Continuità operativa: introduzione alla Business Continuity e Disaster Recovery
Il tema della continua erogazione dei servizi IT viene normalmente chiamata con due termini: Business Continuity (BC) e Disaster Recovery (DR). In alcune circostanze la Business Continuity viene anche sostituita con il termine Continuità Operativa, che sta ad indicare servizi di pubblico interesse e quindi non legati al business.
Business Continuity e Disaster Recovery, quali sono le differenze?
Nel tempo, queste due tipologie di continuità dell’erogazione dei servizi sono state descritte nelle più disparate e fantasiose maniere. In realtà la differenza tra queste due terminologie è funzionale.
La prima domanda che ci dobbiamo porre nell’intraprendere una delle due alternative o propendere per la scelta di entrambe è la seguente:
Il sistema di servizi dell’azienda/ente che vogliamo salvaguardare termina con la cessazione del sito operativo da cui i servizi vengono erogati?
Se la risposta è sì, il tipo di continuità operativa da intraprendere è la Business Continuity, se la risposta è no, il servizio avrà necessità di una continuità operativa in un sito geograficamente distante dal principale del Datacenter per garantire l’erogazione dei servizi. In quest’ultimo caso si parlerà di Disaster Recovery.
Business Continuity
La soluzione di Business Continuity deve avere comecaratteristica principale la vicinanza al sito di produzione del servizio perché sia efficace, oltre a dover prevedere due luoghi distinti, ma vicini, come ad esempio lo stesso edificio (separato opportunamente all’interno da pareti tagliafuoco, doppie alimentazioni elettriche e connettività), o due palazzine distinte. La cosa importante a cui fare attenzione è la vicinanza del servizio operativo perché anche in assenza di connettività esterna dei telco operator (fornitori di connettività), deve essere sempre possibile raggiungere almeno uno dei due datacenter.
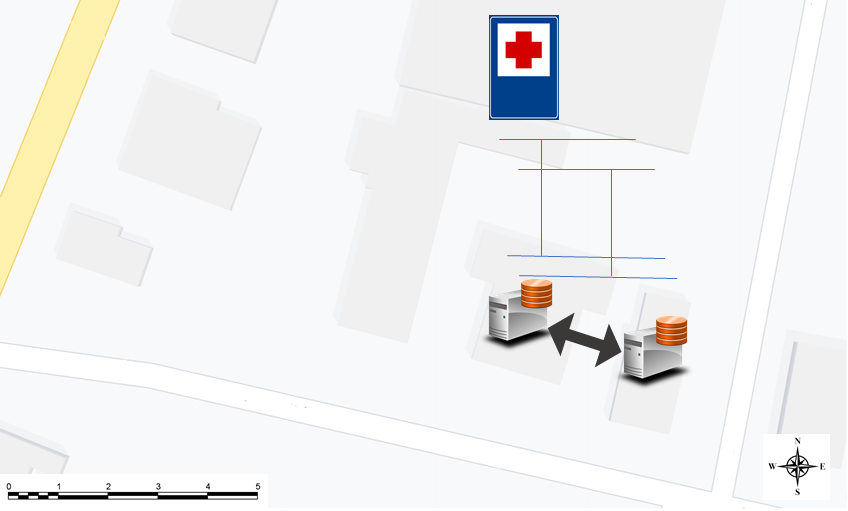
Disaster Recovery
Per attività che richiedono servizi di continuità di Disaster Recovery, i due datacenter devono avere una distanza minima che comunemente è stata stimata in circa 70 km. Questa è la distanza che permette, nella maggior parte dei casi, di salvaguardare le infrastrutture come purtroppo già testato a seguito di eventi naturali o innescati dall’uomo (terremoti, la centrale nucleare di Fukushima dopo lo tsunami del 2011, Chernobyl nel 1986, la cui zona interdetta ancora oggi copre un raggio di 40 km, etc).
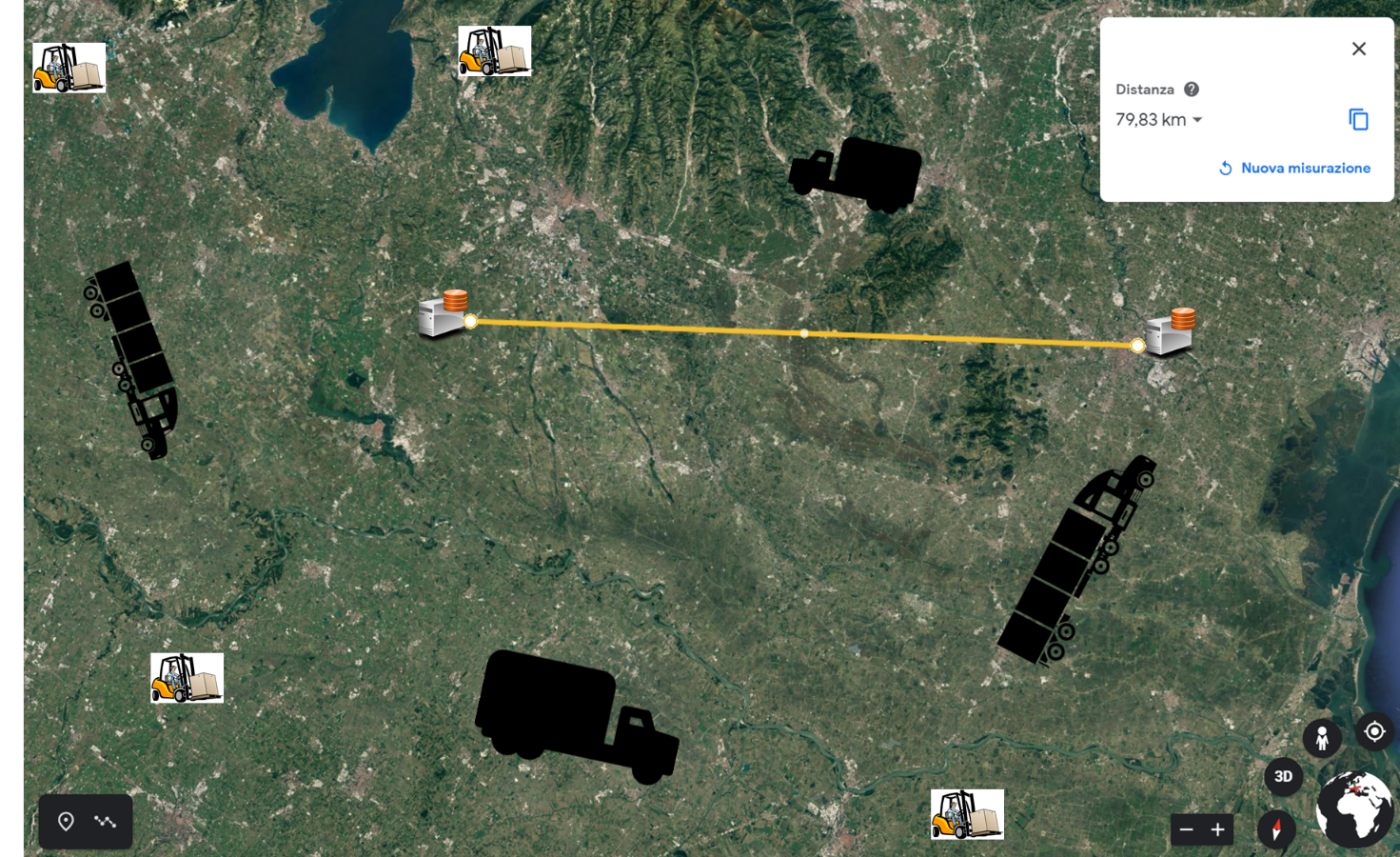
Esempi di Business Continuity e Disaster Recovery: un Pronto Soccorso Ospedaliero e un Corriere internazionale
Partendo da un esempio, possiamo ipotizzare un servizio ICT per un pronto soccorso ospedaliero ed un servizio ICT per un corriere internazionale.
Se si dovesse verificare un evento tale da rendere totalmente inagibili i locali di un pronto soccorso ospedaliero, come un allagamento, terremoto o altro avvenimento, con conseguente non accesso alla struttura da parte dei sanitari, l’alternativa per gli utenti sarebbe rivolgersi ad un altro pronto soccorso nelle vicinanze.
**In questo caso avrebbe poco senso riattivare i servizi informatici del pronto soccorso in un sito dislocato in un’altra area,mentre una buona resilienza locale dei servizi informatici (Business Continuity) permetterebbe una continuità operativa anche in assenza di connettività esterna essendo il Pronto Soccorso sopravvissuto all’evento.
Nel secondo caso consideriamo un Corriere internazionale, dove nell’eventualità di una problematica tale da rendere l’headquarternon più operativo o irraggiungibile, non si dovrebbe riscontrare un disservizio tale da compromettere le filiali, magazzini e la logistica in generale che dovrà assolutamente restare operativa indipendentemente dal sito principale. In occasioni come quest’ultima, il sito di Disaster Recovery posto a debita distanza, tipicamente dai 70Km in su, è assolutamente indispensabile per la continuità di erogazione dei servizi.
Solo dopo aver risposto a questa domanda, ci si può interrogare sul Recovery Time Objective (che individua la velocità a cui si è in grado di ripristinare i sistemi informatici); sul Recovery Point Objective (che individua la perdita di dati ammissibile); latenze (tempo di risposta), throughput (capacità di trasmissione utilizzata) e quant’altro necessario alla realizzazione della continuità operativa in circostanze particolarmente critiche.
Cloud & Datacenter per la continuità operativa
Quando si parla di Datacenter s’intendono sia datacenter di proprietà ma anche strutture i cui spazi vengono affittati proprio per garantire Business Continuity e Disaster Recovery. Questi possono essere cloud di mercato oppure Datacenter specializzati nel fornire servizi atti a garantire questa continuità operativa. Nella valutazione dell’opportunità degli uni e degli altri, entrano in gioco diversi fattori tra cui i costi.
In entrambi i casi è da valutare un’attenta gestione delle copie di sicurezza dei dati.
La progettualità per un piano di Business Continuity e Disaster Recovery
Nell’affrontare un progetto di Business Continuity o Disaster Recovery è necessario effettuare alcune considerazioni: in questo documento introduttivo andremo ad evidenziare i temi che in entrambi i casi si devono tenere in considerazione e una lista di priorità di azioni da effettuare per predisporsi al progetto:
- Censimento dei punti di ingresso dei servizi
- Censimento dei server applicativi che abilitano i servizi
- Censimento delle basi dati strutturate
- Censimento delle basi dati non strutturate
Di seguito un’immagine che sintetizza in maniera visiva gli strati che le richieste di servizio, rappresentate dai nastri colorati, devono attraversare per poter soddisfare le richieste in un tipico Datacenter.
Il passaggio da un Datacenter a più Datacenter con replicazione dei dati e la possibilità in momenti critici di operare dal datacenter secondario, deve essere accompagnata da strumenti che ne facilitano le operazioni e le rendano il più possibile automatiche.
Ogni strato citato necessita di procedure e strumenti per permettere la migrazione dei servizi da un Datacenter ad un altro, in maniera totale o anche parziale. Altro elemento importante è il test che deve essere effettuato periodicamente per poter essere sicuri che nel momento critico tutte le procedure siano state aggiornate e siano operative.
Tutti i vendors nei singoli strati, produttori di web/application server, database, storage etc. propongono normalmente una loro soluzione per realizzare la singola funzionalità. Servono quindi strumenti per orchestrare le attività e predisporre i servizi ad essere eseguiti in sedi secondarie.
Strumenti per predisporre i servizi in un datacenter:
Uno degli strumenti indispensabili su cui si basano tutte le politiche di Business Continuity e Disater Recovery è **Oplon Application Delivery Controller (ADC).**Questo elemento infatti, concentra il catalogo dei servizi ed è quindi il punto di ingresso per ogni richiesta che venga eseguita al Datacenter. Nel caso di Disaster Recovery entra in gioco anche Oplon DNS Global Load Balancerche permette di cambiare dinamicamente le risposte del DNS in base alla localizzazione del servizio. È in grado quindi di indirizzare le richieste sul sito principale o sul sito secondario che risponde ad un indirizzo IP differente perché posizionato in un’altra area geografica.
Conclusioni
Abbiamo appena cominciato un lungo cammino sulle politiche di continua erogazione dei servizi.
Volutamente abbiamo impostato la discussione iniziale sugli aspetti generali che devono guidare ad una scelta consapevole degli strumenti più adeguati alle necessità, basati sul tipo di servizio da mettere in protezione.
Seguiranno ulteriori approfondimenti sul tema, andando ad analizzare più nel dettaglio i singoli punti con le varianti architetturali che si possono adottare.