Standorte, der primäre und der sekundäre, sich als alleinige Überlebende betrachten und die Entscheidung treffen, beide primär zu werden.
Dieser Fall ist, wie bereits erwähnt, der schlimmste, da die Archive und Datenbanken nicht physisch, sondern logisch beschädigt werden. Logische Verfälschung bedeutet, dass z. B. ein Schlüssel mit einem progressiven Wert von 101 an einem Standort den Wert "Herr Bianchi" und am anderen Standort den Wert "Herr Verdi" erhält. Diese Art der Vermischung von Daten macht eine Neuordnung der Datenbanken zwischen den beiden Standorten praktisch unmöglich oder zu kostspielig und führt fast immer zum Verlust einiger Informationen.
Kann Split Brain vermieden werden?
Ja, das kann man vermeiden, indem man die Szenarien beschreibt und sie in ein Raster einträgt, um jedes mögliche Ereignis mit den geplanten Aktionen zu überprüfen. Dann kommen Sie zu einer Schlussfolgerung, die wir "Quorum Games" nennen, bei denen niemand, wie bei dem Spiel Tic Tac Toe, als Sieger hervorgeht, und deshalb wollten wir es "Quorum Games" nennen, in Anlehnung an den berühmten Film "Wargames", bei dem niemand gewinnt, sondern der gesunde Menschenverstand Sie zu einer Lösung führt. Quorum Games" wird das Thema des nächsten Artikels sein, der sich speziell mit dem Algorithmus und der Vermeidung von Entscheidungsblockaden beschäftigt.
Was kann Oplon Networks tun, um maximale Zuverlässigkeit zu erreichen??
Auf der Grundlage langjähriger Erfahrung mit mission-critical und business-critical Anwendungen entwickelt und fertigt Oplon Networks Produkte, die die Zuverlässigkeitsanforderungen großer und kleiner Unternehmen erfüllen, die sich keine Datenverluste oder Serviceunterbrechungen leisten können.
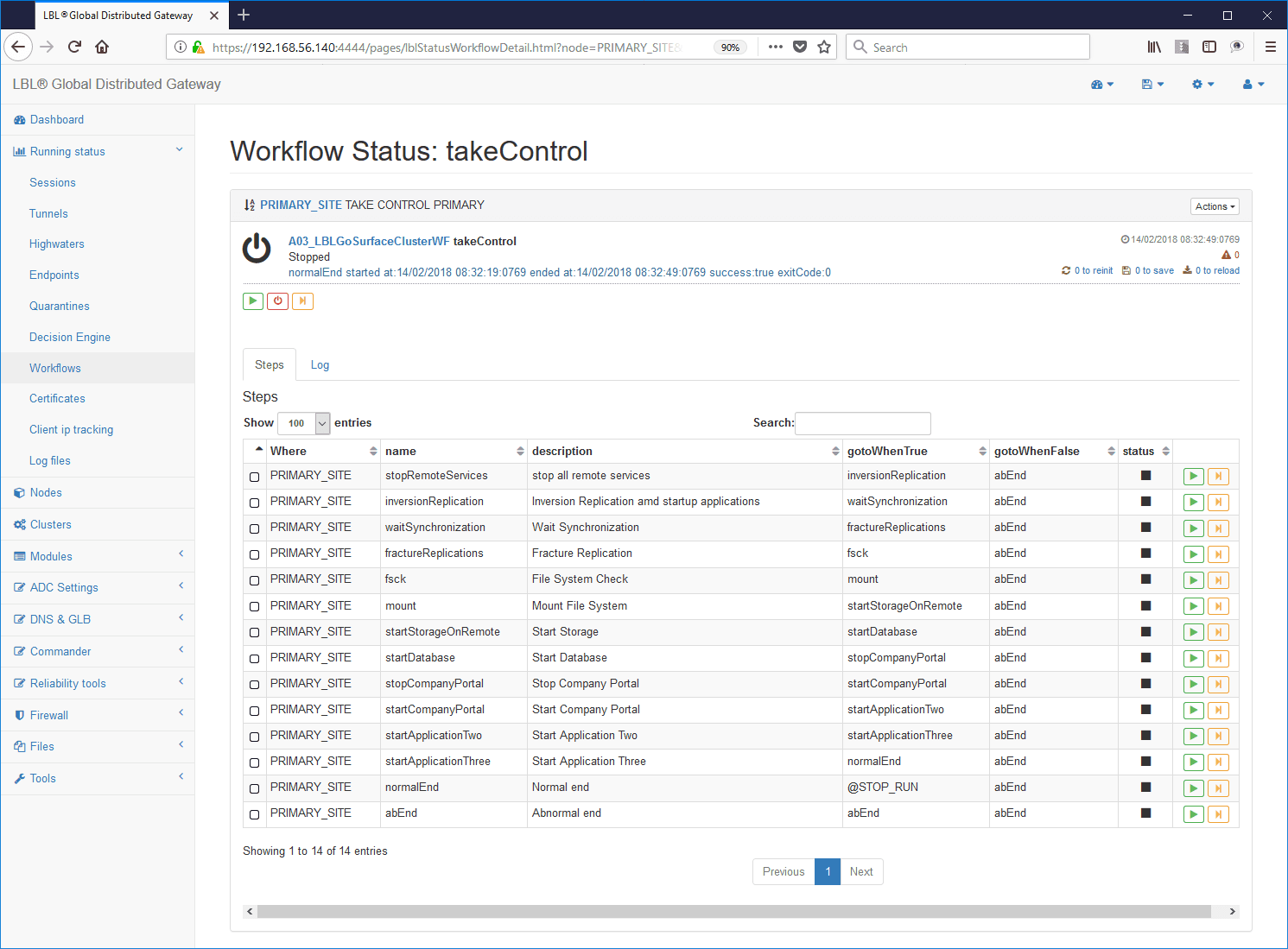
Zur Unterstützung kritischer Infrastrukturen ermöglichen die Produkte Oplon Commander Decision Engine und Oplon Commander Workflow, die in das System Oplon Application Delivery Controller integriert sind, eine vollständige Kontrolle der Vorgänge in kritischen Einsatzgebieten, in denen die Zuverlässigkeit im Dienste der Kontrolle stehen muss.
Beispiel einer Decision Engine für eine kritische Situation in einem Dienst:
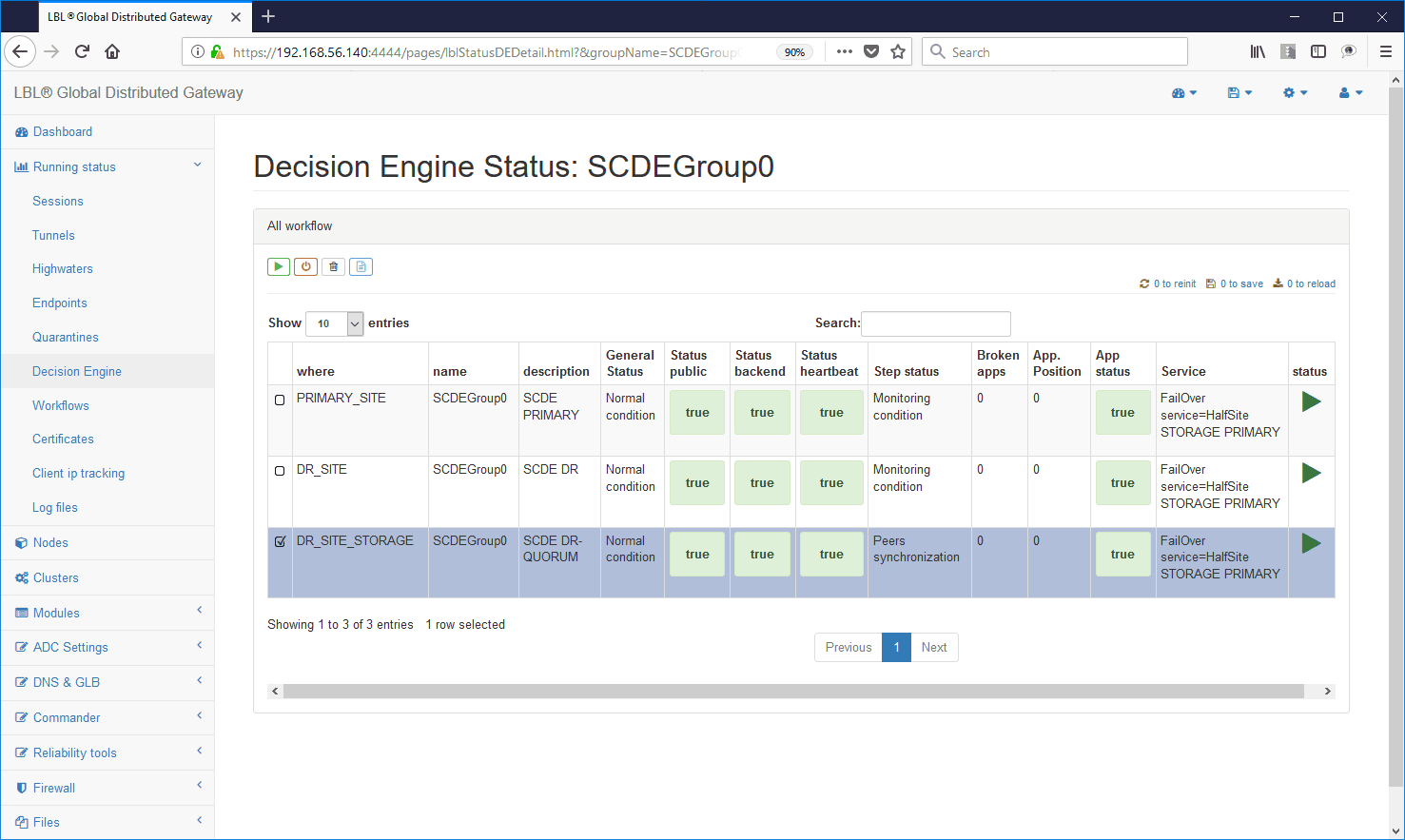
Workflow-Beispiel mit selbst dokumentierten Verfahrensschritten: