Commander setup
Installazione
Per installare Oplon Commander si deve procede con l'installazione di base disponibile nel manuale di installazione e setup.
Oplon Commander introduzione
Oplon Commander introduce un nuovo concetto di alta affidabilità in ambito applicativo andando a ricoprire il ruolo di coordinatore delle attività in un datacenter mission-critical. Oplon Commander è composto da due moduli principali: Oplon Commander Work Flow e Oplon Commander Decision Engine. I due moduli sono stati progettati per lavorare in cooperazione tra loro oppure, nel caso non siano richieste delle operazioni automatiche riguardanti la disponibilità dei sistemi, è possibile utilizzare il solo componente Oplon Commander Work Flow*.* Oplon Commander è stato progettato per cooperare con Oplon ADC.
Proprio la caratteristica di separazione delle attività tra Oplon Commander Work Flow, cosa si deve fare, e Oplon Commander Decision Engine, quando deve essere fatto, ci permette di suddividere l'installazione in due fasi controllando prima in maniera manuale tutti i flussi e quindi, se richiesta un'operatività automatica, procedere con l'installazione di Oplon Commander Decision Engine.
Per questo motivo il manuale è diviso in questa sequenza su due capitoli, uno riguardante l'installazione di Oplon Commander Work Flow l'altro riguardante l'installazione di Oplon Commander Decision Engine.
Oplon Commander Work Flow introduzione
L'installazione del modulo Oplon Commander Work Flow necessita di un'analisi preventiva degli obiettivi che si vogliono perseguire in quanto per sua natura Oplon Commander Work Flow è uno strumento in grado di effettuare qualsiasi operazione gli venga schedulata.
Per questo manuale utilizzeremo un esempio di minima dove si gestirà un processo Apache Tomcat nel suo ciclo di vita: Start, Shutdown (N.B.: Quando si parla di shutdown si intende lo stop delle applicazioni e non del sistema operativo che le ospita). Volendo poi riutilizzare lo stesso esempio anche per la componente Oplon Commander Decisione Engine. Per il momento identificheremo due tipi di job: normalPrimer (innesco primario) e gracefulShutdown (spegnimento controllato delle applicazioni).
Oplon Commander Work Flow progettazione
Oplon Commander Work Flow parte dal presupposto che qualsiasi operazione complessa possa essere scomposta in oggetti elementari.
La prima operazione da effettuare è quindi l'individuazione dei lavori da eseguire (Work Flows) e delle attività all'interno di ogni singolo lavoro (steps).
Volendo ad esempio eseguire lo start di un processo Apache Tomcat dovremo prima di tutto identificare con un nome il tipo di lavoro. In questo caso sceglieremo normalPrimer come nome identificativo del Work Flow di innesco dello start del processo. Sicuramente ad uno start dovrà essere reso possibile eseguire anche uno stop controllato. A questo scopo identificheremo anche un nome per eseguire questa lavoro: gracefulShutdown.
Una volta identificati i lavori da svolgere andremo a verificare per ogni lavoro (Work Flow) gli step caratteristici.
In questo caso per il Work Flow normalPrimer sicuramente dovremo utilizzare uno step che lancerà tomcat (es.: startupTomcat) e uno step che andrà a terminare l'esecuzione di tomcat (es.: shutdownTomcat).
Altra operazione è l'identificazione degli step di terminazione dei Work Flow. Per convenzione un Work Flow può terminare con normalEnd se l'operazione va a buon fine e uno step con nome abEnd (abnormal end) nel caso l'operazione non terminasse con successo.
Come vedremo in seguito gli step normalEnd e abEnd sono abbastanza costanti in tutti i tipi di Work Flow identificando la fine corretta o anomala di un Work Flow.
Una volta identificati gli step tipici del nostro progetto potremo concentrarci sullo sviluppo dei comandi che porteranno alla definizione dei nostri Work Flow.
Oplon Commander Work Flow piano degli indirizzi
Essendo Oplon Commander Work Flow un servizio disponibile sulla rete è necessario effettuare il piano degli indirizzi per poter identificare su quali server e relative reti sarà reso disponibile. Il servizio viene erogato in forma di Remote Workflow Command (RWC) in modalità sicura (HTTP-SSL) autenticata. È possibile identificare uno o più Oplon Monitor che attraverso la loro Web Console possono interagire con Oplon Commander Work Flow. Oplon Commander Work Flow è utilizzato anche da Oplon Commander Decision Engine nel caso siano previsti degli automatismi di innesco a fronte di eventi applicativi.
Il piano degli indirizzi per Oplon Commander Work Flow è molto semplice e si può attuare attraverso una semplice tabella come ad esempio quella proposta di seguito:
| Hostname/Address | Port number | Description |
|---|---|---|
| legendonebackend | 54444 | HalfSite A.A |
| legendtwobackend | 54444 | HalfSite B.B |
NOTA: I nodi/sedi sono identificati da lettere divise da una punteggiatura. La punteggiatura indica la profondità infrastrutturale. La prima lettera indica il contesto con le eventuali relazioni con motori decisionali Oplon Commander Decision Engine. Riportiamo nuovamente lo schema architetturale generale per comodità espositiva.
Oplon Commander Work Flow Web Console
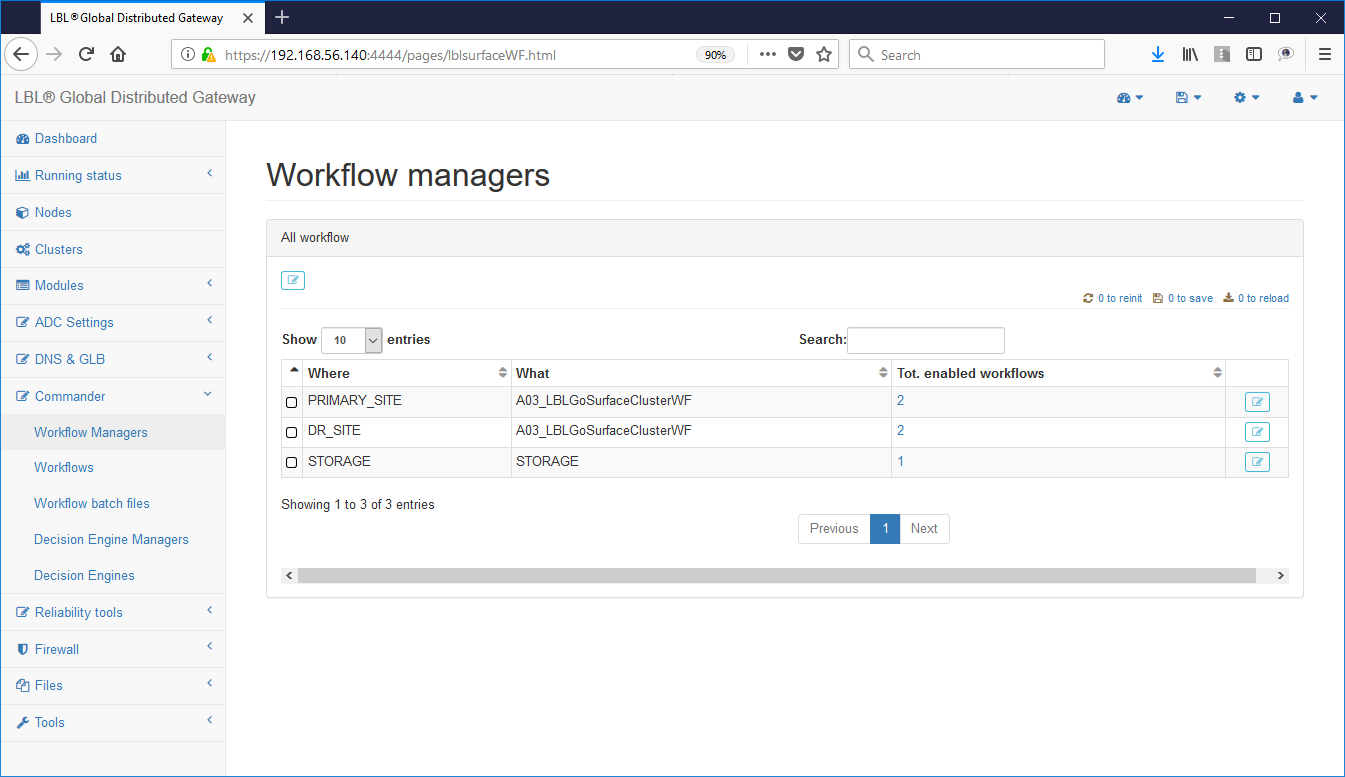
Oplon Commander Work Flow directory e files
Oplon Commander Work Flow utilizza solamente due directory ed un file di configurazione più il file di licenza.
Le directory di default sono:
(LBL_HOME)procsProfiles/A03_LBLGoSurfaceClusterWF/surfaceClusterWFCommandDir
(LBL_HOME)/procsProfiles/A03_LBLGoSurfaceClusterWF/conf
contiene la licenza ed il file di configurazione surfaceclusterwf.xml
(LBL_HOME)/procsProfiles/A03_LBLGoSurfaceClusterWF/surfaceClusterWFCommandDir
è la directory di default degli script/eseguibili che verranno avviati dagli step di un Work Flow. Le distribuzioni riportano in questa directory i file batch con in nomi tipici di un flusso di take-over di un sito:
Per ambienti UNIX / Linux:**
unix/flushDisk.sh
unix/fractureReplications.sh
unix/fsck.sh
unix/inversionReplication.sh
unix/mountFileSystem.sh
unix/restartApache.sh
unix/selfTest.sh
unix/shutdownApplicationOne.sh
unix/shutdownApplicationThree.sh
unix/shutdownApplicationTwo.sh
unix/startApplicationOne.sh
unix/startApplicationThree.sh
unix/startApplicationTwo.sh
unix/startDatabase.sh
unix/umountFileSystem.sh
unix/waitSynchronization.sh
unix/checkApacheActivity.sh
PerambientiMSWindows:
windowslushDisk.bat
windowsfractureReplications.bat
windowsfsck.bat
windowsinversionReplication.bat
windowsmountFileSystem.bat
windowsrestartApache.bat
windowsselfTest.bat
windowsshutdownApplicationOne.bat
windowsshutdownApplicationThree.bat
windowsshutdownApplicationTwo.bat
windowsstartApplicationOne.bat
windowsstartApplicationThree.bat
windowsstartApplicationTwo.bat
windowsstartDatabase.bat
windowsumountFileSystem.bat
windowswaitSynchronization.bat
windowscheckApacheActivity.bat
Ognuno di questi file contiene un template di minima pronto per essere popolato con gli opportuni comandi della piattaforma interessata. A titolo di esempio di seguito il contenuto dei comandi sopra elencati. Per ragioni di praticità, soprattutto per i batch file MS Windows, all'inizio di ogni comando sul primo parametro viene distinta una modalità interattiva da una modalità batch. Questo è comodo in fase di implementazione perché nella modalità interattiva non viene eseguito l'EXIT che porterebbe su MS Windows all'uscita della finestra di lancio. In questo caso invece verrà visualizzato il return code con il quale sarebbe uscito il batch file all'EXIT.
Ovviamente per quello che riguarda Oplon Commander Work Flow l'unico valore utilizzato è il return code e quindi questi esempi sono solo da intendersi come traccia completamente modificabile.
MS Windows
Linux
È possibile effettuare le stesse operazioni anche direttamente dalla console web attraverso le seguenti operazioni:
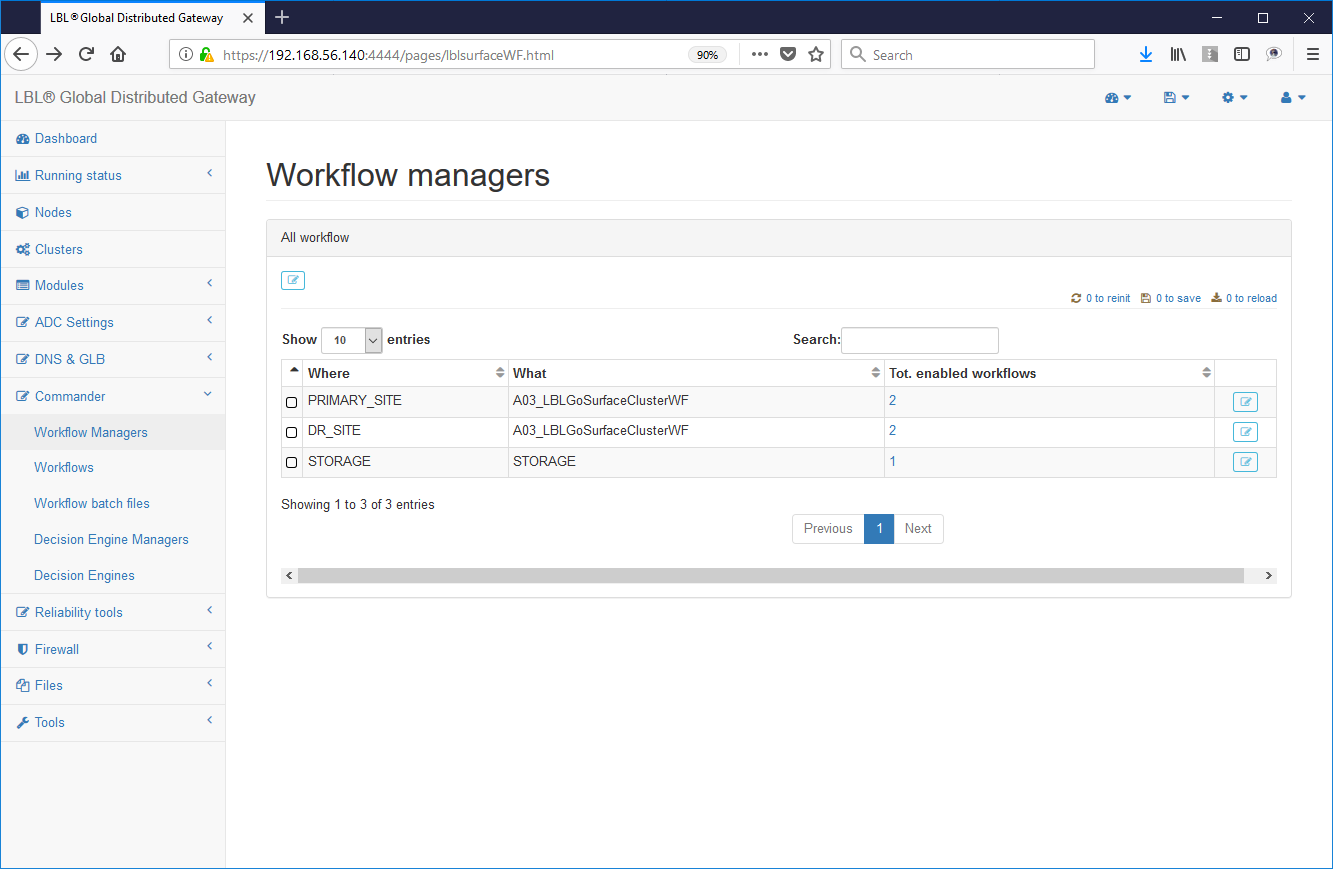 Commander-> Wirkflow Managers -> Scelta
del modulo
Commander-> Wirkflow Managers -> Scelta
del modulo
Scelta del workflow
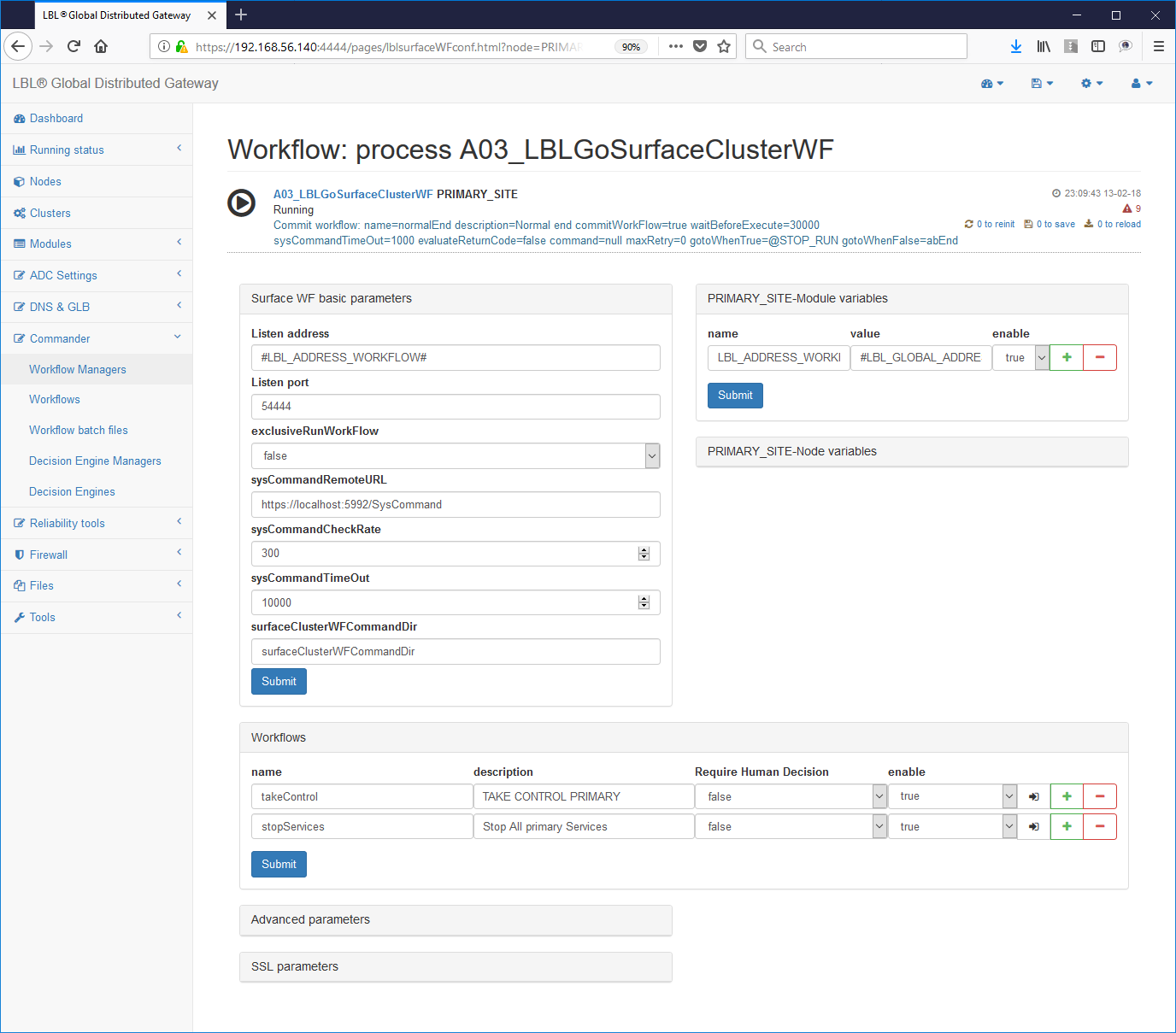
Scelta dello step da editare es.:
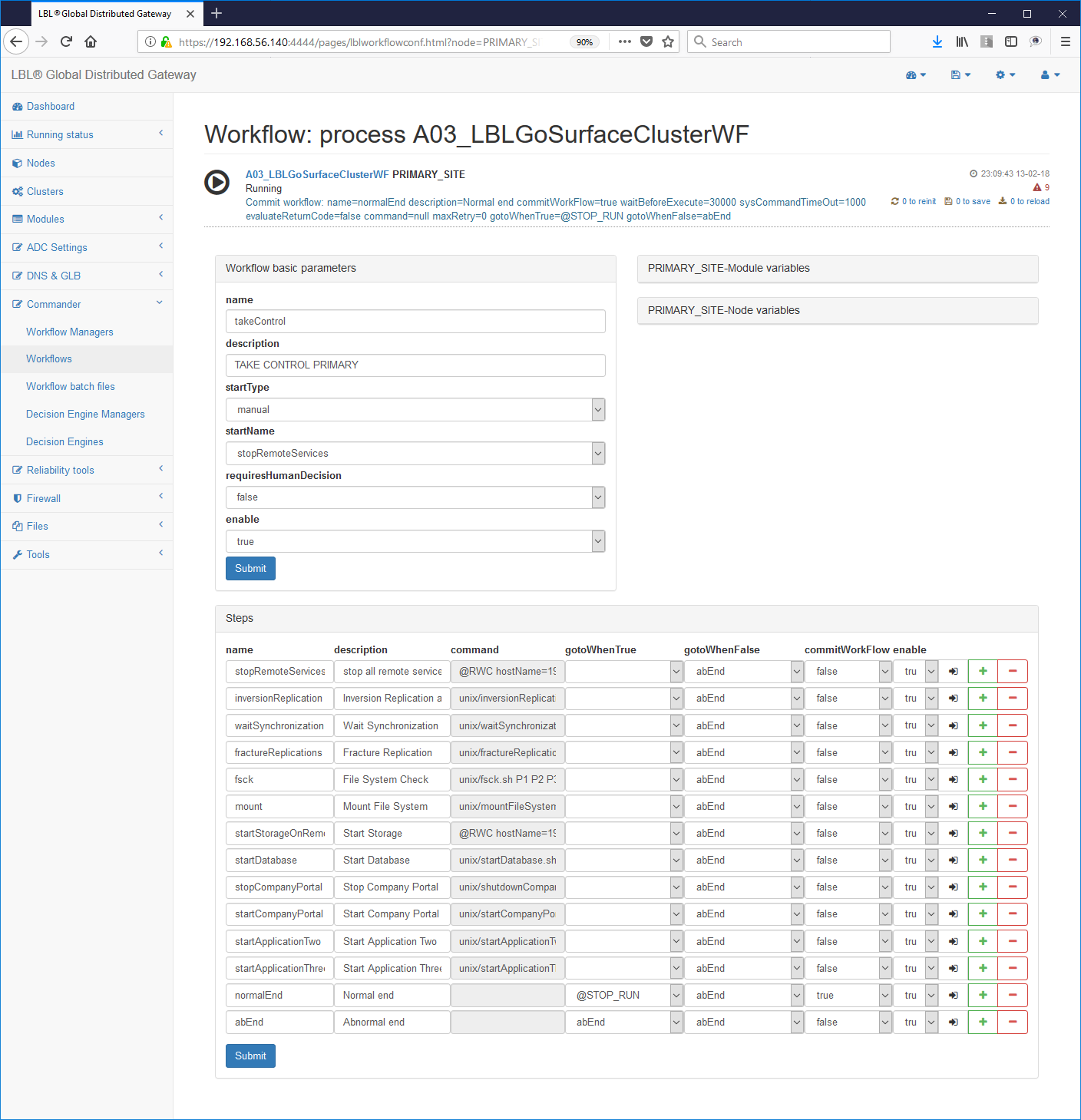
Editing dello script:
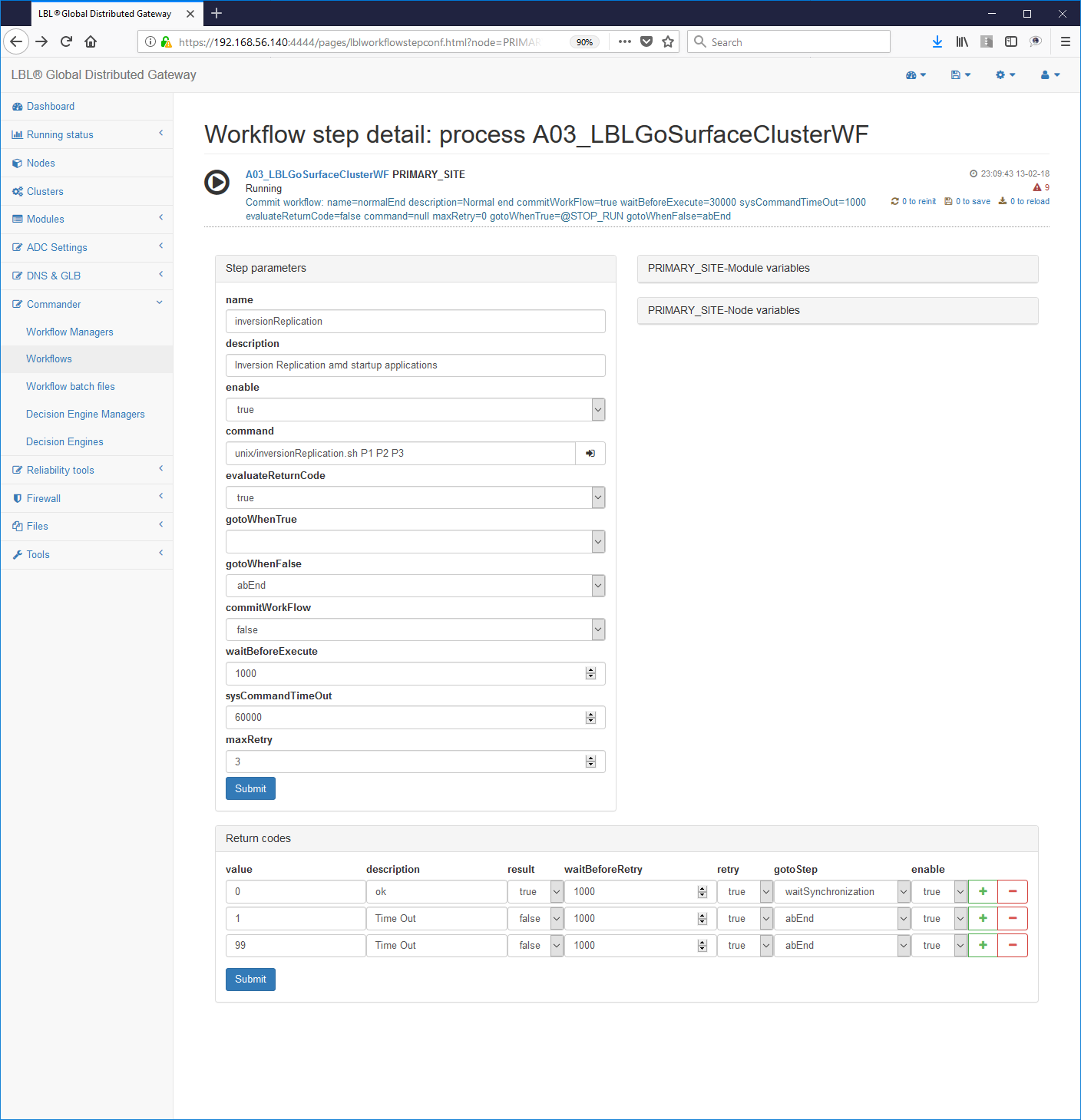
Edit
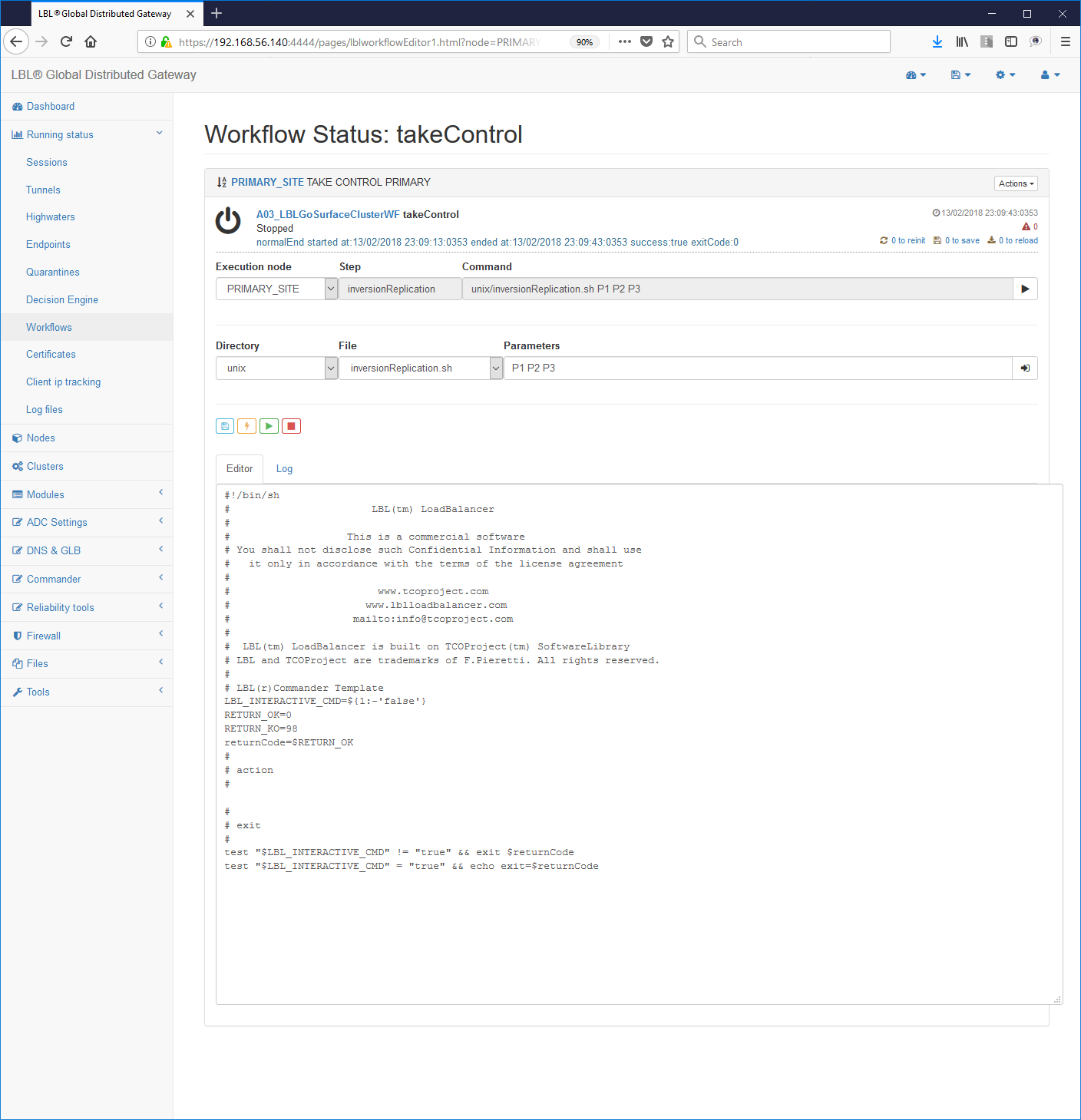
Oplon Commander Work Flow implement batch files
Il primo passo quindi nell'implementazione e installazione di un Work Flow è l'analisi degli step da eseguire e quindi la scrittura e test dei singoli step per poi passare al loro inserimento in un flusso di lavoro.
Per i nostri scopi copieremo un qualsiasi batch distribuito in:
MS Windows
cd (LBL_HOME)procsProfilesA03_LBLGoSurfaceClusterWFsurfaceClusterWFCommandDir
copy selfTest.bat tomcatStartup.bat
Linux
cd (LBL_HOME)/procsProfiles/A03_LBLGoSurfaceClusterWF/surfaceClusterWFCommandDir
cp selfTest.sh tomcatStartup.sh
Per entrambe le piattaforme, ma specialmente su MS Windows, è importante accertarsi che i comandi eseguiti nei batch file non eseguano degli exit autonomi, impliciti o espliciti. Per fare questa prova è sufficiente utilizzare un unico punto di uscita nei propri batch e verificare con apposita segnalazione l'avvenuto passaggio (comune pratica di buona programmazione).
Nei nostri specifici casi andremo a popolare i nostri nuovi batch file con le operazioni di start per Tomcat.
Di seguito i file di start con evidenziate le linee di comando utilizzate per eseguire lo start e lo stop delle istanze tomcat.
MS Windows tomcat startup:
In questo caso durante i test ci siamo accorti che lo start di tomcat in ambiente Windows torna sempre 1 anche se l'operazione è andata a buon fine. Abbiamo preferito non modificare tale comportamento ma evidenziarlo a livello di commento e quindi riportare la logica, come vedremo in seguito, sullo step di esecuzione di questo batch. In questo modo abbiamo documentato questo comportamento sul flusso e non abbiamo aggiunto logica all'interno del programma di lancio. Inoltre non avendo modificato i file relativi all'applicativo porterà un indubbio vantaggio nelle manutenzioni successive che non devono tenere conto di modifiche da riportare nuovamente agli applicativi ad ogni aggiornamento.
Se proviamo ad eseguire da command line questo comando si otterrà questo risultato:
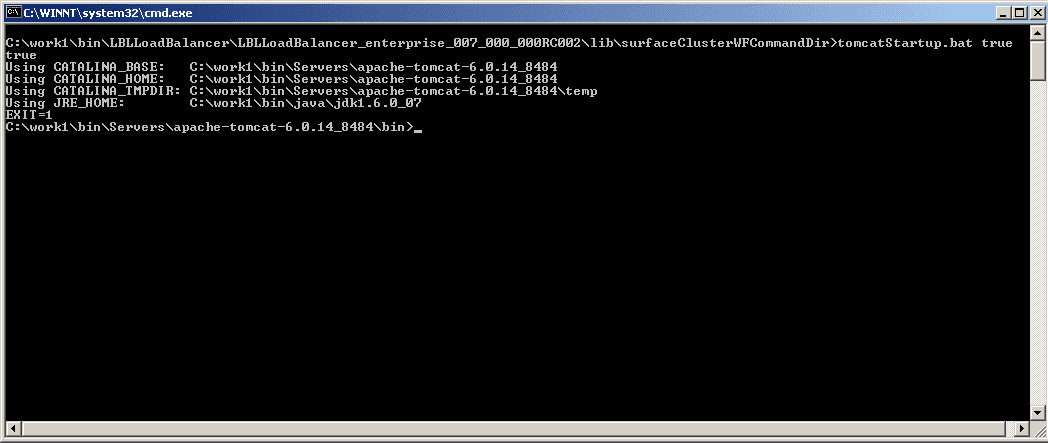
 La stessa implementazione è stata
introdotta nel comando di tomcatShutdown.bat con il comando di shutdown:
La stessa implementazione è stata
introdotta nel comando di tomcatShutdown.bat con il comando di shutdown:
Linux
In ambiente Linux le implementazioni da effettuare sono le stesse ovviamente con le differenze dovute al linguaggio di script utilizzato ed eventuali differenze di comportamento.
Di seguito l'esempio con l'impostazione dei batch file tomcatStartup.sh:
tomcatShutdown.sh
Come si può notare una differenza tra lo start su MS Windows e Linux è il return code che in questo caso torna 0 se l'operazione è andata a buon fine.
Effettuando le operazioni da command line si otterrà il seguente risultato:

Con i limiti di questi esempi e a conclusione di questo capitolo possiamo constatare che abbiamo cominciato a scrivere la nostra libreria di "oggetti" riutilizzabili su diverse piattaforme per diversi progetti. Resta ora da determinare l'utilizzo di questi oggetti all'interno di flussi logici di lavoro.
Oplon Commander Work Flow build Work Flows
Una volta ultimati ed eseguiti i test dettagliati dei comandi di base per la realizzazione dei nostri flussi di lavoro resta da implementare la logica di contesto nei Work Flow che vogliamo realizzare.
La parametrizzazione del Workflow inizia dall'impostazione dell'indirizzo dove verranno accettati i comandi: Tipicamente non dovrà essere effettuata nessuna modifica perché il sistema è già predisposto ad accettare comandi nell'indirizzo di management.
Commander->WorkFlow Managers -> Scelta del workflow
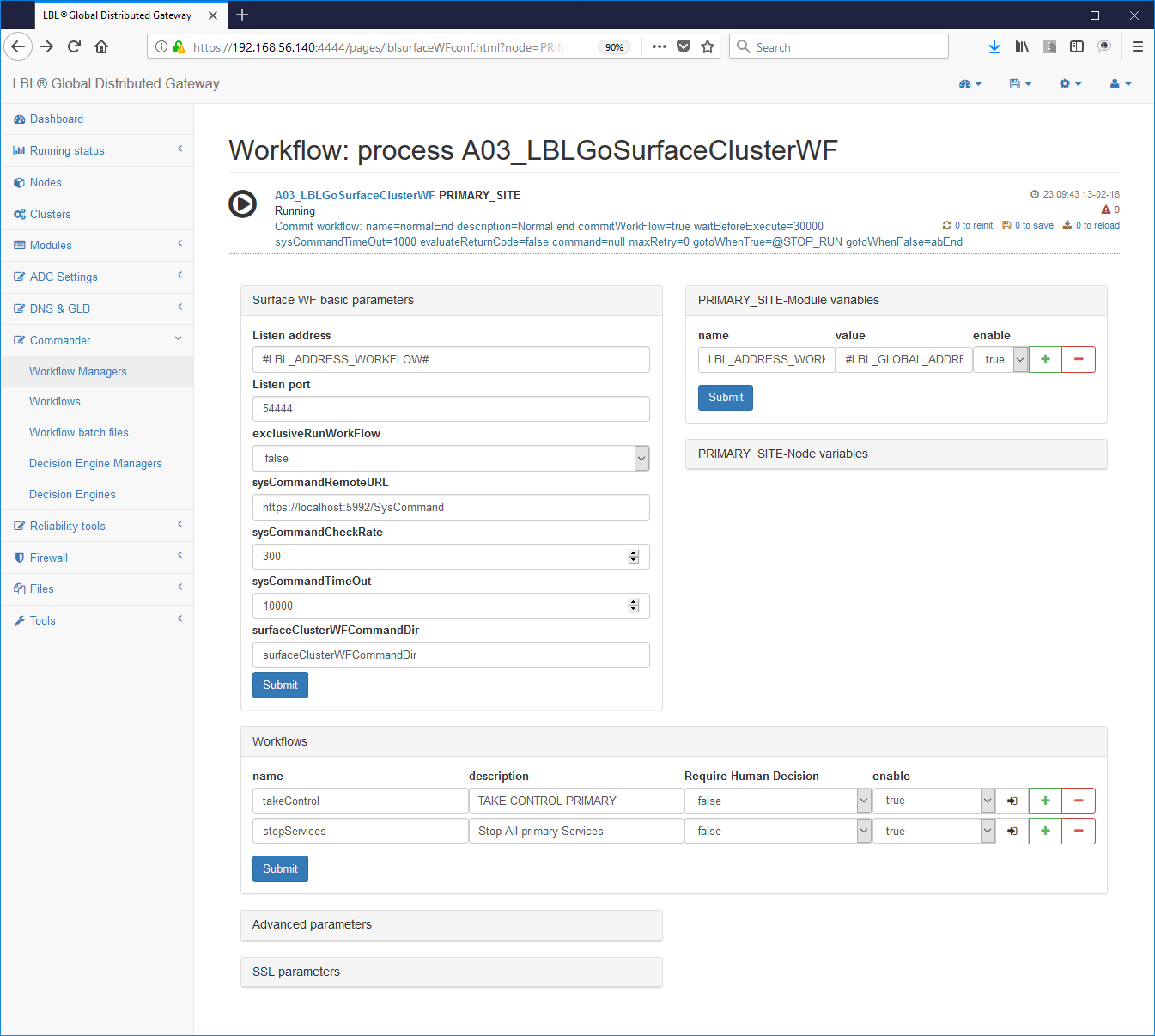
Un altro valore interessante è il valore: exclusiveRunWorkFlow="false"
Questo parametro indica se l'intero Work Flows Engine può avere nello stesso momento più Work Flow in stato di running. Per i nostri scopi l'impostazione a "false", cioè più Work Flow possono essere lanciati contemporaneamente, è l'opzione corretta. È da ricordare che comunque il Work Flows Engine non permette, indipendentemente da questo parametro, di lanciare contemporaneamente uno stesso Work Flow. In altre parole se il Work Flow con nome normalPrimer in stato di Running non può essere ulteriormente lanciato mentre può essere lanciato contemporaneamente il Work Flow gracefulShutdown. Nel caso fosse stato impostato exclusiveRunWorkFlow="true" e il Work Flow normalPrimer fosse in stato di Running non riusciremmo a lanciare nessun altro Work Flow compreso gracefulShutdown, fino al termine di normalPrimer.
Una volta terminata l'impostazione per poter rendere accessibile dall'esterno l'utilizzo del sistema Workflow si passa al paragrafo successivo che contiene i Work Flow con le azioni suddivise in singoli step.
Nel nostro caso dovremo arrivare ad avere due Work Flow per poter eseguire lo start e lo stop del processo Tomcat come da specifiche che ci siamo posti inizialmente.
Il risultato finale per lo start dovrà essere simile a quando descritto
di seguito dove sul capitolo <workFlow> si potranno vedere i parametri
name="normalPrimer", il nome di quel particolare work flow, la
descrizione sintetica ed il nome dello step con cui iniziare il flusso
di lavoro startName="startupTomcat":
I parametri relativi ad ogni step sono abbastanza intuitivi e quindi ci soffermeremo solo su alcuni di essi. Una completa trattazione di ogni singolo parametro e del loro comportamento si può trovare nella Reference Guide.
I parametri significativi su cui soffermarci sono il comando che verrà eseguito nello step command="tomcatStartup.bat", e lo step "normalEnd" con il parametro commitWorkFlow="true". Quest'ultimo parametro indica che lo step è un punto di consistenza e quindi non produrrà log dopo la prima volta. In questo caso lo step entra in un loop senza possibilità di uscita e questo è un comportamento voluto. Come vedremo in seguito questo comportamento è stato sfruttato per non dare la possibilità di doppia esecuzione dello stesso workFlow nello stesso momento. È buona norma in produzione mettere in loop il workFlow effettuando periodicamente un HealthCheck del servizio, ad esempio attraverso wget in questo caso, ed uscire per return code con eventuali azioni di riparazione come potrebbe essere un restart o la segnalazione del problema.
Già da questo momento è possibile avviare Oplon Commander Work Flow e verificarne l'effetto. Per poter essere visualizzato dalla Web Console è necessario aver impostato il file monitor.xml con i riferimenti al server Oplon Commander Work Flow che si vuole visualizzare come specificato nel paragrafo visto in precedenza.

Seguendo gli HiperLink è possibile verificare step per step il percorso effettuato dal Work Flow una volta avviato.
E' consigliato già da questo momento effettuare il run per verificarne gli effetti ed il funzionamento. In caso di Work Flow complessi è possibile effettuare il run uno step alla volta utilizzando il pulsante "Step action" sulla destra di ogni step.
Se i test di questo primo Work Flow sono andati a buon fine è possibile passare allo sviluppo del prossimo Work Flow per l'esecuzione dello shutdown controllato del servizio Apache Tomcat.
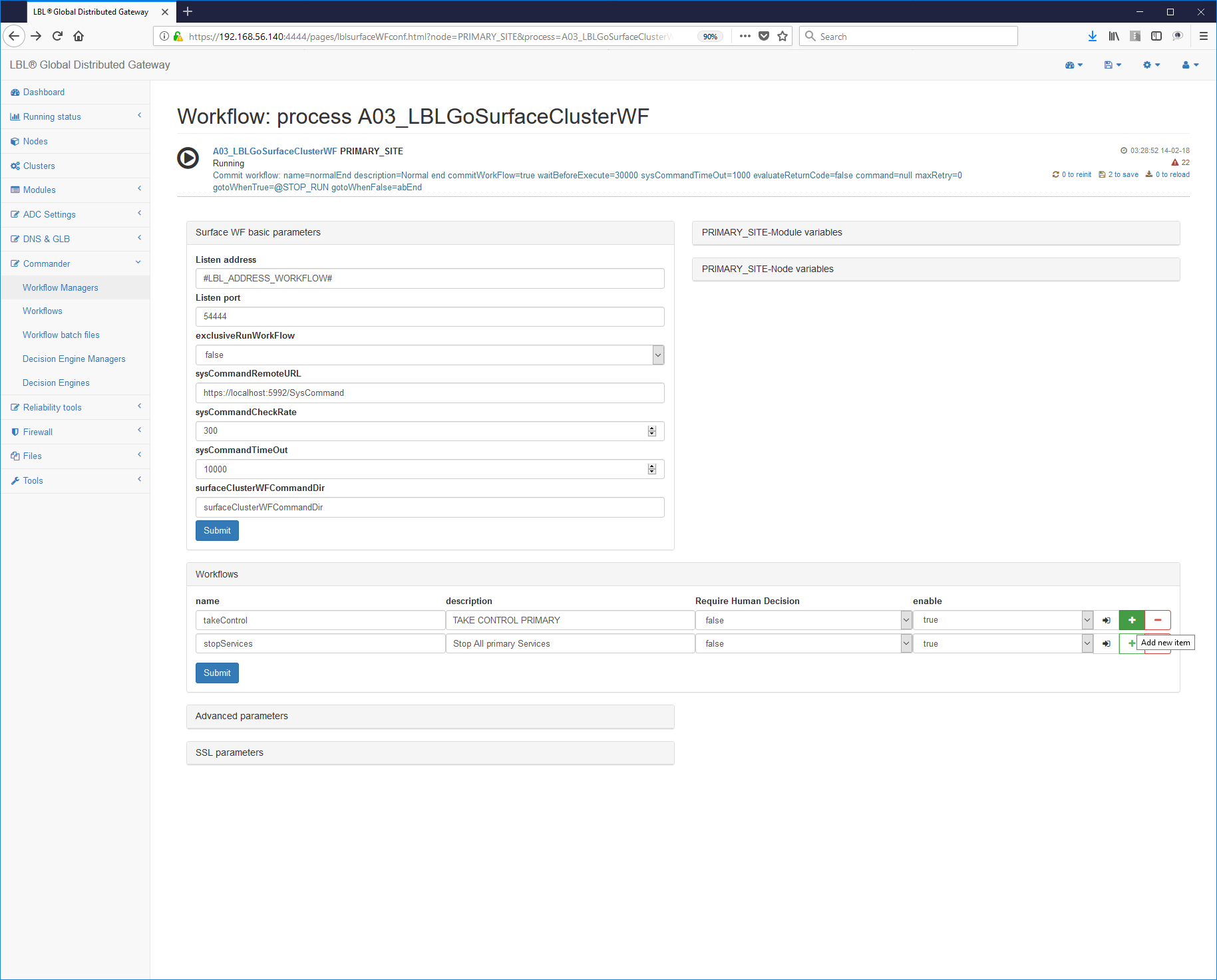
Attraverso la propria interfaccia di amministrazione eseguendo lo Stop e lo Start del processo Oplon Commander Work Flow è possibile gestire anche questo nuovo Work Flow.
Seguendo l'Hyperlink del nuovo Work Flow se ne può verificare il percorso:
In maniera molto semplice è possibile ora gestire da remoto lo start e lo stop del processo Apache Tomcat.
Oplon Commander Work Flow distribuited events (@RWC)
Dalla versione 7.1 è possibile eseguire all'interno di uno step in un workflow un ulteriore comando di start workflow remoto (@RWC). Questa funzionalità permette al "Sistema Commander Work Flow" di eseguire delle operazioni distribuite. Con questa funzionalità è possibile quindi propagare un processo di WorkFlow dagli strati più alti ai più bassi o viceversa su diverse piattaforme per eseguire quindi operazioni articolate su tutte le componenti che formano l'applicazione. La disponibilità applicativa infatti è la somma di disponibilità di molti strati, dalla disponibilità dei dati, sistemi di memorizzazione di massa, alla disponibilità di servizi di database, alla disponibilità di servizi di directory fino ad arrivare alla disponibilità dei servizi applicativi forniti dagli application server e alla disponibilità di connettività.
Questi servizi sono su sistemi fisicamente separati, a volte anche geograficamente, e nasce quindi la necessità di "governare" in maniera distribuita ma coordinata tutti questi elementi. Pensiamo ad esempio di indurre un restart applicativo mirato. Per eseguire un'operazione di questo tipo bisogna identificare le risorse che concorrono a rendere disponibile il servizio e quindi una volta determinato quale sia il componente in "avaria" verificare la possibilità di ripristinare l'operatività. Una attività così articolata deve essere governata da procedure ben definite e collaudate in modo che possano essere scientificamente ripetibili. Con l'introduzione della funzionalità @RWC in uno step di un WorkFlow è possibile da un WorkFlow principale eseguire queste operazioni in maniera Centralizzata, Mirata, Localizzata, Automatizzabile.
-
Centralizzata Centralizzata perché in un unico Oplon Commander Work Flow Server è possibile indicare dei WorkFlow di management che innescano WorkFlow sui sistemi remoti.
-
Mirata E' possibile definire dei WorkFlow specializzati per innescare azioni di mantenimento sui singoli servizi
-
Localizzata Ogni singolo sistema di WorkFlow localizza le proprie gestioni del ciclo di vita applicativo
-
Automatizzabile Attraverso Oplon Commander Decision Engine è possibile automatizzare tutte le operazioni per fornire servizi di Business Continuity e/o Disaster Recovery.
Anche in questo caso una particolare attenzione deve essere posta nella semplicità di implementazione e utilizzo con tracciabilità documentata e implicita.
Per effettuare un'operazione di @RWC è sufficiente inserire nel
parametro "command" di un paragrafo <step> la keyword riservata
@RWC seguita dalle indicazioni di dove si vuole eseguire il comando
(hostName) e cosa si vuole eseguire (workFlow). Se si volesse quindi
eseguire il RWC di "startHealthCheckAndRestart" sul sistema "dbserver"
sarebbe sufficiente indicare:
command="*@RWC hostName=*dbserver *workFlow=*startHealthCheckAndRestart"
Il login e la password non sono presenti perché utilizzano Oplon Autonomous Delegated Authentication.
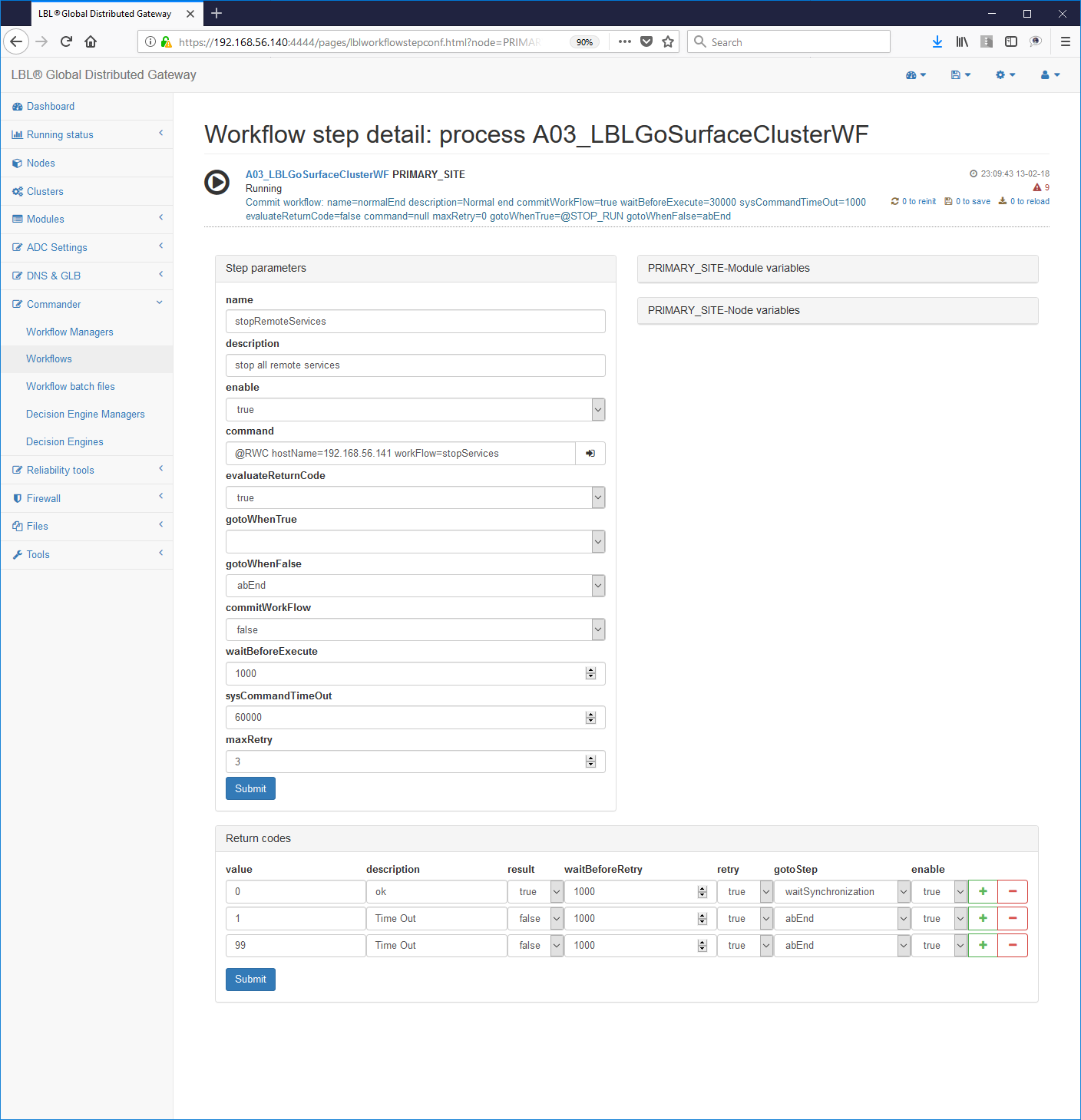
I parametri login e password verranno utilizzati anche in futuro per eseguire nuovi Inner Command.
La parametrizzazione completa del comando @RWC permette di eseguire tutte le operazioni di start, dallo start di un intero WorkFlow allo start di un WorkFlow con partenza da uno Step prefissato allo start di un singolo step.
Il comando completo con tutti i parametri è il seguente:
@RWC hosname=nome sistema o indirizzo bersaglio del RWC
[portNumber=port number sistema di SCWF] default 54444
[uriPath=Uripath del sistema SCWF] default /SCWFCommand
workFlow=workflow name
[step=nome dello step da lanciare, se "" dal primo] default
[command=runWorkFlow|stopWorkFlow] default "runWorkFlow"
[frhd=se true esegue solo lo step indicato] default falseEs. 1: start workflow dallo step secondStep
command="*@RWC hostName=*dbserver *workFlow=*startHealthCheckAndRestart step=secondStep"
Es. 2: start workflow del solo step secondStep
command="*@RWC hostName=*dbserver *workFlow=*startHealthCheckAndRestart step=secondStep frhd=true"
E' utile osservare che il lancio di un @RWC su sistemi remoti non produce un significativo codice di ritorno. @RWC notifica come errore solamente se non riesce a produrre uno start della procedura. Ogni procedura remota deve essere autoconsistente per disegno in modo che solo la disponibilità applicativa sia il fattore discriminante della funzionalità.
Oplon Commander Work Flow Remote Batch
Questo servizio permette di eseguire lo start di batch remoti per eseguire HealthCheck distribuiti in sicurezza. Si compone di un servizio Web, che risponde per default alla porta 5994, in grado di interpretare un file xml di profilo per il lancio di eseguibili o batch file.
L'installazione deve prevedere i seguenti step:
1- Verifcare che sia stata impostata la licenza d'uso Oplon Commander Work Flow
(LBL_HOME)/lib/confSurfaceClusterWF/license.xml
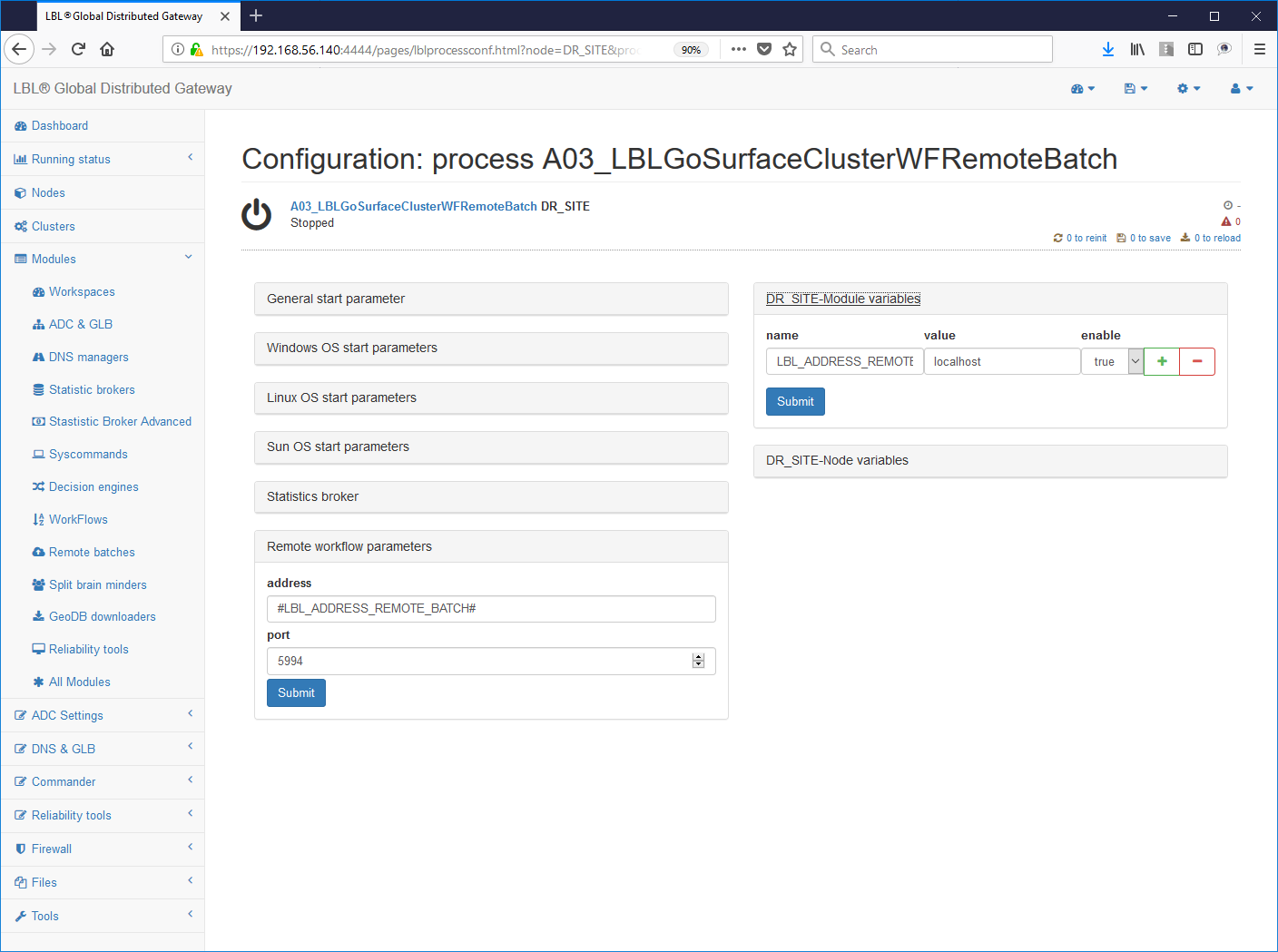 2- Impostazione La configurazione del
servizio
2- Impostazione La configurazione del
servizio
3- Eseguire lo start del servizio verificando il log con l'avvenuto listen all'indirizzo porta indicato:
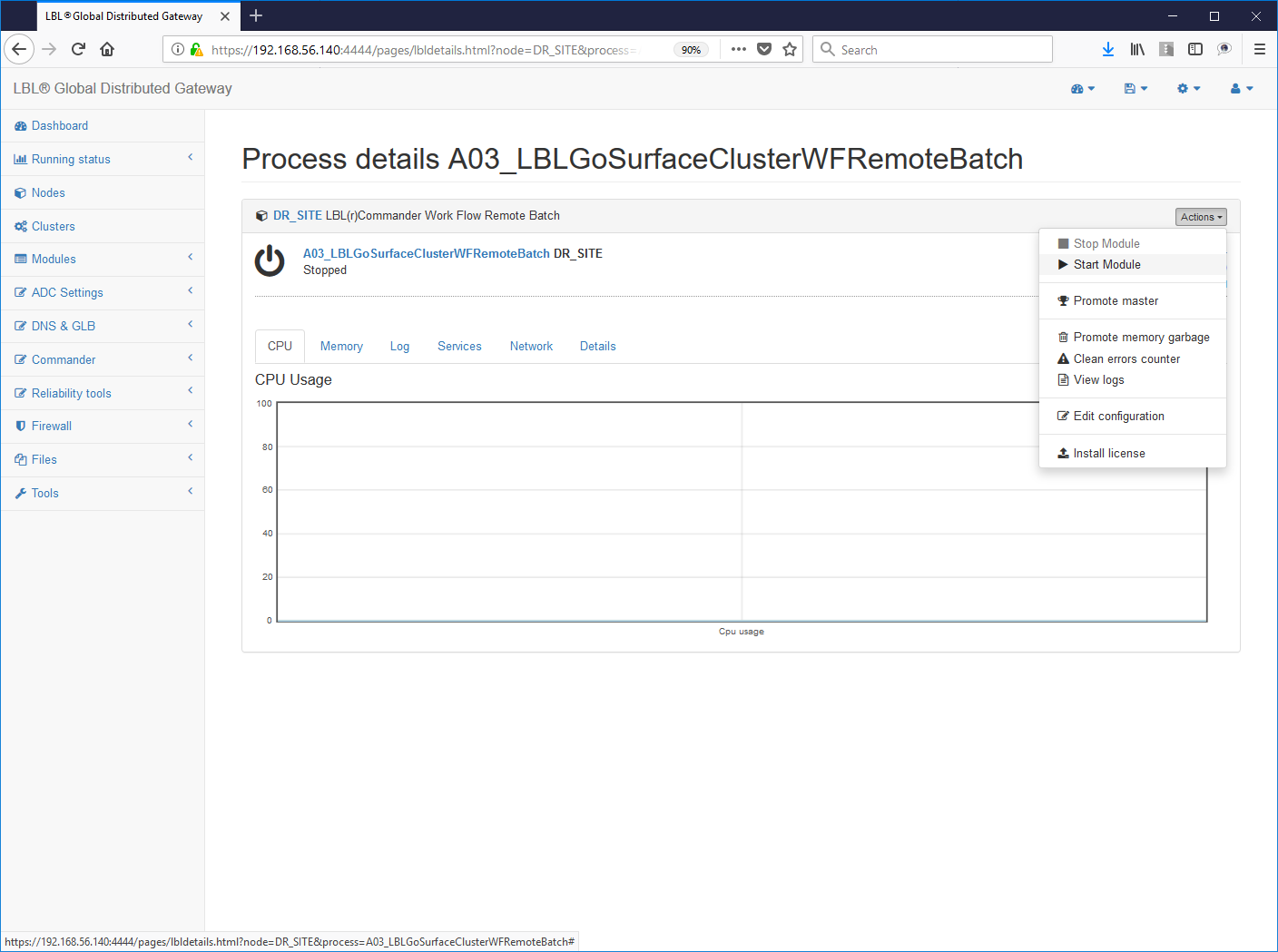
4- Scrittura e verifica del batch
Esempio vai.bat (windows systems):
echo %0 %1 %2 %3 %4 >>C:logvai.txt
AA=%1
exit 0
Esempio vai.sh (UNIX/Linux systems)
echo startBatch $@ >>/tmp/logStartBatch.txt
exit 0
5- Impostazione del profilo di lancio in
(LBL_HOME)/lib/webroot_remotebatch/webapps/RemoteBatch/
Il file di profilo ha il seguente formato:
<startBatch>
<params remoteBatchTimeOut="10000"
remoteBatchCheckRate="300"
allowURIParams="false" debug="false"/>
<legacyCommand>T:work0tmpvai.bat 11 </legacyCommand>
</startBatch>Essendo interpretato al momento del richiamo, esattamente come una pagina HTML, i cui valori potranno essere cambiati dinamicamente a caldo.
Il nome del file deve essere uguale al paragrafo principale. Nel caso sopra descritto il file si dovrà chiamare startBatch ed avere una estensione come: xml; txt, etc. (mime type text/html).
I parametri sono pochissimi e abbastanza intuitivi. Di seguito una descrizione dettagliata. Per approfondimenti sul singolo parametro si rimanda alla documentazione Reference Guide.
remoteBatchTimeOut=: valore di default "10000"
È il tempo di attesa prima di rilasciare il processo batch/eseguibile.
remoteBatchCheckRate=: valore di default "300"
È il tempo di attesa tra un tentativo e l'altro dopo aver aspettato
remoteBatchTimeOut. Dopo 3 tentativi il lancio del batch viene dichiarato fallito.
allowURIParams=:valore di default "false"
Se true permette d'inserire ulteriori parametri da URI. Il default è false per motivi di sicurezza. Se non impostato o impostato a false eventuali parametri impostati nell'URIPath verranno ignorati.
debug=: valore di default "false"
se true esegue un log warning con i valori di start del processo e del risultato ottenuto.
<legacyCommand>=: valore di default "null"
È il batch da lanciare. Per motivi di sicurezza questo valore non puo' essere vuoto.
Il lancio del batch avverrà tramite richiesta di una URL che riporti il nome del file descrittore da interpretare per il lancio del batch/eseguibile.
È possibile indicare ulteriori parametri durante il lancio del programma nella URL stessa come nell'esempio di seguito:
http://localhost:5994/RemoteBatch/startBatch.txt?parameters=2222 (opens in a new tab) 3333 4444
In questo caso il lancio del batch sarà così composto nella parte parametri:
T:work0tmpvai.bat 11 2222 3333 4444
Per verificare l'esecuzione del batch si può utilizzare un semplice browser e impostare l'indirizzo es.:
http://wileubuntudbenchbackend:5994/RemoteBatch/startBatch.xml (opens in a new tab)
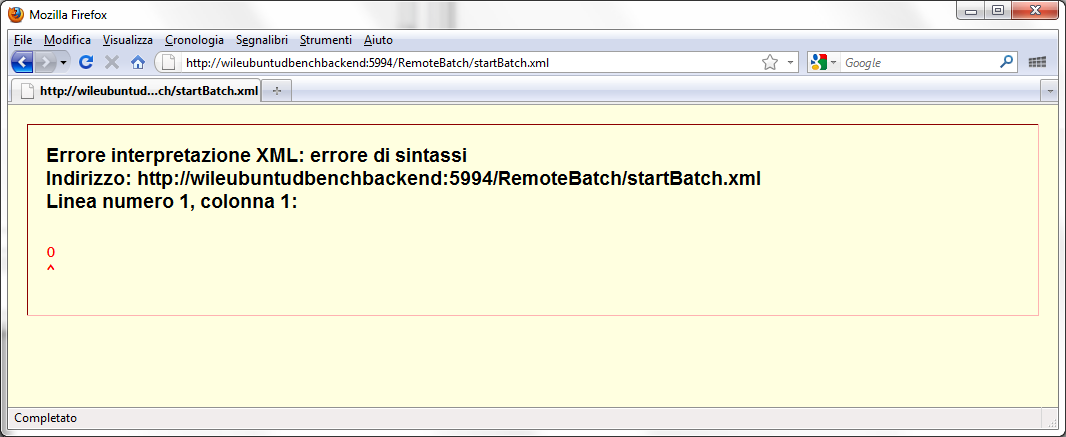
L'errore di interpretazione XML è relativo al corpo del messaggio che riporta solamente il codice di ritorno del batch/eseguibile. Per codice di ritorno uguale a 0 il Response Code HTTP sarà 200 OK. Per codici di ritorno del batch/eseguibile diversi da 0 il response Code HTTP sarà 500 Internal Server Error.
6- Impostazione lo start automatico del servizio (da "manual" a "automatic")
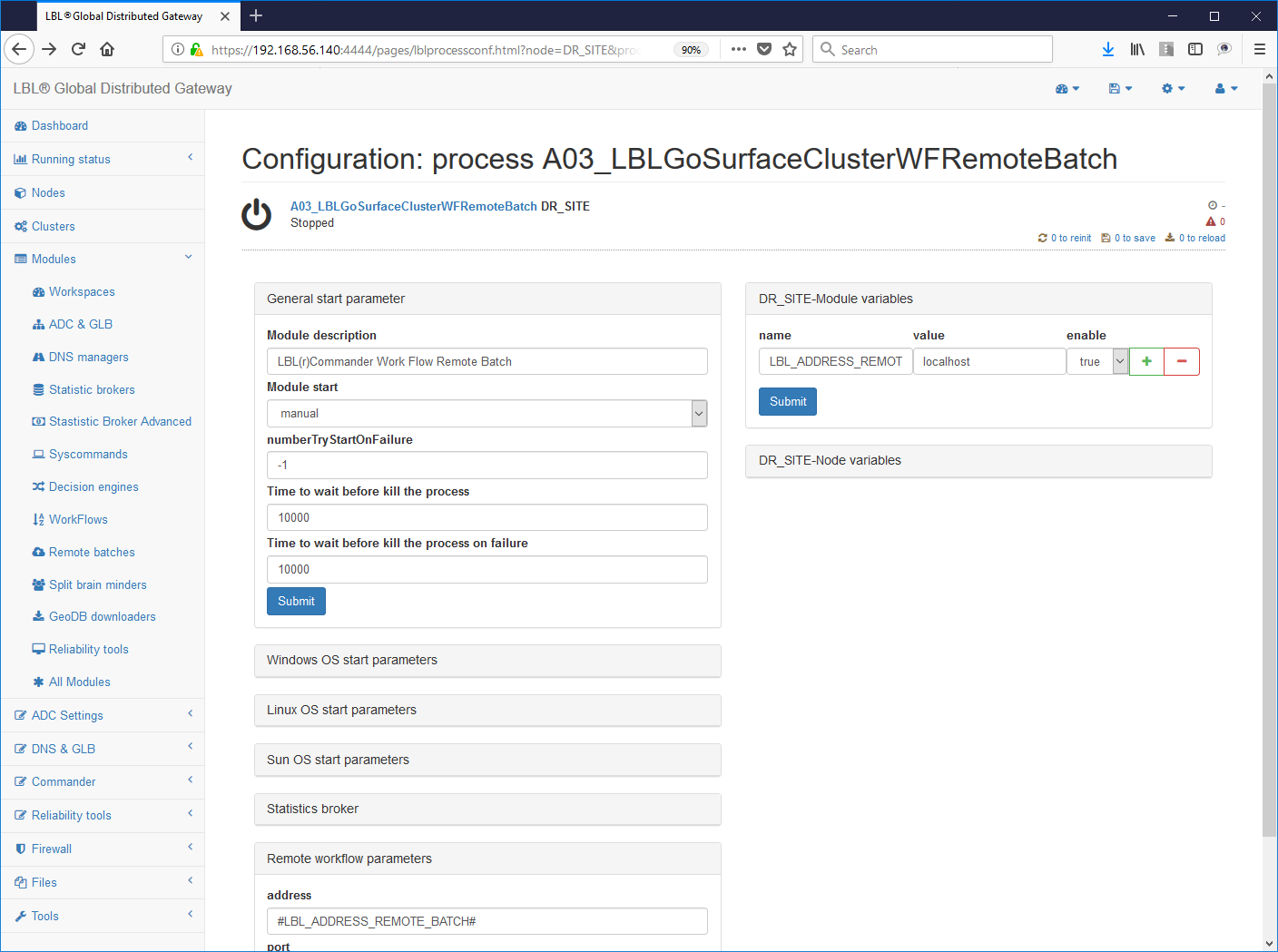
Oplon Commander Work Flow with Decision Engine
Oplon Commander Work Flow può essere accoppiato alle funzionalità Oplon Commander Decision Engine di start automatico in coincidenza con eventi di failure applicativo.
Per default Oplon Commander Decision Engine utilizza 3 Work Flow che contraddistinguono i processi di avvio, stop e switch di un ambiente operativo.
I tre momenti sono stati identificati in:
- normalPrimer
avvio normale delle applicazioni sul nodo principale
- gracefulShutdown
stop delle applicazioni in modalità controllata. Questa operazione viene innescata da Oplon Commander Decision Engine sul nodo/sito dove è stato rilevato un evento di failure prima di far prendere il controllo ad un altro nodo/sito. Questo è da considerarsi un tentativo in quanto il nodo/sito potrebbe non essere più dispinibile.
- takeControl
è l'insieme di processi che devono essere avviati in un nodo/sito secondario per prendere il controllo applicativo.
N.B.: Dalla versione 7.1 è possibile identificare un momento intermedio che intercorre tra la rilevazione dell'avaria e la decisione di eseguire uno spostamento dei servizi. Questo momento, chiamato restartWorkFlow è stato implementato per eseguire, prima dello spostamento dei servizi, un restart nel sito primario delle componenti che si ritiene essere più soggetti in una infrastruttura a criticità. Molto spesso infatti il restart controllato delle sole componenti critiche permette di avere un bassissimo impatto nell'operatività e una migliore gestione degli eventi critici senza ricorrere allo spostamento delle operazioni su altro sito/sistema con conseguente azione successiva di ripristino dell'operatività.
Questi momenti, d'ora in avanti chiamati workFlow, devono essere disponibili per poter utilizzare Oplon Commander Decision Engine. I nomi dei singoli Work Flow possono essere modificati in base alle necessità. È inoltre importante sapere che una istanza Oplon Commander Work Flow può contenere più volte queste azioni con nomi diversi in base alle applicazioni che si vogliono controllare da diversi Oplon Commander Decision Engine. In altre parole se in un nodo coesistono più ambiti applicativi in contesti diversi e se ne vuole pilotare separatamente la possibilità di fail-over è sufficiente inserire ulteriori Work Flow con nomi diversi per l'esecuzione delle azioni relative a quell'ambito applicativo.
Se si vuole procedere con l'installazione di Oplon Commander Decision Engine è quindi necessario inserire un nuovo Work Flow ai due già creati nei capitoli precedenti: takeControl.
In questo caso di minima questo nuovo Work Flow sarà esattamente uguale al normalPrimer e cioè innescherà lo start di Apache Tomcat. Nella distribuzione sono presenti alcuni esempi, simili per i sistemi operativi Unix/Linux e MS Windows. Gli esempi sono un "template" sul quale costruire le proprie implementazioni.
Si deve quindi procedere con la creazione del Work Flow "takeControl" per poi poterlo utilizzate come evento da Oplon Commander Decision Engine.
Di seguito il frammento del file surfaceclusterwf.xml con il Work Flow takeControl:
Dopo aver eseguito stop e start del server Oplon Commander Work Flow il risultato finale dovrebbe essere simile a questo esempio:
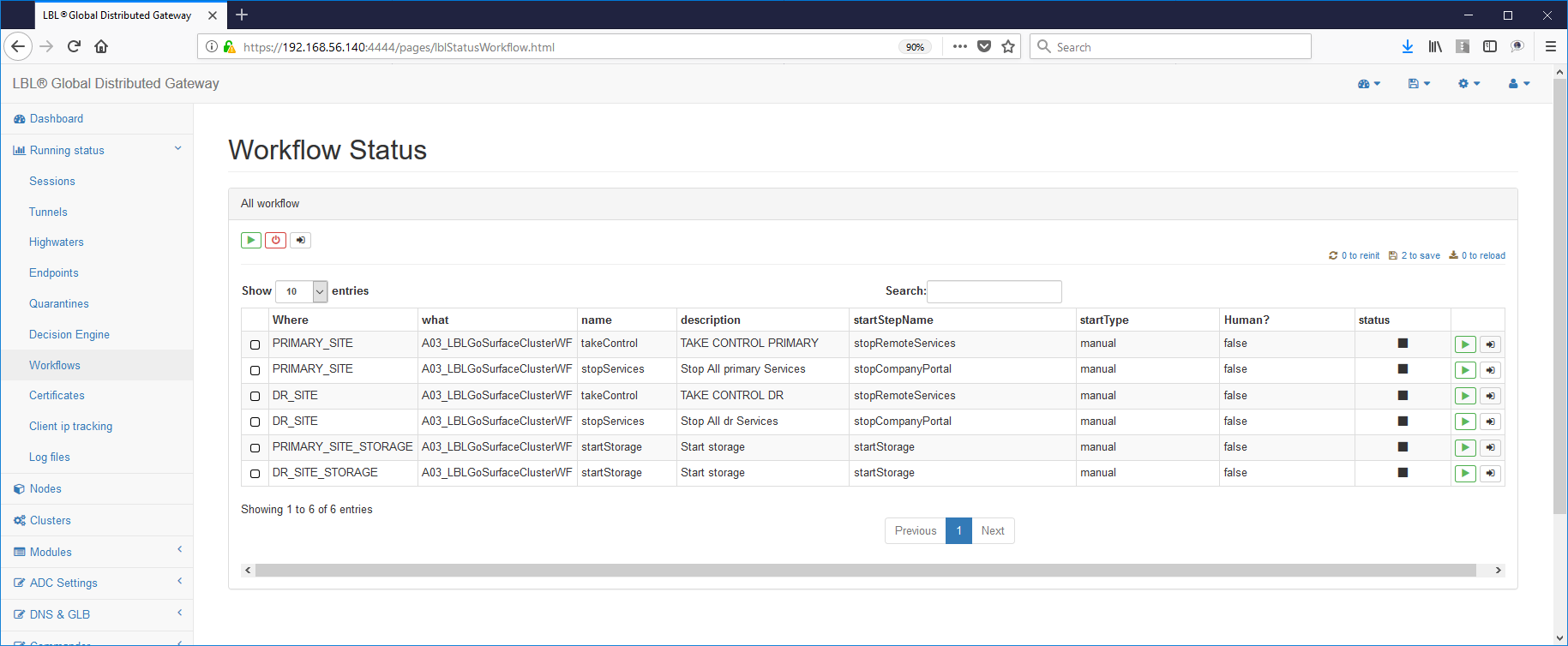
In un ambiente con due nodi speculari è sufficiente eseguire l'installazione dell'immagine Oplon Commander Work Flow eseguendo uno zip della directory (LBL_HOME) e quindi modificare solamente i riferimenti all'host.
Oplon Commander Decision Engine introduzione
Oplon Commander Decision Engine è un cluster geografico progettato per rendere automatiche le operazioni di Fail-Over in ambienti mission-critical. Questo modulo può essere considerato come il modulo "pensante" per automatizzare la gestione di procedure (Work Flow d'ora in avanti) posti su altri Server sia in ambito locale sia in ambito geografico. Oplon Commander Decision Engine lavora in cooperazione con Oplon Commander Work Flow per l'avvio di Remote Workflow Command (RWC).
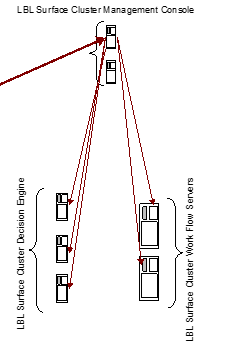
L'architettura generale può essere riassunta nel seguente schema:
La flessibilità dello strumento può essere espressa in differenti architetture. Di seguito un altro esempio di architettura possibile dove le componenti Oplon Commander Decision Engine e Work Flow sono sulla stessa macchina in ogni nodo/sito....
...oppure uno scenario di Disaster Recovery con take-over automatico...
Oplon Commander Decision Engine piano degli indirizzi/risorse
La progettazione di una infrastruttura basata su Oplon Commander Decision Engine si struttura nei seguenti aspetti fondamentali:
-
Individuazione delle risorse che identificano la rete pubblica
-
Individuazione delle risorse che identificano la rete di backend
-
Individuazione degli altri motori decisionali che concorrono al quorum
-
Individuazione delle risorse Applicative
Questi quattro elementi ci portano ad elaborare un piano degli indirizzi/risorse applicative che descrivono il contesto operativo.
La prima tabella del piano indirizzi serve ad identificare degli indirizzi/servizi che possono essere eletti a bersaglio per la determinazione della raggiungibilità della rete pubblica. Il numero minimo consigliato di bersagli è 3 (tre) l'ottimale è 5 (cinque). La logica è che se tutti i bersagli non sono raggiungibili allora la rete pubblica viene dichiarata "down". Un esempio di tabella indirizzi/servizi è di seguito sintetizzata:
Il gestore di HealthCheck è stato progettato per gestire diverse modalità di HealthCheck in base ai parametri che gli vengono forniti. Se gli viene fornito il solo parametro Address eseguirà un "ping", se gli viene fornito anche il parametro "port" eseguirà una connect e disconnect TCP/IP, se gli forniamo anche l'URIPath eseguirà una GET HTTP e controllerà il response-code che dovrà essere 200 (OK) per terminare correttamente. È possibile inoltre indicare se il servizio HTTP bersaglio è in modalità SSL con un ulteriore parametro.
Public Network Health Check
Address Port Number URIPath SSL Description
192.168.43.143 System A1 public
192.168.43.146 System A2 public
192.168.43.151 System A3 public
Una tabella simile deve essere compilata per i servizi di backend:
Backend Network Health Check
Address Port Number URIPath SSL Description
192.168.45.143 System A1 public
192.168.45.146 System A2 public
legendonebackend 54444 /HealthCheck true Commander WF A.A
legendtwobackend 54444 /HealthCheck true Commander WF B.B
In quest'ultimo esempio si possono osservare degli health check più complessi in HTTPS afferenti ai servizi Oplon Commander Work Flow che verranno utilizzati per l'automazione delle procedure.
La tabella successiva identifica gli altri motori decisionali che concorrono al Quorum. Il Quorum decisionale, cioè le condizioni che permettono ad una istanza Oplon Commander Decision Engine di poter prendere una decisione, è relativo alla possibilità di raggiungere almeno un altro Oplon Commander Decision Engine. Nel caso non fosse raggiungibile nessun altro Oplon Commander Decision Engine il nodo si dichiarerebbe isolato e quindi impossibilitato a prendere una decisione autonoma. La tabella che descrive gli altri motori decisionali (peers) avrà la seguente forma:
Oplon Commander Decision Engine peers
URL Description
https://legendoneprivate:54445/ (opens in a new tab) HalfSite A
https://legendtwoprivate:54445/ (opens in a new tab) HalfSite B
https://legendquorumprivate:54445/ (opens in a new tab) Quorum Site
Il numero di Oplon Commander Decision Engine devono essere tre (3) per la determinazione del quorum. Un numero inferiore di istanze Oplon Commander Decision Engine porterebbe a non decidere in mancanza di una delle due istanze ed un numero superiore potrebbe portare ad avere delle isole decisionali (split brain decisionale). Un'altra considerazione è relativa alla rete di Heart-Beat che non deve essere necessariamente privata ma può essere condivisa con altre applicazioni potendo arrivare a lavorare anche in ambito geografico (internet).
I file di configurazione di ogni nodo riporteranno sempre solo due (2) dei tre riferimenti della tabella non dovendo mai riportare il riferimento a se stesso.
Oplon Commander Decision Engine Web Console
Oplon Commander Decision Engine necessita di una o più console, minimo 2 in ambienti mission-critical, per poter essere gestito. È possibile utilizzare la stessa console di amministrazione dell'installazione Oplon Commander Decision Engine oppure, come nel disegno, utilizzare altre istanze Oplon Monitor dislocate in differenti server adibiti a console amministrative. Dalle stesse console possono essere gestite sia le istanze Oplon Commander Decision Engine che le istanze Oplon Commander Work Flow.
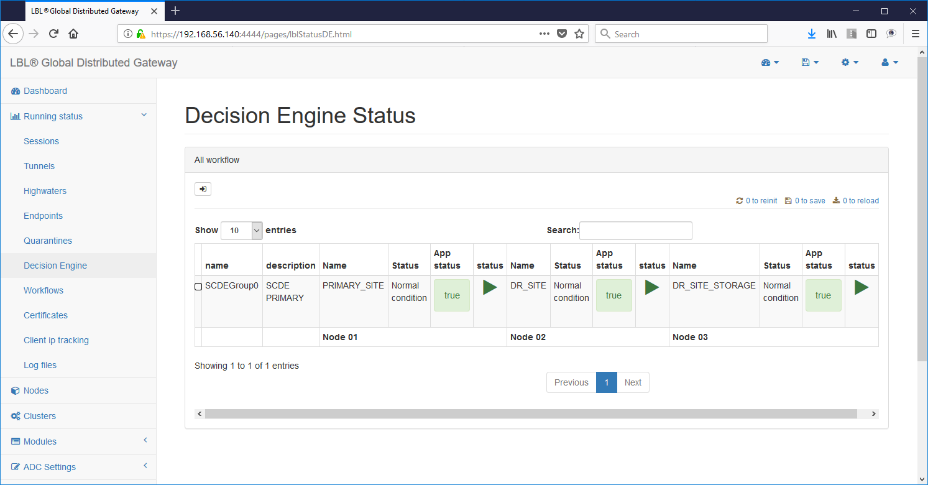
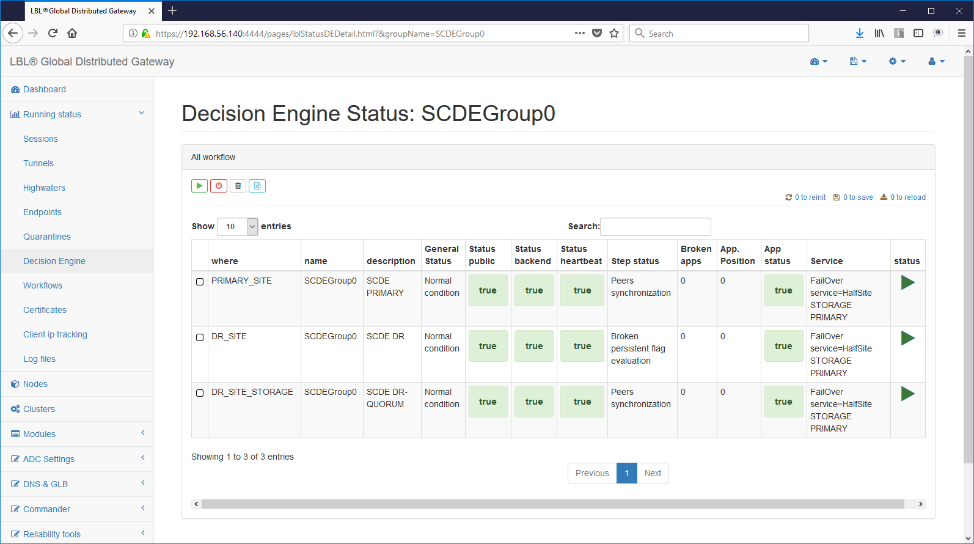
Oplon Commander Decision Engine directory e files
Oplon Commander Decision Engine utilizza solamente 3 directory ed un file di configurazione se escludiamo il file di licenza.
Le directory di default sono:
(LBL_HOME)/procsProfiles/A03_LBLGoSurfaceClusterDE/conf
(LBL_HOME)/procsProfiles/A03_LBLGoSurfaceClusterDE/surfaceClusterDEStatus
(LBL_HOME)/lib/notificationDir
-------------------------------------------------------------------------------------------------------------
(LBL_HOME)/procsProfiles/A03_LBLGoSurfaceClusterDE/confContiene la licenza ed il file di configurazione
surfaceclusterde.xml
(LBL_HOME)/procsProfiles/A03_LBLGoSurfaceClusterDE/surfaceClusterDEStatus
E' la directory di default per la persistenza dei flag di stato. In questa directory vengono creati i file che identificano le risorse dichiarate down e quindi non più utilizzabili anche dopo un successivo restart del motore decisionale o dell'intero sistema.
(LBL_HOME)/lib/notificationDir
E' la directory di notifica a Oplon ADC di indisponibilità del servizio. Viene gestita automaticamente da Oplon Commander Decision Engine creando un file con le seguenti caratteristiche:
outOfOrder.SCDEGroup_00000
| | +-------------- Numero identificatore della
sequenza di
| | Fail-Over in ordine di inserimento.
| | Questo valore deve essere inserito
| | nell'apposito parametro
| | <endp associateName="SCDEGroup_0000"...
| | in iproxy.xml
| +--------------------------------
Nome del gruppo del Cluster di controllo
| dell'applicazione
+------------------------------------------------
Identificatore di notifica Out Of OrderOplon Commander Decision Engine surfaceclusterde.xml
Una volta ultimata la raccolta dei dati di ambiente si può iniziare ad impostare il file di configurazione del Cluster.
L'impostazione dei file di configurazione deve essere effettuata su tutti e tre i nodi dove è stata installata l'immagine Oplon Commander Decision Engine atraverso una delle sue distribuzioni.
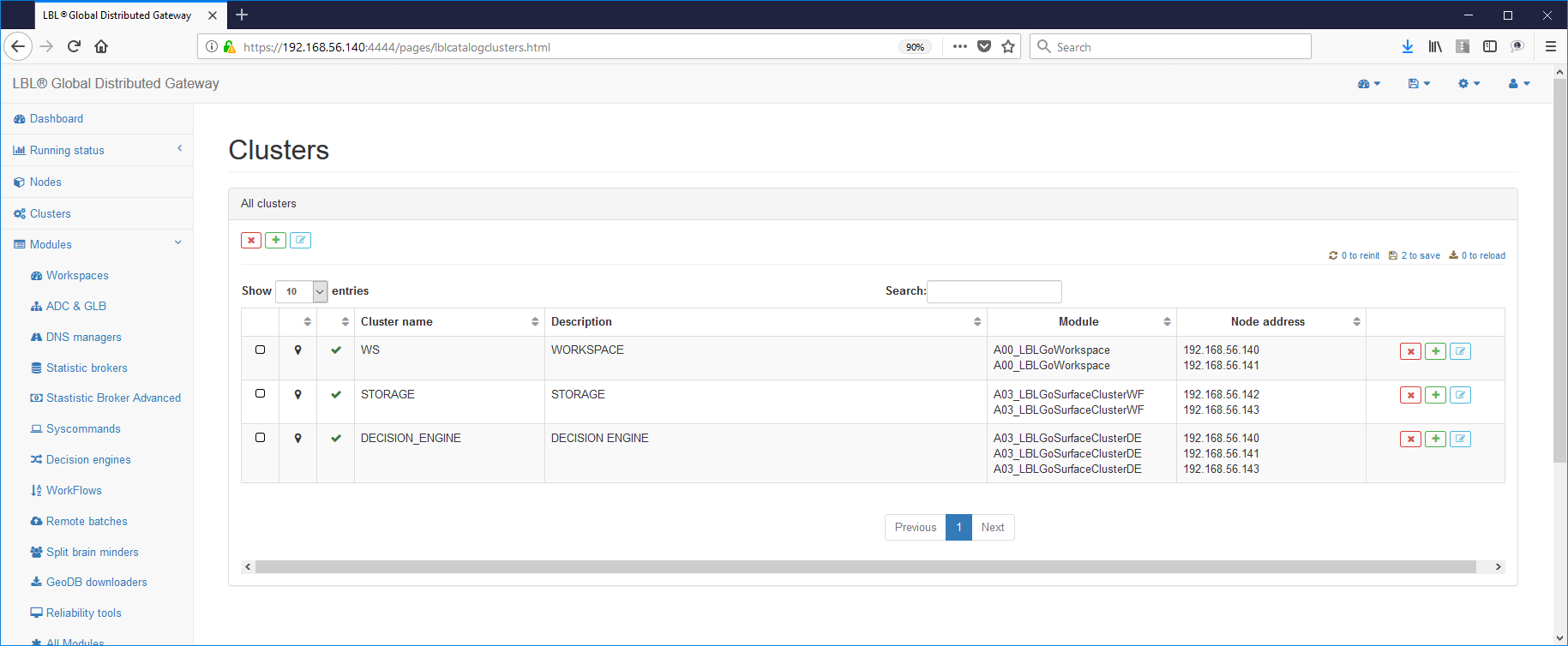 La prima operazione da effettuare è quindi
porre in cluster tutti i moduli decision engine e agire sulle variabili
per differenziare i comportamenti:
La prima operazione da effettuare è quindi
porre in cluster tutti i moduli decision engine e agire sulle variabili
per differenziare i comportamenti:
Il file contiene due paragrafi principali, uno per la gestione del Server Oplon Commander Decision Engine mentre gli altri sono funzionali alla gestione dei Cluster applicativi.
Nella pagina di seguito sono riportati i paragrafi evidenziati con una
cornice blue per i parametri relativi alla gestione del Server Oplon
Commander Decision Engine ed in rosso i paragrafi relativi alla
gestione di un singolo Cluster Applicativo. È possibile nello stesso
Oplon Commander Decision Engine gestire più Cluster semplicemente
duplicando il paragrafo <decisionEngine> e impostando un diverso
groupName con il nome di questo nuovo cluster.
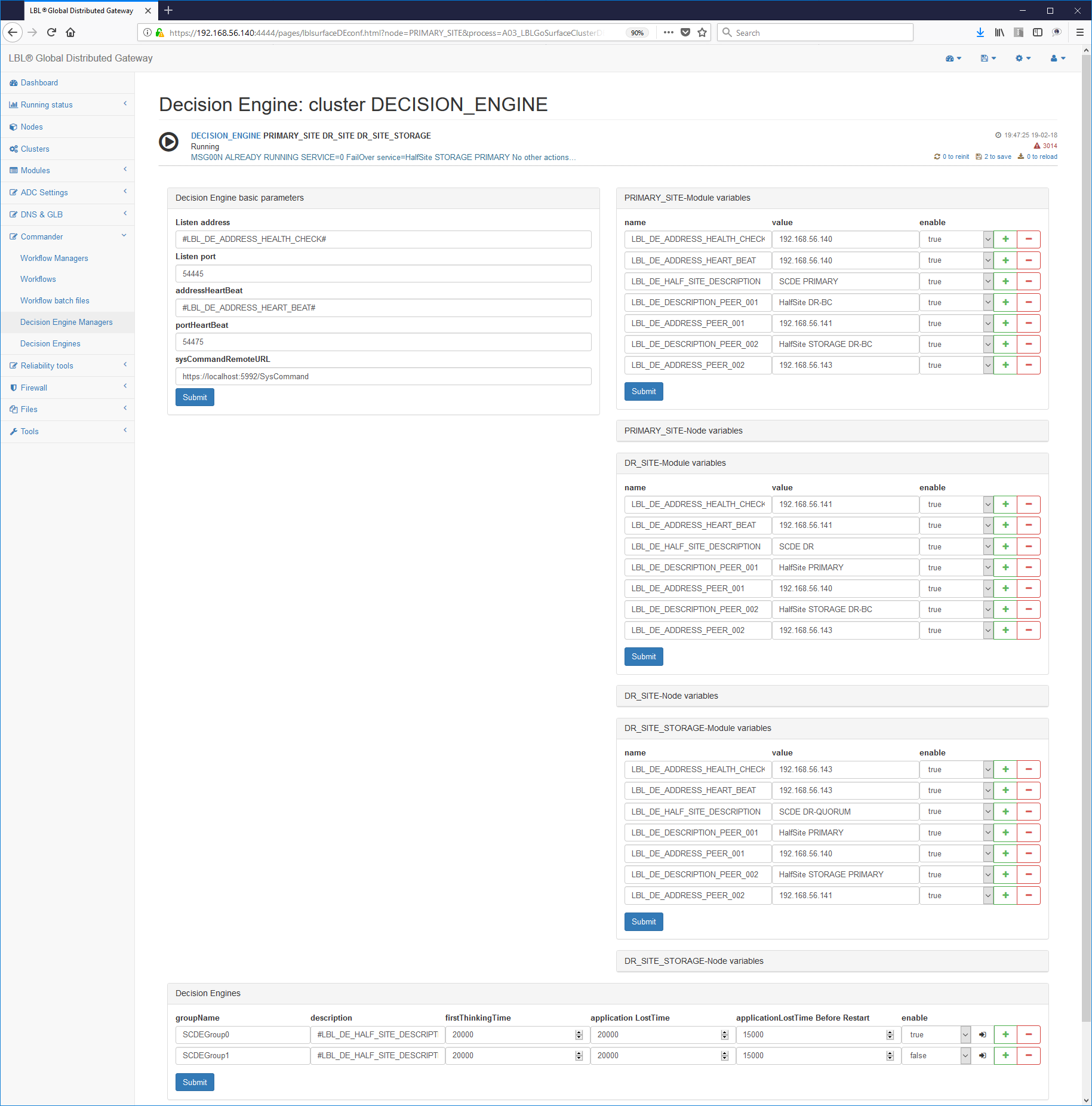
L'impostazione del primo paragrafo prevede l'impostazione degli indirizzi per la gestione del Server e per il controllo remoto.
Di seguito quanto proposto nella distribuzione per il paragrafo
<params>:
frequency è la frequenza di verifica dello stato del cluster.
address è l'indirizzo pubblico su cui effettuare le operazioni di controllo mentre addressHeartBeat è un secondo indirizzo, normalmente afferente alla rete di HeartBeat, per le operazioni tra nodi peers. I due indirizzi possono coincidere ed in questo caso è necessario modificare la porta per la convivenza.
Una volta impostati i parametri generali si passa alla configurazione del cluster applicativo. Il primo paragrafo da impostare è sicuramente il paragrafo relativo all'identificazione del Cluster.
Ogni paragrafo <decisionEngine> delimita un Cluster Applicativo.
Possono esserci più <decisionEngine> e quindi più gestioni di cluster
applicativi differenti contemporaneamente.
enable=:default="false" UM=boolean
Abilita o disabilita l'interpretazione di questo paragrafo nell'istanza.
groupName=: valore di default="SCDEGroup"
E' il nome del gruppo di Decision Engine. E' importantissimo in quanto i motori di decisione contenuti su un'istanza si distinguono da questo nome.
description=: valore di default="description: groupName"
E' la descrizione di questo decision engine. Deve essere sintetica ma esaustiva.
frequency=: valore di default="<params frequency>"
UM=Millisecondi
E' la frequenza di verifica cambiamenti di stato. Se non specificata
viene assunta la frequenza del paragrafo <params>
firstThinkingTime=: valore di default="45000" UM=Millisecondi
E' il tempo di attesa di inizializzazione e prime verifiche. Superato questo tempo di attesa il motore decisionale evidenzierà un messaggio. Il motore decionale non procede comunque anche oltrepassato questo tempo iniziale e attende la totale inizializzazione degli stati.
applicationLostTime=: valore di default="30000" UM=Millisecondi
E' il tempo di attesa da quando l'applicazione in verifica è stata dichiarata in stato di down. Questo è un valore molto importante perché superato questo periodo di tempo e l'applicazione risultasse ancora non raggiungibile e verificato il quorum di switch si innescherà la procedura di recovery. I 30" sono il minimo per evitare falsi positivi.
Il paragrafo <decisionEnginePeers> delimita le informazioni relative
agli altri due Decision Engine che concorrono alle decisioni.
I parametri sono molto semplici e necessitano solo delle informazioni relative alla connessione e autenticazione.
enable=:default="false" UM=boolean
Abilita o disabilita l'interpretazione di questo paragrafo nell'istanza.
URL=:default="" UM=URL W3c
E' l'URL di connessione al servizio paritetico attraverso la rete di HeartBeat.
description=:default="description peer: URL"
descrizione sintica ma esaustiva del servzio.
Il paragrafo relativo ai servizi applicativi è il cuore del Cluster in quanto identifica i servizi applicativi con le relative modalità di HealthCheck Questo paragrafo include anche i Work Flow che devono essere innescati per le azioni di Fail-Over.
I parametri nel paragrafo <healthCheckServicesPolicy> sono relativi
alla gestione. I parametri sono intuitivi e riprendendo parte del
documento di reference guide e si possono riassumere in:
description=:default=""
Descrizione generale del servizio posto in alta affidabilità.
waitTimeAfterNormalPrimer=:default="180000" UM=Millisecondi
E' il tempo di attesa dopo aver avviato il primo servizio disponibile (normal startup). Superato questo tempo il decision engine comincerà a verificare se il servizio è arrivato allo stato di attività. In caso contrario verranno avviate le procedure di recovery. Se l'applicazione va in up prima di questo valore il Decision Engine si mette immediatamente in verifica.
waitTimeAfterFlagBroken=:default="60000" UM=Millisecondi
E' il tempo di attesa dopo l'impostazione del flag persistente per la propagazione agli altri peer.
waitTimeBeforeTakeControl=:default="180000" UM=Millisecondi
E' il tempo di attesa prima di effettuare il take control serve a lasciare il tempo per un eventuale graceful shutdown del servizio precedentemente attivo se la risorsa è ancora raggiungibile.
waitTimeAfterTakeControl=:default="900000" (15') UM=Millisecondi
È il tempo di attesa dopo il take control serve ad aspettare la conclusione del completo take control prima di ritornare a verificare lo stato di attività e quindi decidere se è andato a buon fine oppure ritentare con altra risorsa se disponibile. Se l'applicazione va in up prima di questo valore il Decision Engine si mette immediatamente in verifica. Questo tempo è variabile in dipendenza del tipo di recovery e dalla quantità di dati se presente un database.
applicationLostTime=:default="<decisionEngine applicationLostTime>" UM=Mill
È il tempo di attesa dopo il take control serve ad aspettare la conclusione del completo take control prima di ritornare a verificare lo stato di attività e quindi decidere se e' andato a buon fine oppure ritentare con altra risorsa se disponibile. Se l'applicazione va in up prima di questo valore il Decision Engine si mette immediatamente in verifica. Questo tempo è variabile in dipendenza del tipo di recovery e dalla quantità di dati se presente un database.
**normalPrimerWorkFlow=**:*default=***"normalPrimer"** UM=Work Flow name
E' il nome del Work Flow che sarà innescato se viene determinato lo startup iniziale del servzio..
gracefulShutdownWorkFlow=:default=**"gracefulShutdown"**UM=Work Flow name
E' il nome del Work Flow che sarà innescato se vine determinato il down del servizio e immediatamente prima di effettuare l'azione di recovery.
takeControlWorkFlow=:default=**"takeControl"**UM=Work Flow name
E' il nome del Work Flow che sarà innescato dopo l'avvio del gracefulShutdownWorkFlow per avviare l'azione di recovery.
<failOverService> identifica in sequenza di inserimento i servizi nei
loro server. L'ordine di inserimento identifica anche la priorità dei
servizi. I parametri proposti da template di distribuzione sono
pochissimi ma in realtà si possono impostare moltissimi parametri tipici
per questa applicazione in quel particolare nodo/sito. Si rimanda al
documento Reference Guide per una completa trattazione.
enable=:default="false" UM=boolean
Abilita o disabilita l'interpretazione di questo paragrafo nell'istanza.
description=:default=""
Descrizione puntuale del servizio posto in alta affidabilità. Si consiglia, nei limiti del possibile, di utilizzare la nomenclatura Oplon Surface Cluster es.: HalfSite A.A piuttosto che HalfSite B.B con la breve ma esaustiva descrizione del servizio.
surfaceClusterWorkFlowURL=:default="https://"
E' l'URL dell'istanza Oplon Commander Work Flow afferente a questo servizio applicativo.
I parametri relativi al paragrafo <healthCheck> indicano le modalità
di HealthCheck delle applicazioni. Possono esserci più paragrafi
<healthChekh> ed il fallimento di uno solo di questi HealthCheck
determina lo stato di verifica di raggiungimento del quorum decisionale
per lo switch. Ovviamente se alla verifica successiva ed entro i limiti
del parametro applicationLostTime l'HealthCheck dovesse tornare ad
essere positivo tutti i Decision Engine ritorneranno in normale verifica
facendo rientrare lo stato di criticità.
enable=:default="false"
Se true questo paragrafo namespace è attivo. Se false il paragrafo non viene preso in considerazione.
description=:default=""
Descrizione sintetica dell'HealthCheck.
address=: valore di default=""
E' l'indirizzo su cui viene effettuato l'health check..
port=: valore di default="0"
E' la porta su cui risponde il servizio di health check. Se minore o uguale a 0 verrà eseguito un check ICMP
SSL=: valore di default="false"
Se impostato a true esegue l'health check del servizio attraverso una connessione SSL (HTTPS).
uriPath=: valore di default=""
E' l'URIPath su cui risponde il servizio di health check. Se non presente verrà eseguito un health check TCP con connessione.
Oplon Commander Decision Engine Start/Stop/Manage Status
Oplon Commander Decision Engine è un motore decisionale pensato per avere pochissima manutenzione e soprattutto un bassissimo impatto operativo. Il management delle operazioni è completamente affidato alle interfacce Web utilizzabili attraverso una qualsiasi istanza Oplon Monitor opportunamente istruita. Dopo aver impostato i parametri di contesto allo start Oplon Commander Decision Engine esegue l'inizializzazione degli stati per verificare le condizioni di stato applicativo e di ambiente.
E' possibile verificare questi stati attraverso l'interfaccia Web:
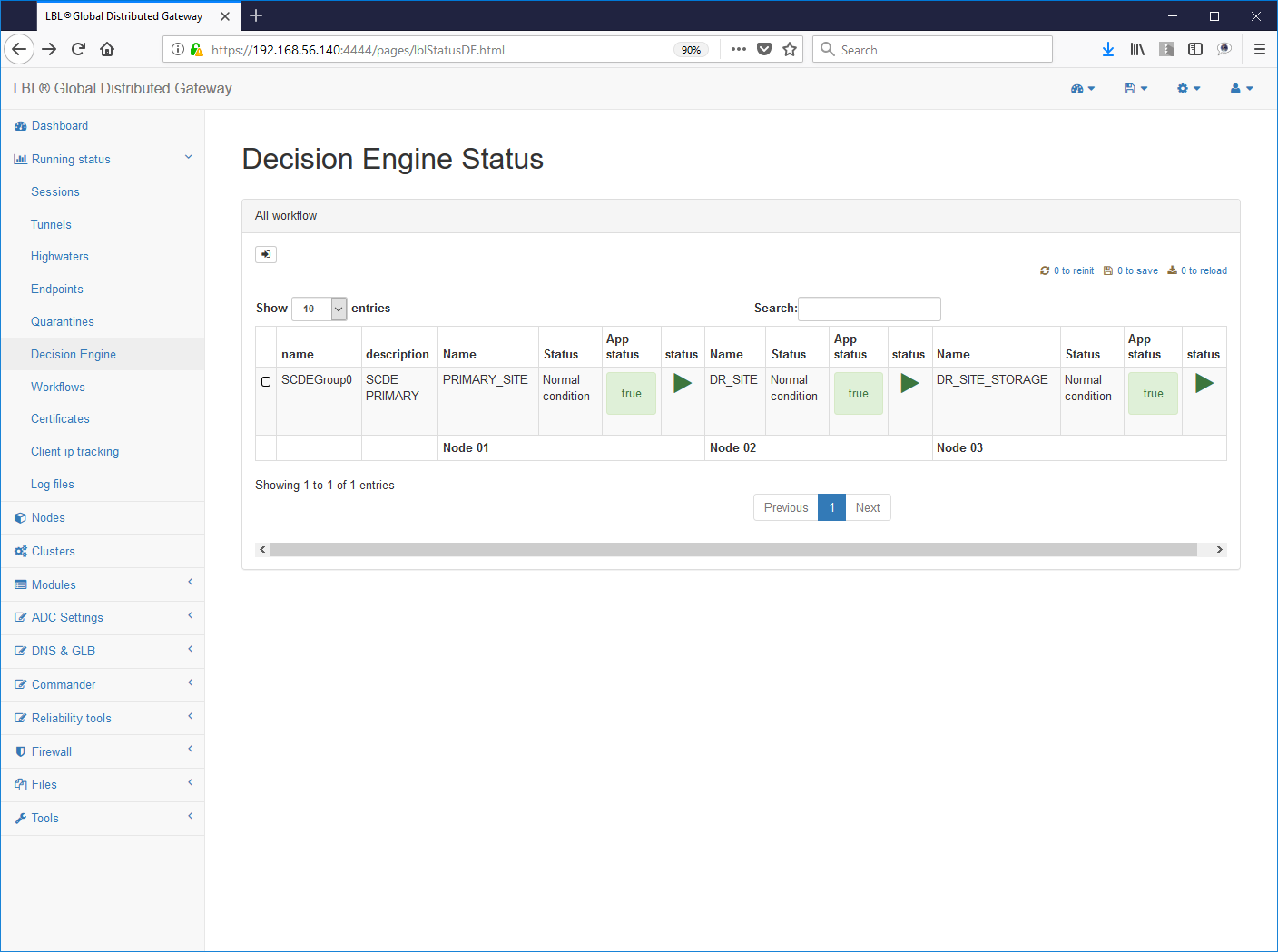
In questa fase vengono avviati in parallelo i controlli applicativi e di ambiente. Una volta ultimati i controlli lo stato del nodo Oplon Commander Decision Engine cambia dando l'esatta immagine dello stato dell'ambiente su cui è stato impostato il controllo applicativo.
Appena terminata l'inizializzazione se tutto l'ambiente è stato impostato nella maniera corretta e non ci sono anomalie riscontrate ad un successivo refresh sarà visualizzata la seguente situazione:
Nessun quadrante di stato deve essere colorato di rosso o giallo. La colorazione rossa indica una anomalia importante mente una colorazione gialla indica una anomalia che non compromette la facoltà decisionale.
Per verificare se le impostazioni effettuate sono corrette è sufficiente seguire gli HyperLink come in questo caso: groupName->SCDEGroup
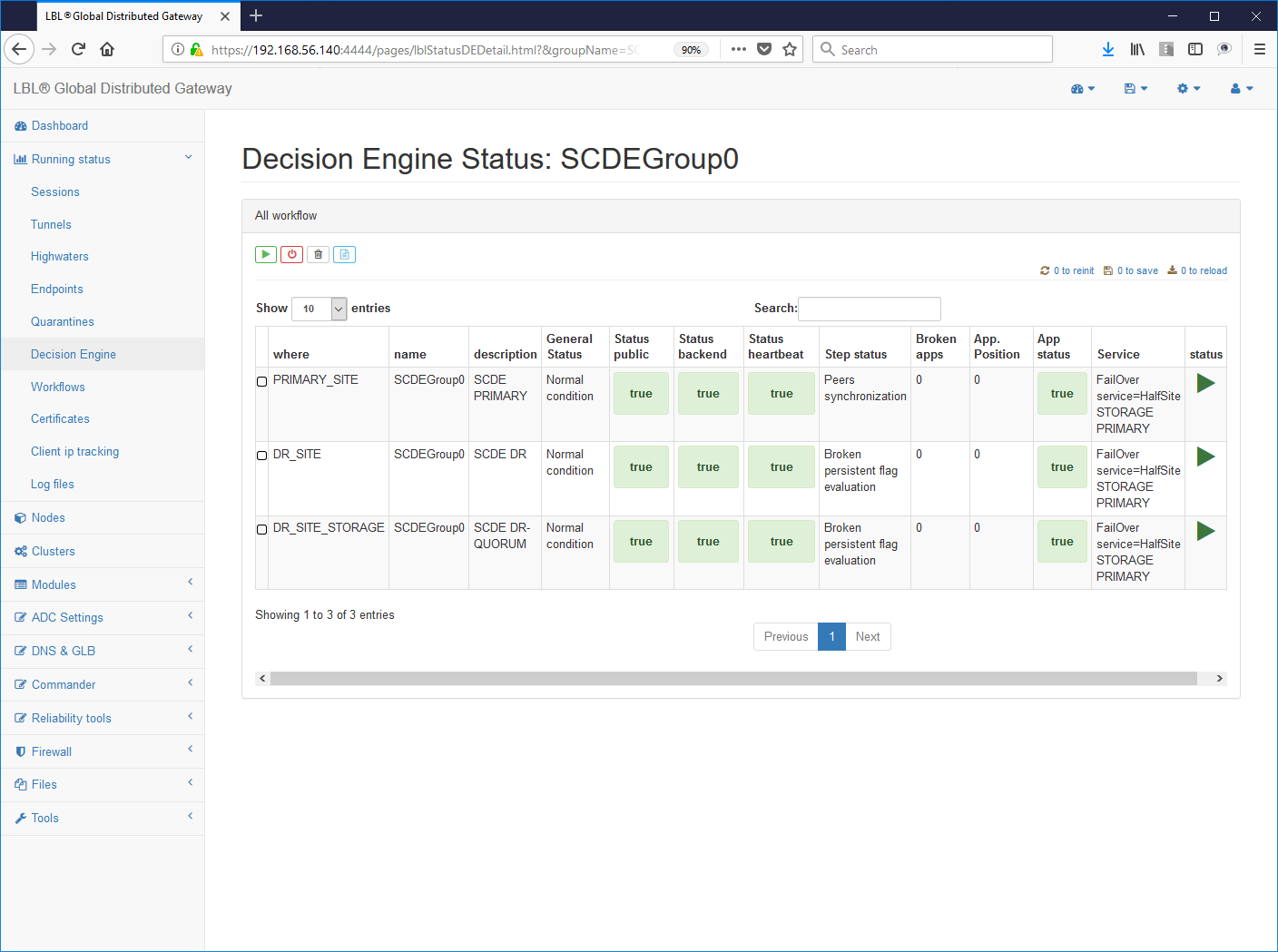
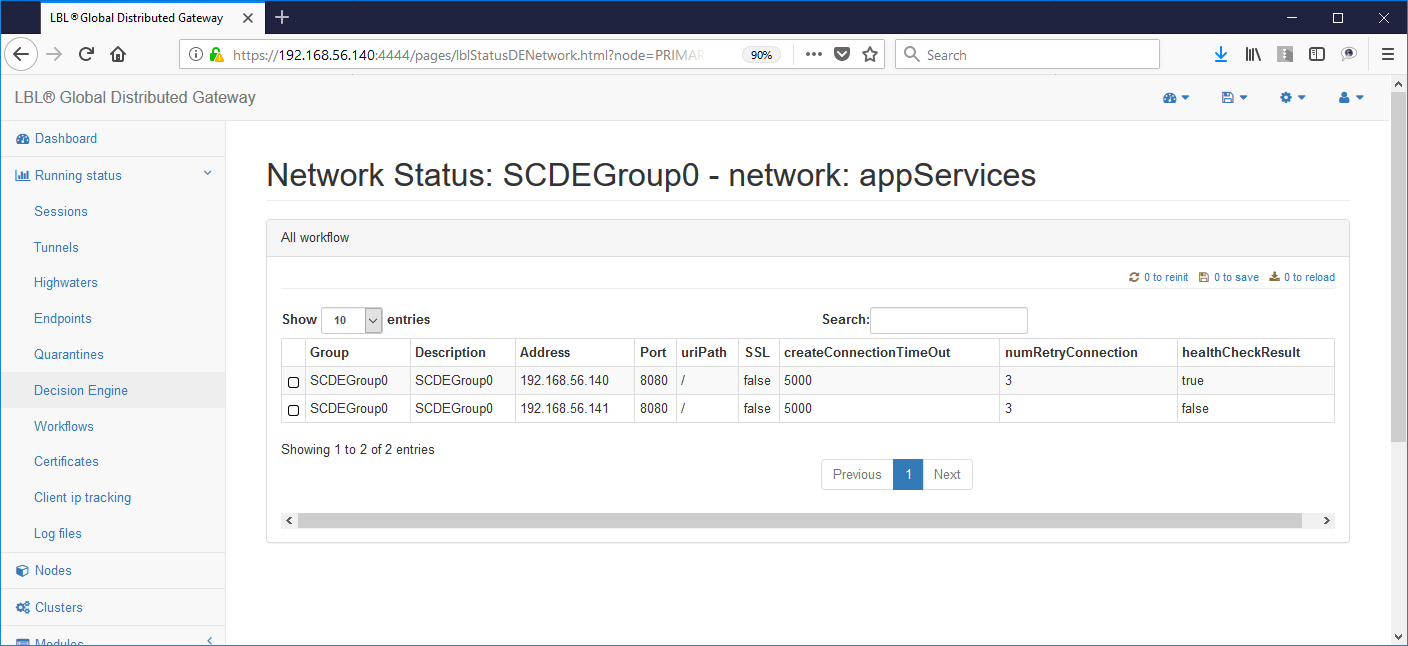
Questa visualizzazione ci evidenzia su quale nodo è attiva l'applicazione. In questo caso il sito applicativo primario (A.A) è up and running mentre correttamente il sito secondario non ha l'applicazione attiva. Questa ovviamente è la condizione normale, se fosse attiva anche l'applicazione sul sito secondario (B.B) saremmo in una situazione di Split Brain applicativo. Volendo simulare questa condizione proviamo ora a eseguire lo start dell'istanza Apache Tomcat anche sul sito secondario...
Su Oplon Commander Work Flow del sito secondario eseguiamo lo start manuale di Apache Tomcat...
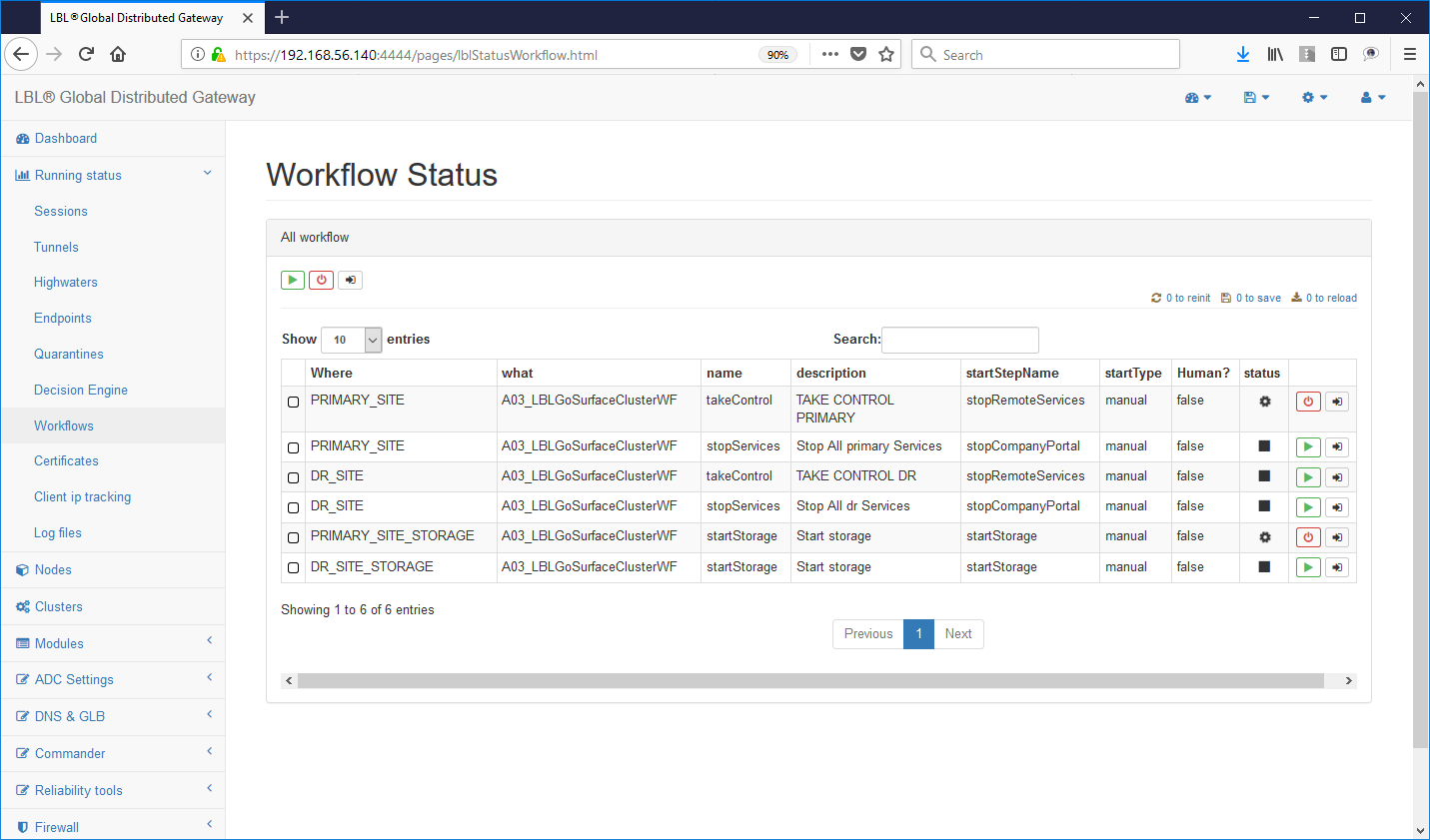
Immediatamente tutte le istanze Oplon Commander Decision Engine rilevano l'anomalia segnalandola sui log attraverso e-mail e post HTTP. Inoltre in questa situazione Oplon Commander Decision Engine si pone in stato di inconsistenza e quindi di impossibilità a prendere una decisione.
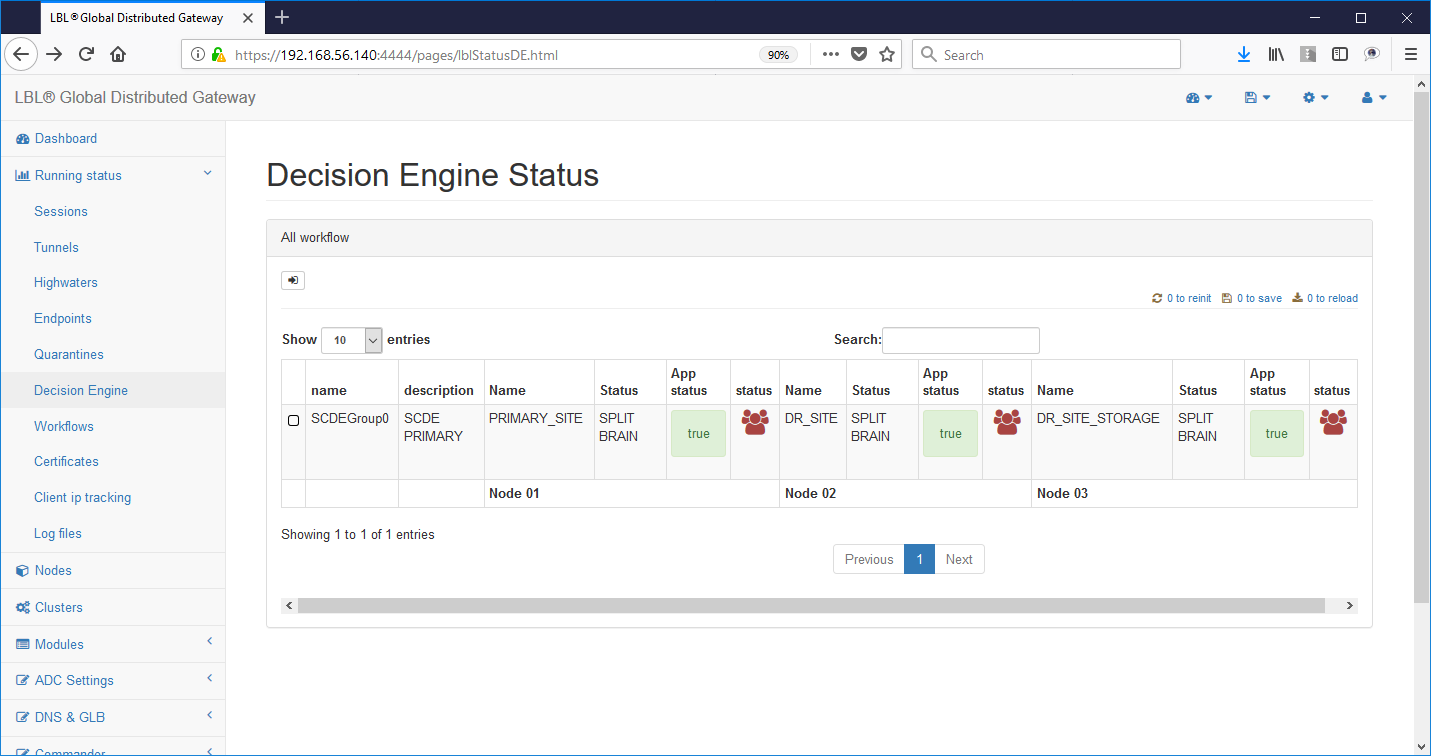
Oplon Commander Decision Engine è stato progettato per lavorare in contesti geografici e mantiene un comportamento decisionale conservativo identificando le situazioni in cui non gli è possibile prendere delle decisioni autonome per insufficienza di informazioni o identificando situazioni di inconsistenza.
Sempre attraverso l'interfaccia Web operiamo su Oplon Commander Work Flow per ripristinare la situazione ed eliminare la segnalazione di stato SPLIT BRAIN:
Eseguiamo il Work Flow "gracefulShutdown" nel sito secondario...
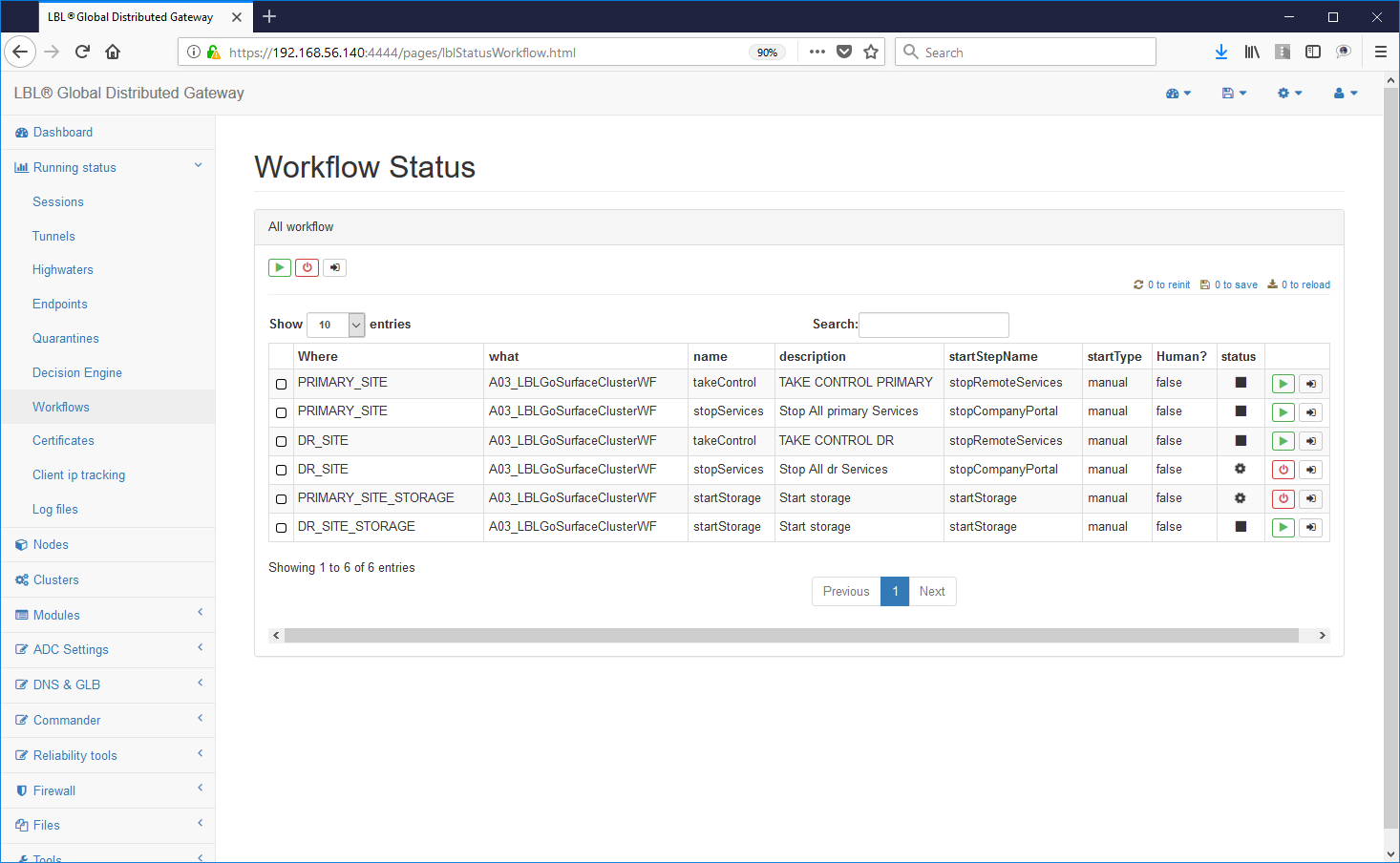
...le istanze Oplon Commander Decision Engine rilevano l'avvenuto ripristino di una situazione coerente...
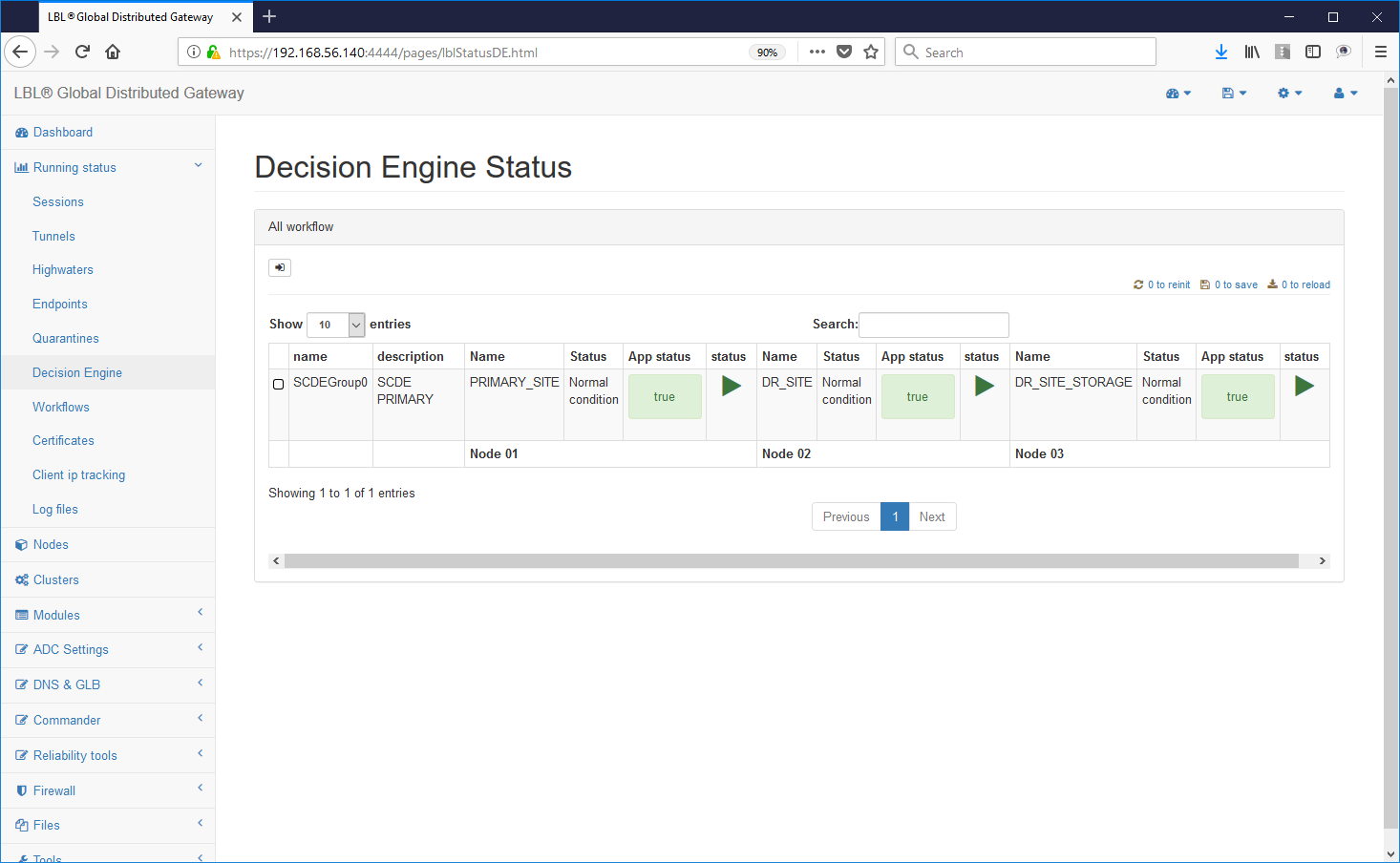
Proviamo ora a generare un problema eseguendo uno stop forzato dell'istanza Apache Tomcat sul sito primario....
Immediatamente le istanze Oplon Commander Decision Engine rileveranno il problema...
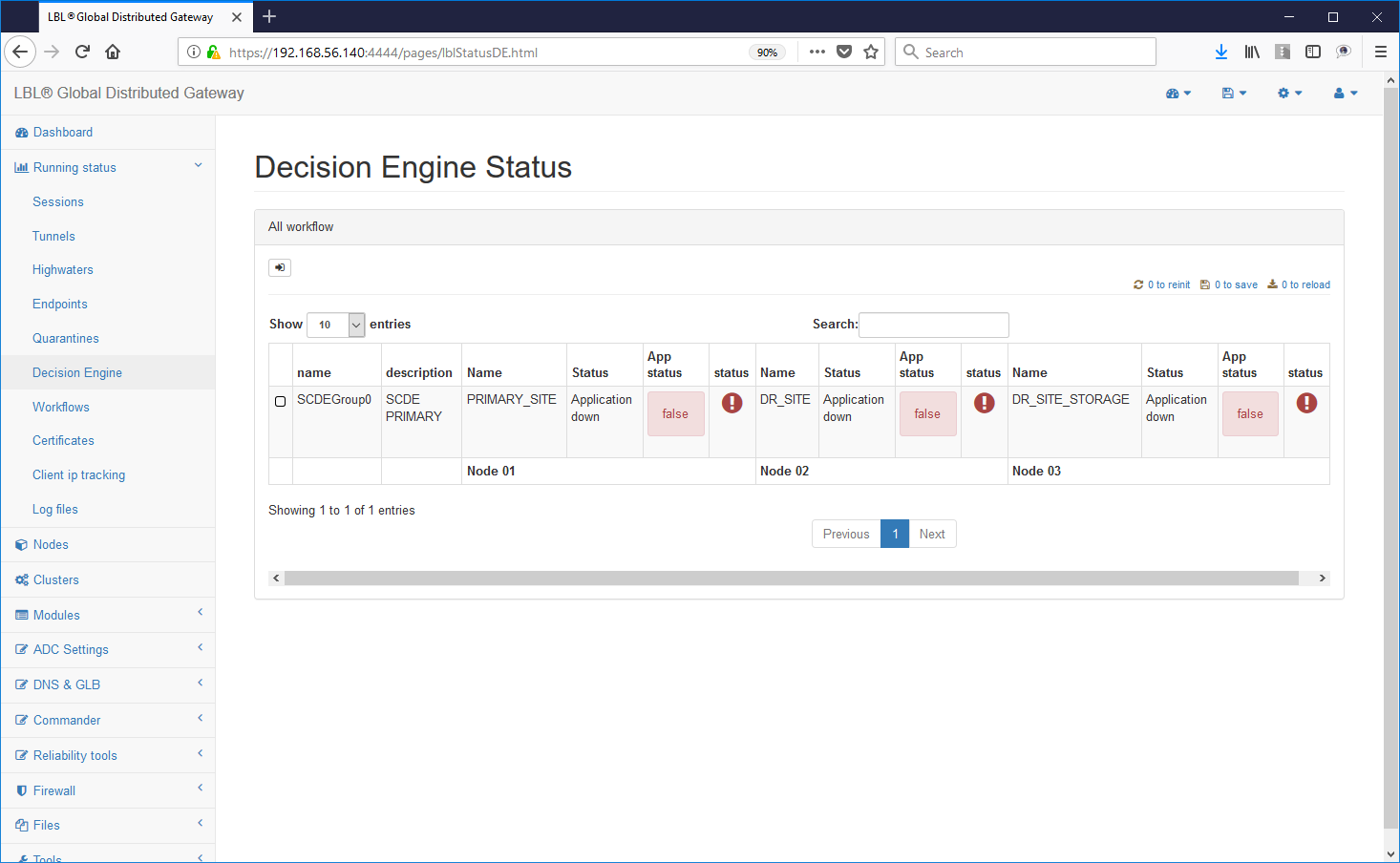
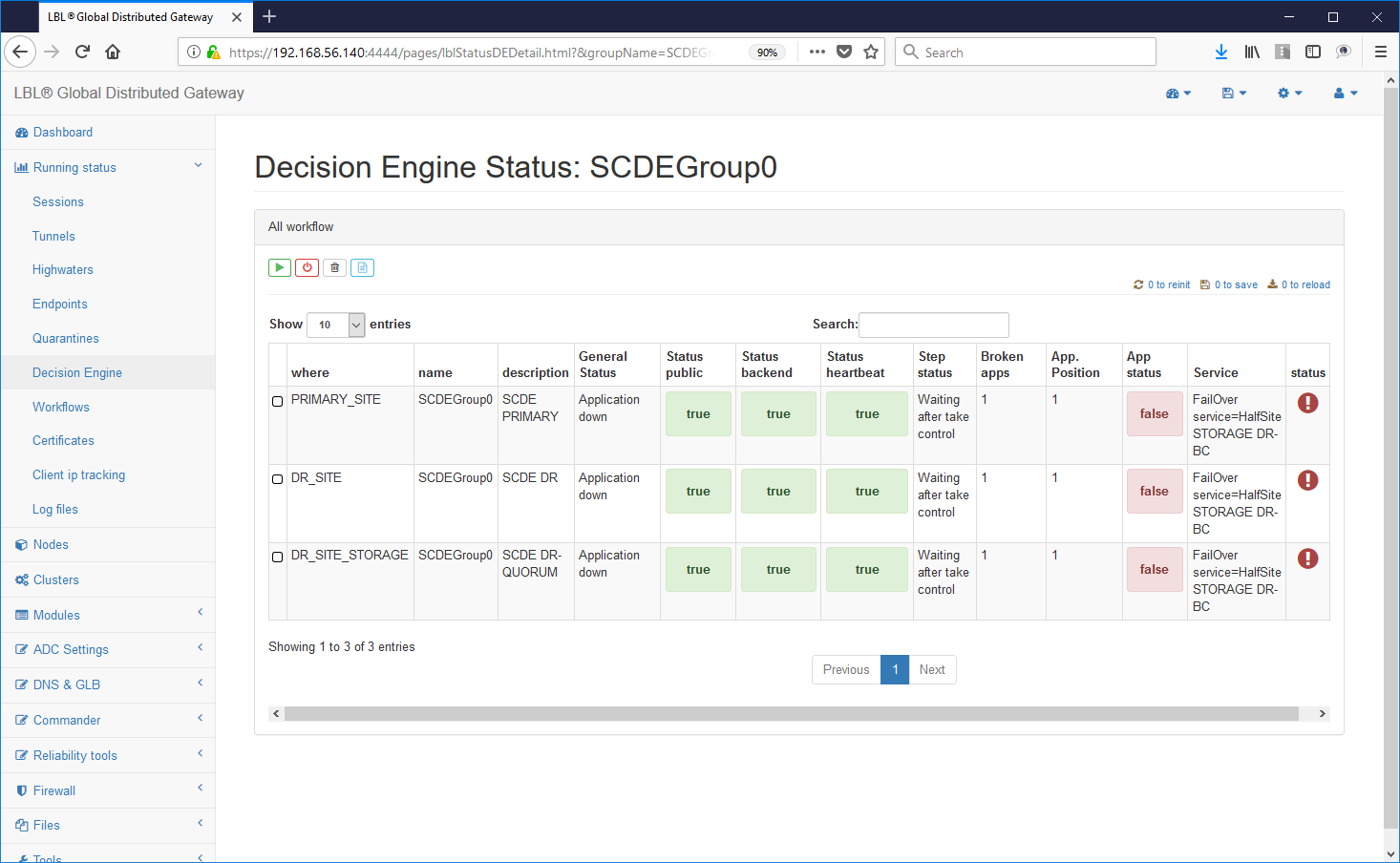 regolati da lease-time completamente
impostabili in relazione all'applicazione e all'ambiente operativo le
istanze Oplon Commander Decision Engine verificano se la condizione
anomala è una condizione di effettivo evento di errore oppure è stata
causata da un evento sporadico e una volta verificata la persistenza
dell'evento di errore e verificata la condizione per poter prendere
delle decisioni "autonome" le istanze Oplon Commander Decision Engine
pongono definitivamente in stato di "Failure" il nodo/sito fonte del
problema...
regolati da lease-time completamente
impostabili in relazione all'applicazione e all'ambiente operativo le
istanze Oplon Commander Decision Engine verificano se la condizione
anomala è una condizione di effettivo evento di errore oppure è stata
causata da un evento sporadico e una volta verificata la persistenza
dell'evento di errore e verificata la condizione per poter prendere
delle decisioni "autonome" le istanze Oplon Commander Decision Engine
pongono definitivamente in stato di "Failure" il nodo/sito fonte del
problema...
tutte le decisioni prese dalle istanze Oplon Commander Decision Engine sono parte di un sofisticato motore decisionale con rilevazione parallela degli eventi provenienti dall'ambiente circostante ed in ogni momento le azioni si susseguiranno in maniera autonoma ma coerente in tutti i nodi decisionali...
...una volta che i nodi decisionali superstiti raggiungono la coerenza di informazioni relative alla dichiarazione esplicita di "down" dell'applicazione in autonomia ed in concorrenza cercano di ripristinare una situazione applicativa di operatività...
...le operazioni che seguono la dichiarazione di "down" del sito primario sono un ultimo tentativo di eseguire comunque sul sito primario uno shutdown controllato per cercare se possibile di minimizzare i problemi dovuti a un take-over forzato.
...dopo aver eseguito lo shutdown controllato delle applicazioni nel sito primario Oplon Commander Decision Engine attende per un tempo ragionevole che il nodo/sito primario abbiano potuto effettuare le loro operazioni di spegnimento controllato...
....ed in ogni caso superato il tempo limite viene forzato il take-over dei servizi sul nodo/sito secondario... attesa dello startup dell'applicazione sul sito secondario.
ritorno alla normalità operativa e ovviamente segnalando lo stato di errore del sito secondario...
Oplon Commander Decision Engine ripristino guidato applicativo
Oplon Commander Decision Engine è un motore decisionale pensato per avere pochissima manutenzione e soprattutto un bassissimo impatto operativo. Il management delle operazioni è completamente affidato alle interfacce Web utilizzabili attraverso una qualsiasi istanza Oplon Monitor opportunamente istruito. Ad un evento di failure applicativo Oplon Commander Decision Engine utilizza degli indicatori persistenti e distribuiti sui diversi nodi come traccia dell'evento.
Per ripristinare la situazione alla normalità operativa con il sito principale attivo ed il sito secondario in replica è sufficiente operare attraverso le interfacce Web di Oplon Commander Decision Engine e Oplon Commander Work Flow.
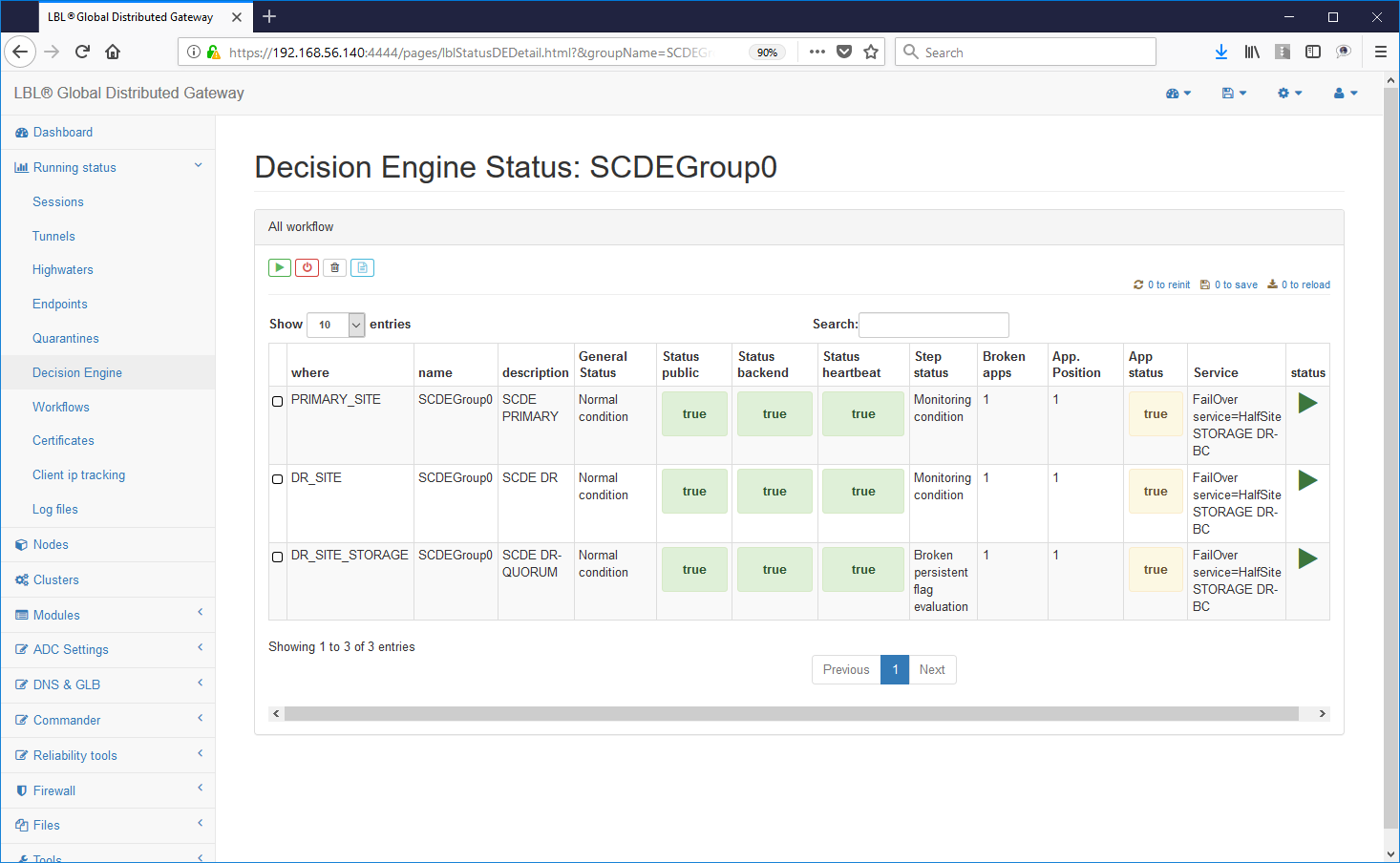
Volendo ad esempio ripristinare l'operatività sul sito principale dell'istanza Apache Tomcat è sufficiente eseguire lo stop logico dei motori decisionali per quel gruppo di applicazioni...
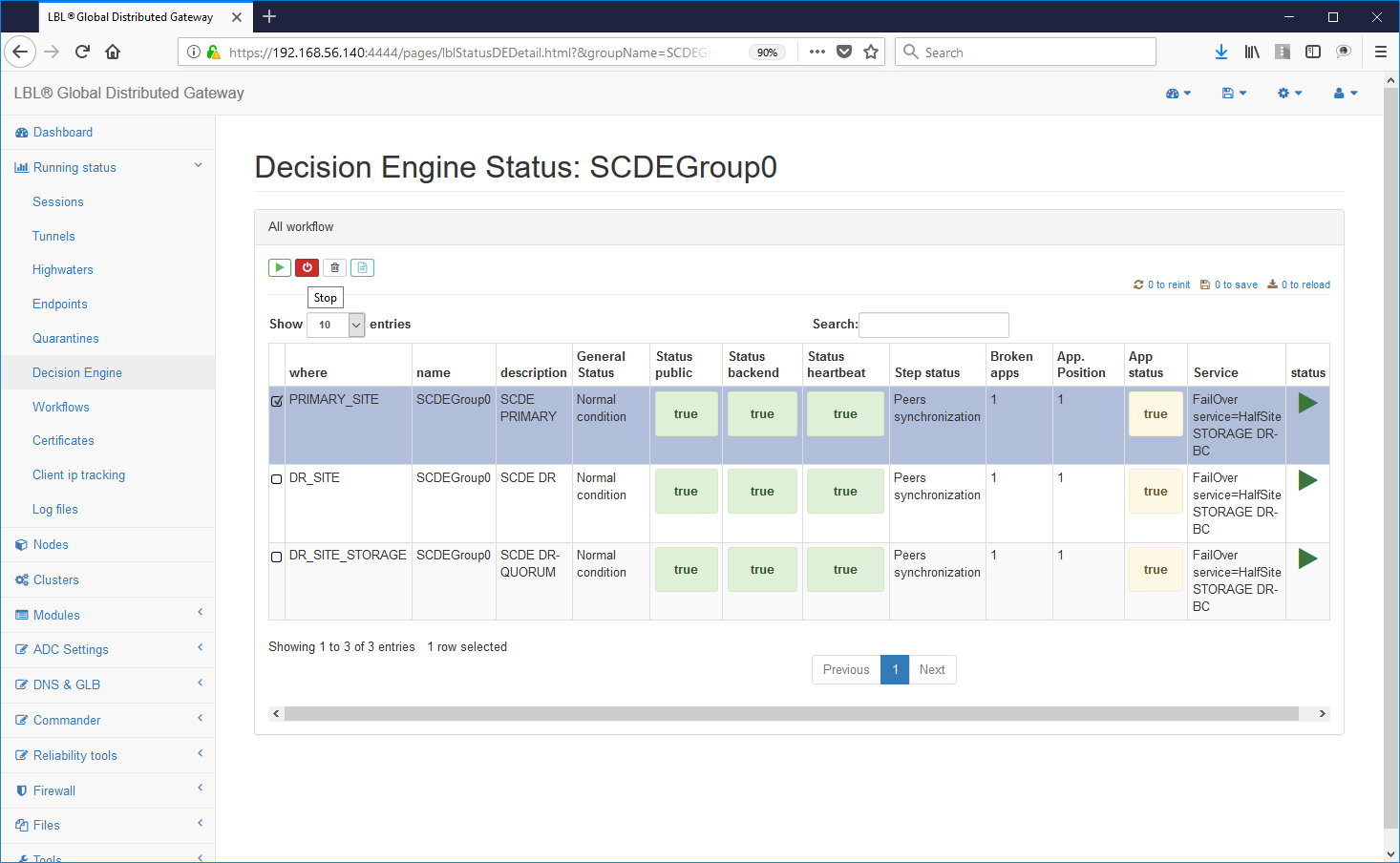
Lo stop dei motori decisionali non influisce minimamente con le istanze Oplon Commander Work Flow ed è quindi possibile in qualsiasi momento fermare i motori decisionali.
Fermando i motori decisionali è possibile gestire in maniera guidata attraverso le istanze Oplon Commander Work Flow le attività di ripristino senza dover intervenire direttamente sui nodi ma attivando le procedure (Work Flow) previste per il ripristino.
Dovendo ripristinare manualmente la situazione iniziale con Apache Tomcat in esecuzione sul nodo/sito principale una volta fermati logicamente i motori decisionali è sufficiente andare sul sito secondario ed effettuare le operazioni in senso contrario: gracefulShutdown dell'applicazione sul sito secondario e quindi takeControl sul sito principale.
Prima di effettuare le operazioni sui nodi/siti applicativi assicurarsi che tutte le istanze Oplon Commander Decision Engine relative al gruppo applicativo, SCDEGroup in questo caso, siano nello stato di STOPPED:
A questo punto una volta appurato che i motori decisionali per il gruppo applicativo sono stati posti in stato di STOPPED si potrà procedere con il ripristino della condizione iniziale.
Da questo momento in poi l'operatività è stata ripristinata da un punto di vista operativo.
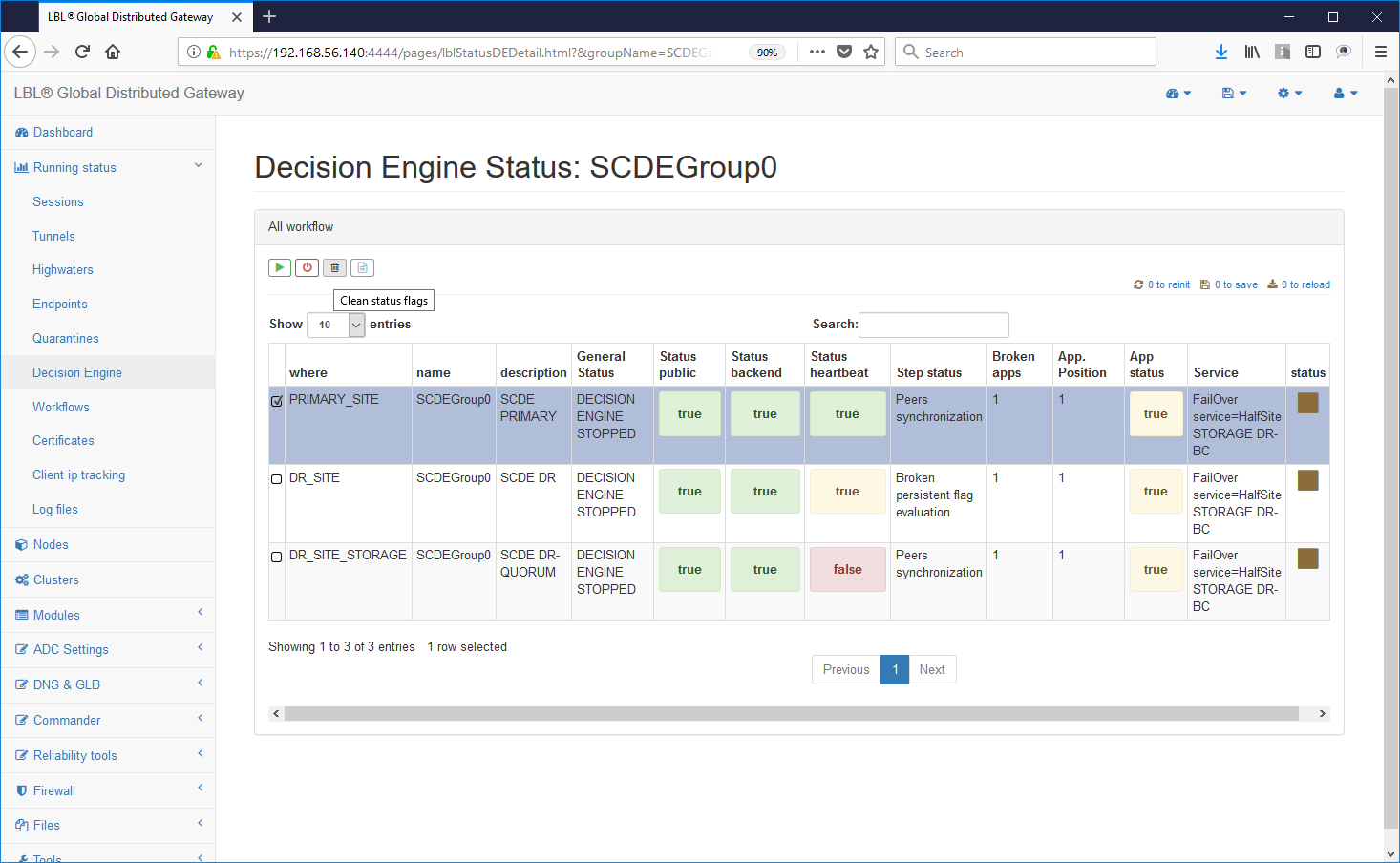
Ci resta solo da riportare i motori decisionali in uno stato utile al prossimo evento di failure... Ritornando sulle istanze Oplon Commander Decision Engine fermate all'inizio del processo di ripristino si noterà che sulla destra è stata resa disponibile una X. Questo pulsante serve ad eliminare tutti i flag persistenti di indicazione di failure sui nodi/sedi. Eseguire il clean dei flag di persistenza su tutti i nodi Oplon Commander Decision Engine.
La situazione dovrebbe apparire in tutti i nodi nella seguente situazione: 0 BrokenApps e il pulsante X non più abilitato. ATTENZIONE: Accertarsi che tutti i motori decisionali siano stati ripuliti dei flag di persistenza. I flag di persistenza vengono propagati automaticamente su tutti i nodi e quindi nel caso ne permanga anche sono uno nei tre nodi Oplon Commander Decision Engine anche tutti gli altri nodi all'avvio lo erediterebbero causando un nuovo "takeControl" del sito secondario.
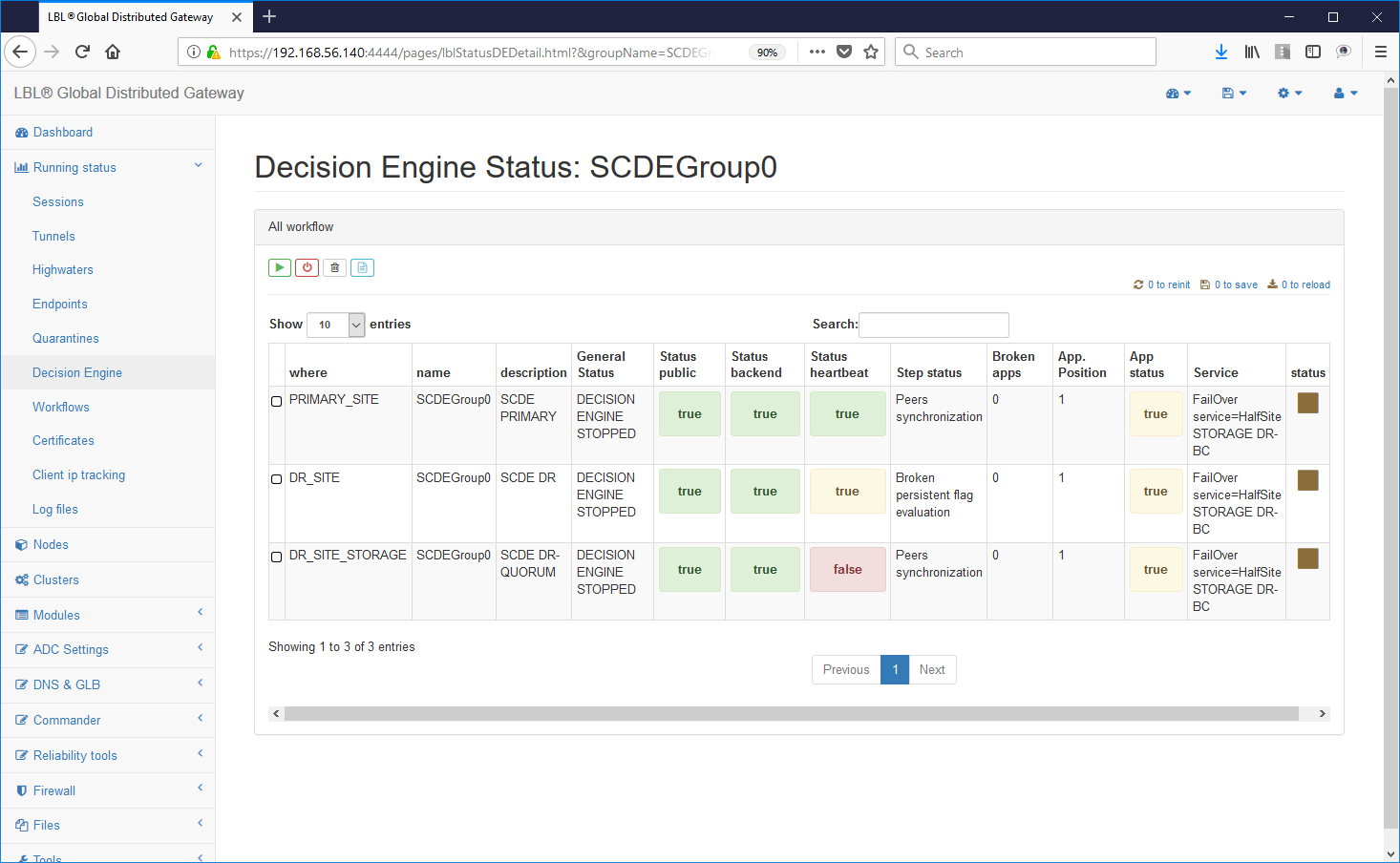
Una volta appurato che tutti i nodi Oplon Commander Decision Engine sono allineati dal punto di vista flag di persistenza (a zero) è sufficiente riavviarli senza un particolare ordine di avvio...
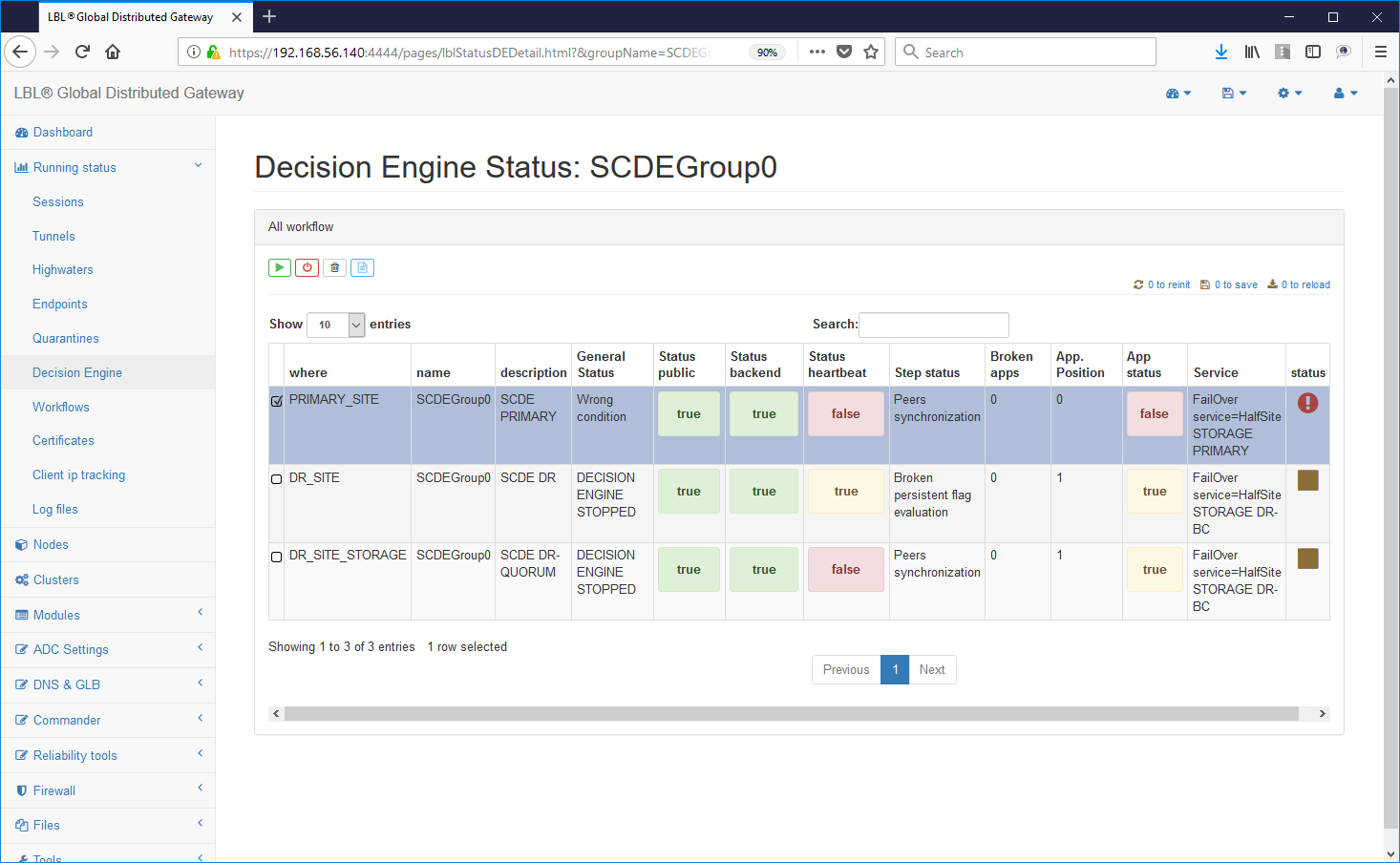 Dopo lo start del primo motore decisionale
si avrà una Wrong Condition determinata dal fatto che è il solo
motore decisionale operativo...
Dopo lo start del primo motore decisionale
si avrà una Wrong Condition determinata dal fatto che è il solo
motore decisionale operativo...
Già da questo avvio però viene rilevata l'operatività delle applicazioni sul sito principale...
Avviando quindi il secondo motore decisionale si ripristinerà la situazione in cui i motori sono in grado di prendere delle decisioni autonome...
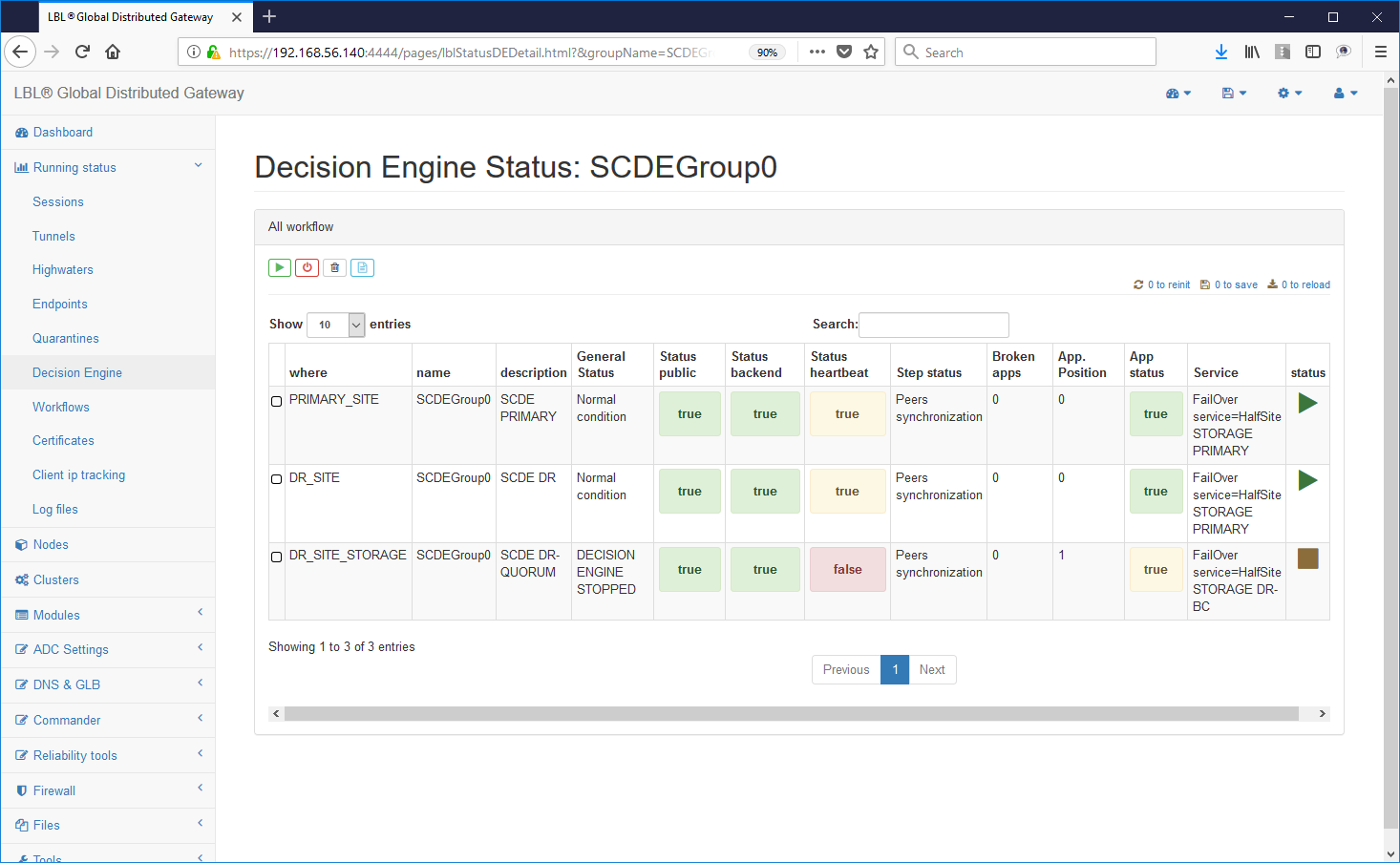
Lo stato dell'HeartBeat di colore giallo indica che non tutti i motori decisionali sono operativi ma che già da questo momento le due istanze possono prendere delle decisioni autonome...
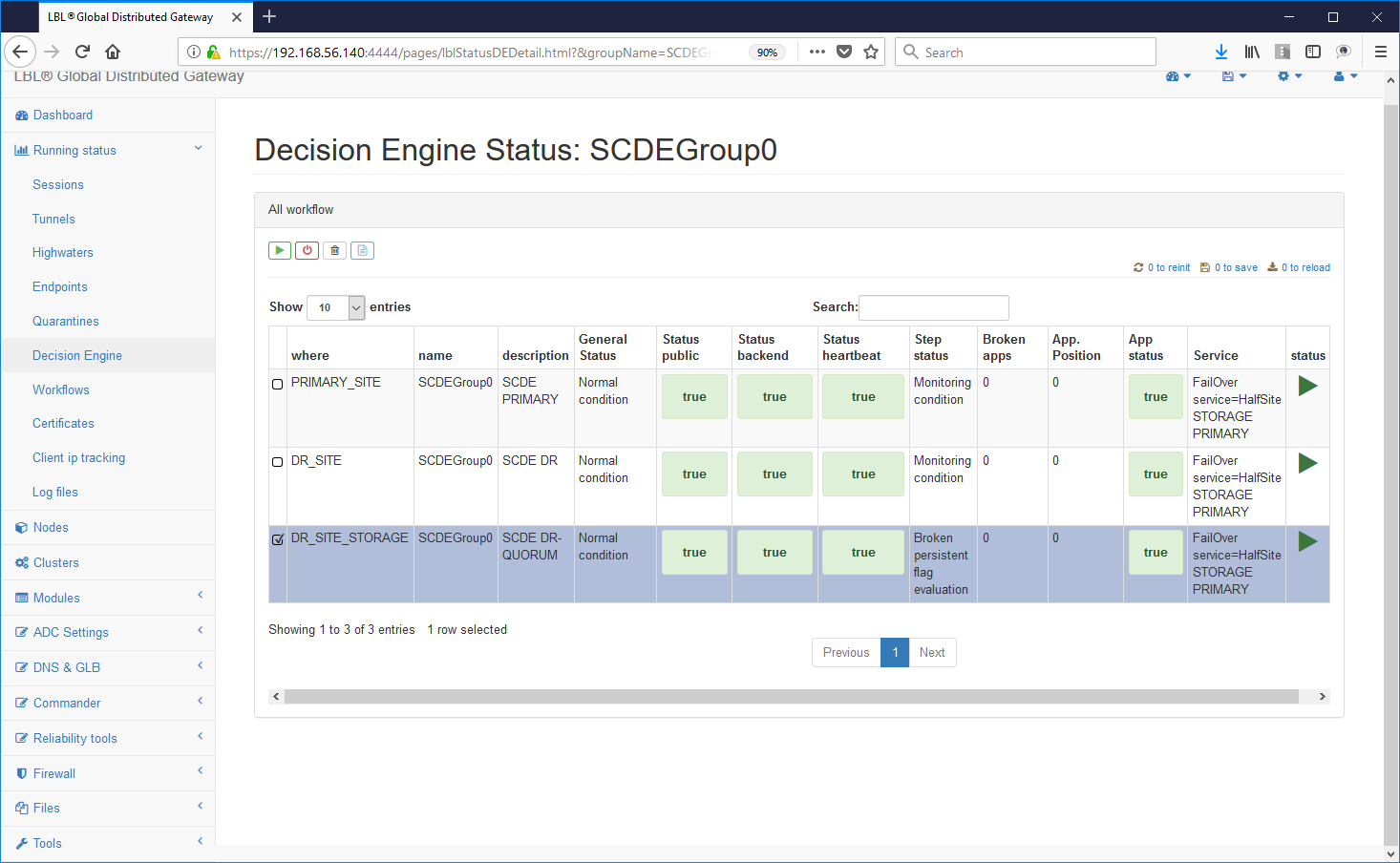
Lo start anche del terzo motore decisionale riporta tutto allo stato
iniziale...
Oplon Commander Restart phase
Dalla release 7.1 Oplon Commander Decision Engine gestisce una fase intermedia tra la rilevazione dell'avaria e lo switch in un altro nodo/sito dell'operatività. Questa fase intermedia, opzionale, comanda un Restart per verificare se con un intervento meno invasivo dello switch over si riesce a ristabilire il funzionamento originale.
Questa fase è stata introdotta verificando sul campo che molto spesso è sufficiente un restart degli application server o del Database, o di entrambi, per risolvere i problemi che si erano manifestati.
L'implementazione di questa fase prevede come prima cosa lo sviluppo dei Workflow di restart e quindi la loro impostazione sui motori decisionali.
- Sviluppo del Workflow di Restart
Lo sviluppo del Workflow di Restart prevede di eseguire uno stop "graceful" dell'ambiente operativo con successivo start al termine del quale si verificherà nuovamente l'operatività applicativa complessiva. Questa fase è contraddistinta da due importanti considerazioni, la prima è sicuramente che il restart non sia già stato eseguito in un momento relativamente vicino per non innescare restart a catena, l'altra considerazione è quella di eseguire comunque un fail-over se tutte le procedure di restart non fossero andate a buon fine.
La soluzione per non innescare restart a catena è molto semplice da implementare in quanto in uno Step di Oplon Commander Work Flow è possibile impostare un'attesa prima di eseguire lo Step. Con questo parametro è sufficiente inserire un'attesa nell'ultimo Step del Workflow di Restart per non incorrere in restart multipli. Il calcolo del tempo di attesa prima di rendere disponibile nuovamente il Workflow ad un altro eventuale comando di Restart deve essere effettuato come di seguito:
La formula è ovviamente orientativa e tende ad evidenziare che il tempo totale di attesa nell'ultimo Step di un Workflow di Restart deve essere superiore al tempo di attesa della promozione del fail-over su altro nodo/sito. Utilizzando questo semplice accorgimento si è sicuri di non incorrere in Split Brain causati dallo start contemporaneo delle applicazioni sui due siti e si è anche sicuri di non incorrere in Restart multipli a catena di una applicazione ormai compromessa.
Si può allungare il tempo totale di attesa nell'ultimo Step a piacere. Se ad esempio l'applicazione che si vuole verificare richiede normalmente un restart ogni due giorni, si può dedurre che provocare un ulteriore Restart a causa di rilevazione di malfunzionamenti nell'arco delle 6 ore successive al precedente Restart possa essere considerato come un problema al "sistema" e non all'applicazione.
Al rilevamento di un ulteriore evento di failure e conseguente comando di Restart, ad opera dei Server Oplon Commander Decision Engine, nella finestra temporale delle 6 ore dal precedente Restart, essendo il Workflow ancora in attesa nell'ultimo Step non verrà ulteriormente eseguito. Scaduto il tempo di lease, impostatto in Oplon Commander Decision Engine, della dichiarazione di failure applicativa verrà promosso il fail over su un altro nodo/sito.
Per sviluppare il Workflow di Restart è probabilmente sufficiente utilizzare parte degli Step del Workflow di gracefulShutdown e parte degli Step del Workflow normalPrimer evidenziando maggiormente la riusabilità dei moduli di script precedentemente creati.
Negli ultimi Step, normalmente normalEnd o abEnd sarà sufficiente inserire il parametro waitBeforeExecute="21600000"
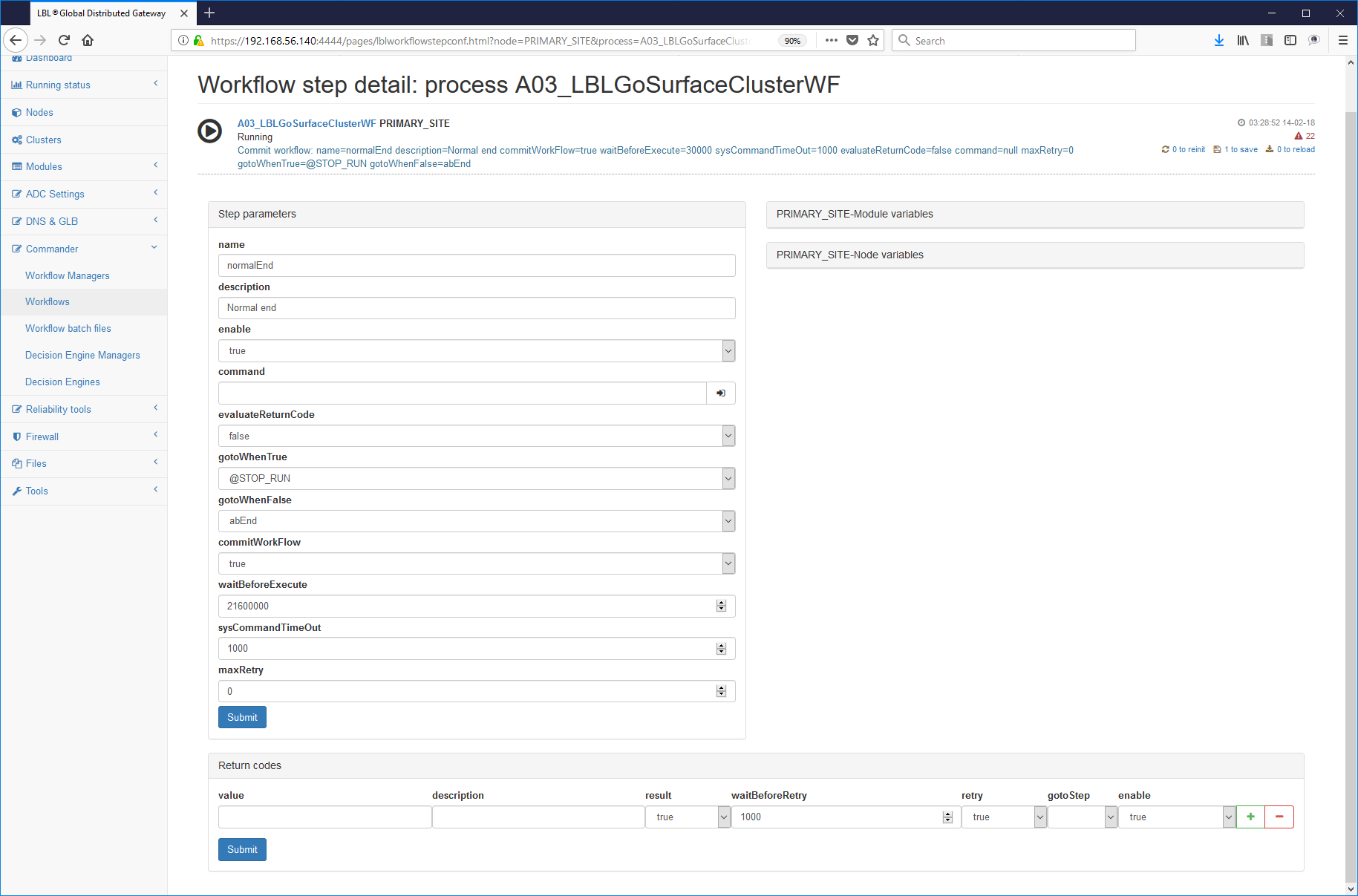
- Impostazione del Restart in Oplon Commander Decision Engine
L'impostazione della fase di Restart nei parametri dei motori decisionali è molto semplice perché aggiunge solamente i nuovi parametri applicationLostTimeBeforeRestart e restartWorkFlow rispettivamente il tempo di lease tra la rilevazione dell'avaria e il momemnto del Restart ed il nome del Workflow di Restart da richiamare. Di seguito un frammento di file parametri surfaceclusterde.xml (per maggiori dettagli vedere il documento di Reference Guide):
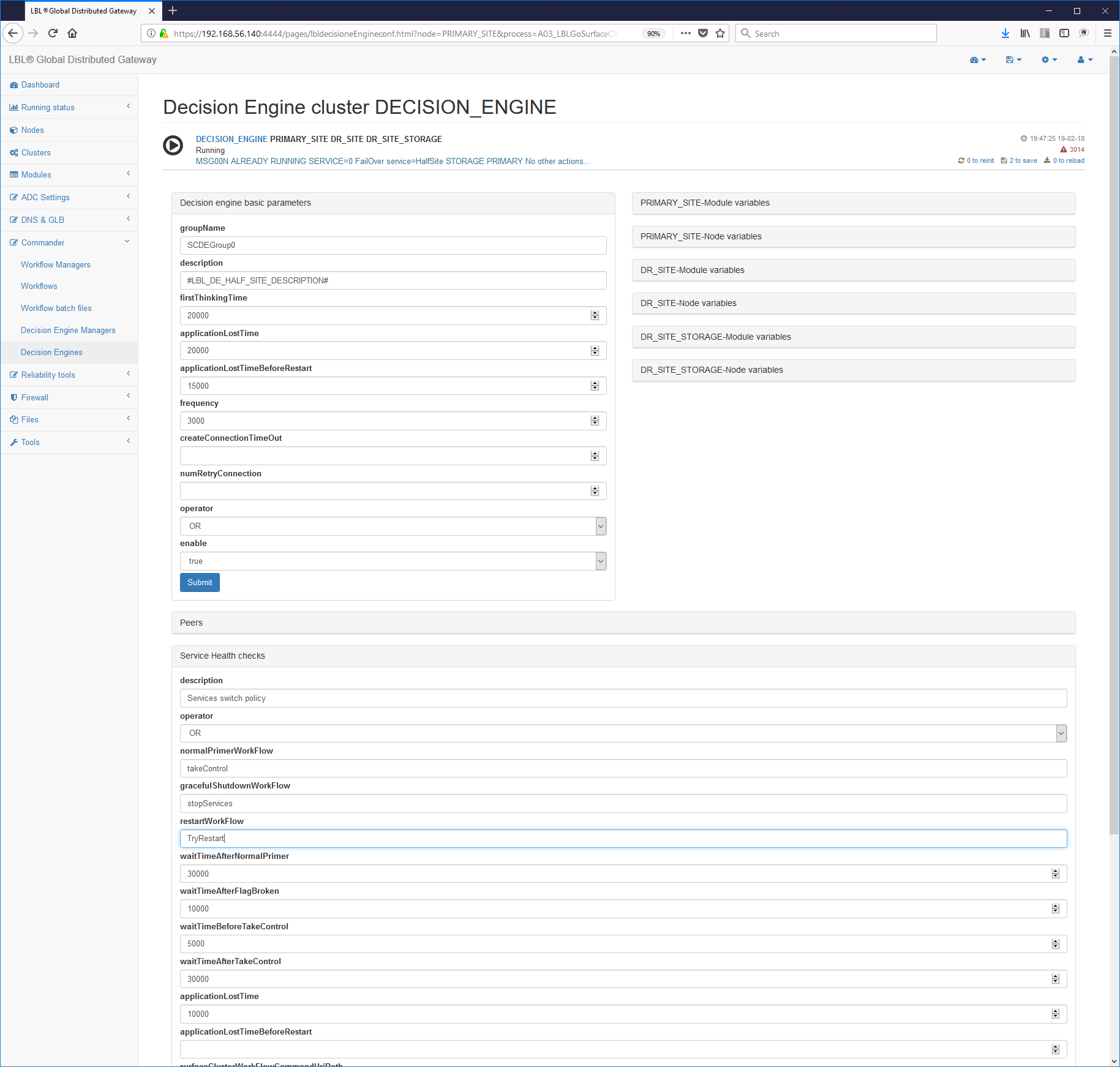
Oplon Commander Decision Engine Split Brain Assassin
Questo servizio gestisce, in ambienti cluster distribuiti e paritetici (stretch cluster), eventuali possibilità di Split Brain.
Oplon SCDE Split Brain Assassin ha pochissimi parametri ed è quindi utilizzabile con grande semplicità. Semplicità necessaria in questi casi.
Di norma Oplon SCDE Split Brain Assassin sarà configurato nei nodi che hanno le istanze Oplon ADC. Questo perché lo scopo principale di Oplon SCDE Split Brain Assassin è quello di notificare allo strato ADC di escludere l'accesso ad alcuni servizi fino ad escludere l'intero traffico eliminando ogni possibile interazione con il backend.
Il servizio Oplon SCDE Split Brain Assassin sarà attivato per ultimo, dopo aver installato e configurato lo strato di bilanciamento Oplon Commander Decision Engine, Oplon Commander Work Flow e provato tutto l'insieme. Solo allora si valuterà la possibilità di Split Brain geografici, vedi Oplon White Paper per una esaustiva spiegazione, e si procederà con l'installazione e avvio di Oplon SCDE Split Brain Assassin.
I passi necessari per la configurazione di Oplon SCDE Split Brain Assassin sono così sintetizzati:
1- Verificare che sia stata impostata la licenza d'uso Oplon Commander Decision Engine
(LBL_HOME)/lib/confSurfaceClusterDE/license.xml
2- Impostazione del file di configurazione del servizio
(LBL_HOME)/lib/confSurfaceClusterDE/splitbrainassassin.xml
Ci sono due paragrafi principali, il primo è, come di norma, il
paragrafo <params>. Questo paragrafo definisce i comportamenti
generici come la frequenza di HealthCheck e alcuni parametri di default.
Per prima cosa bisogna identificare i bersagli motivo di health check. Questi bersagli vengono facilmente identificati nei due nodi Oplon SCDE, il paritetico ed il Quorum. Oplon SCDE Split Brain Assassin solamente in mancanza di entrambi i bersagli (o tutti i bersagli se più di due) notificherà l'evento critico a Oplon ADC tramite impostazione dei file di notifica.
Oplon SCDE Split Brain Assassin può essere impostato per notificare a Oplon ADC una completa disconnessione di tutti i servizi, attraverso l'eliminazione degli indirizzi virtuali, oppure per escludere solo parte dei servizi interessati all'evento.
Esempio del file di configurazione: splitbrainassassin.xml
<splitbrainassassin>
<params
frequency="10000"
createConnectionTimeOut="4000"
numRetryConnection="3">
</params>
<decisionEnginesPeers>
<peer enable="true"
description="Sys 001"
URL="<https://peerOne:54445/>" # Modificare
healthCheckUriPath="/HealthCheck?decisionEngine=SCDEGroup"/>
<peer enable="true"
description="Sys 002"
URL="<https://peerTwo:54445/>" # Modificare
healthCheckUriPath="/HealthCheck?decisionEngine=SCDEGroup"/>
<notification
fileName="lib/notificationDir/outOfOrder.systemsMonitorGroup"
description="All vips"/>
<notification fileName="lib/notificationDir/outOfOrder.gr1"
enable="false"/>
<notification fileName="lib/notificationDir/outOfOrder.gr2"/>
<notification fileName="lib/notificationDir/outOfOrder.gr3"/>
<notification fileName="lib/notificationDir/outOfOrder.gr4"/>
</decisionEnginesPeers>
<sysobserver>
<service name="syslog" id="syslogsplitbrainassassin"/>
</sysobserver>
</splitbrainassassin>
</serviceconf>3- Eseguire lo start del processo e verificare i log:
3- Impostazione lo start automatico del servizio
(LBL_HOME)/lib/confMonitor/A03_LBLGoSurfaceClusterWFRemoteBatch.xml
<A03_LBLGoSurfaceClusterDESplitBrainAssassin>
<process enable="true"
description="LBL(r)Commander Split Brain Assassin"
start="automatic" -----> Modificare da "manual" ad "automatic"
numberTryStartOnFailure="-1"
waitBeforeKill="60000"
waitBeforeKillOnFailure="10000">
<start osName="Windows">
<env>CLASSPATH=.;lib;libLBLADC.jar</env>4- Eseguire la stessa operazione negli altri nodi di bilanciamento...
NOTA:
Per avere un test più attendibile è possibile aggiungere degli HealthCheck su altri servizi. A questo scopo nell'esempio di seguito si è provveduto a verificare anche un servizio di HealthCheck offerto da Oplon Commander Work Flow Remote Batch.
<peer enable="true"
description="Sys 002"
URL="<https://peerTwo:54445/>"
healthCheckUriPath="/HealthCheck?decisionEngine=SCDEGroup"/>
<peer enable="true"
description="Sys 002"
URL="[https://peerTwo:5994/](https://peerTwo:54445/)" <--- Modificare
healthCheckUriPath="/RemoteBatch/startBartch.xml"/> <--- modificare